AI-Cortex
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 entry.jpg)
| CorID | WordID | Entry1ID | Entry2 | LinkID |
| 62781 | 52252 ("kind") | 30090 (adj.) | ||
| 62782 | 52255 ("kinder") | 62781 | 30091 | |
| 62783 | 52262 ("kindest") | 62781 | 30092 |
When adding a WordID to the Cortex, syllabification and pronunciation entries are made in their respective tables.
The Cortex does not use a word without a POS. A word cannot be defined or used without knowing its POS, so there is no point in adding it to the Cortex without the POS, though I use POS loosely because it could be an abbreviation, a prefix, etc. (See the LinksType table.)
How to enter words into the Cortex will be discussed in depth under LinkType table, below.
Parts of Speech.
Following are the parts of speech used in AI-C. Some examples are shown below. For a complete list for each POS, press Ctrl-L to bring up the Links table, scroll down to the part numbers for parts of speech, double-click on one and click [Show Examples].
Nouns:
30010: noun (countable)
30011: noun feminine
30012: noun mass/uncountable (Some nouns are mostly uncountable but may have a plural form too.)
30013: picture noun
30015: noun plural - the plural form of 30010: noun.
30016: plural noun - a noun which has no singular form, only plural.
30017: noun feminine plural
30020: proper noun
30021: proper noun plural
Pronouns:
30030: pronoun - nominative case (subject of sentence): I, you, she, he, we, it, they.
30031: possessive pronoun - the genitive case: my, your, his, her.
30032: possessive pronoun, predicative - a possessive pronoun used without the noun: his, hers, mine, ours, theirs, yours.
30033: pronoun plural - we, you, they, these
30034: pronoun, objective case (obj. of verb): me, you, him, her, us, them, it
30035: pronoun plural objective case: us, you, them
Maintenance fields.
Tables in AI-C have a Tag field which can be used by software to mark fields for later review, normally by a human. For example, run the subroutine FindDiffPrns to tag different pronunciations of the same word and the Tag will be used to mark such entries.
Another maintenance field in the Pronunciation table is Ver which is used to indicate that a pronunciation has been verified. Computed pronunciations can be wrong because rules are not guaranteed to apply to all words, so knowing that a pronunciation has been verified is helpful in choosing between two pronunciations, computing new pronunciations, etc.
You can delete those fields (or add others) if you wish, because...
Cortex flexibility.
There is NOT just one way of doing things in the Cortex. Normally, the Cortex does not use a word without a POS, but that's just the way I am doing it now. A programmer could write a routine using particular LinkTypes which link to text without POS's. Likewise, there may be many different ways to link related Cortex entries together. When linking two entries, many times it does not matter significantly which entry is in the Entry1 and which is in the Entry2. And in the long run, the AI-C itself will likely reorganize links for optimum efficiency anyway.
AI-C has what is probably the simplest possible database design (just five essential fields in the main table) and is available in the simplest possible formats (Access2007 or straight ASCII) with which you (assuming you program) can do anything you want using any programming language you want. Even building off the existing database and software, it should easily be possible to add fields to tables, add tables to the database, and even add new databases to the project, then incorporate them into AI-C by adding new LinkTypes which let you write code for dealing with them.
Words table
- Word ID# - this is what links into the Cortex table.
- Text - presently set to allow up to 50 characters.
- Soundex - used for spell checking and making suggested corrections.
- Frequency - relative frequency with which a word is used in unspecialized speech and writing.
- Tag - a short field added for temporarily marking entries for various maintenance projects.
- Backwards - the word spelled backwards; used to find words ending with specific letters. Not essential.
- common: past tense of bind - "they were bound together"
- less common: adjective - "they were bound to arrive soon"
- rarely seen: verb (bound, bounds, bounding, bounded) - "watch the rabbit bound over the fence"
- jargon: noun - "upper bound of a range of numbers"
- common - basic words for which simpler equivalents are rarely available and which are most often seen in print.
- less common - most are just as widely known as common, but appear in print less often, and there are usually common words available which mean the same thing.
- rarely seen - rarely seen/heard. This has nothing to do with how well known a word may be, just how often it is used.
- jargon/names - mostly technical words normally used only in writings about a specialized subject; also proper nouns (names). Can also be words used only in a specific vernacular and not seen in general writings. Take the word aardvark: it is not a technical word, as such, but it is very rarely, if ever, seen in general use (except in countries where they live, possibly).
- taboo/vulgar - normally not used in public (except in movies, cable TV, on the Internet, etc.).
- archaic - may be known, but are rarely, if ever, used anymore.
- See POS entries - is for when different Parts Of Speech of the same word have different frequencies.
See other entries - is for when different Categories of the same POS have different frequencies.
See POS entries is in the Enter Word(s) Frequency list and See other entries is in the Entries Frequency list. - whimsical: Many English speakers likely know this word.
The accompanying scale shows "many" to be about 2/3rds. That seems a stretch, but possible. - blastulae: Most English speakers likely know this word.
The scale indicates that "most" is about 3/4ths. That seems ridiculous. - Look up the WordID# for hot in the Words table (#45018).
- Look for a Cortex entry with a WordID of 45018 with a LinkID# of 30911 (link to phrase).
- See if the number in the phrase's Entry1 ("2", in the example above) matches the number of words in the phrase for which you are searching. If not, then return to Step 2 to look for more entries.
The Entry2# in that entry will be the Cortex ID# of the phrase to which hot is linked. - Look up the WordID# for dog (#27858).
- Look for a Cortex entry with a WordID of 27858 with a Entry2 found in the other entry (209100, in this example).
Words table structure
Each record in the Words table consists of the following fields:
There are no duplicate entries in the Text field, although capitalization counts so that Ford (brand of a car) and ford (crossing a river) are NOT considered duplicates.
The index of text in the Words table cannot be set to "no duplicates" because with that setting, Access ignores case and would not allow two entries with the same letters but different capitalization. I tried following Access' instructions for making the database software ignore case, but their suggestions did not work for me. Therefore, before adding a word to the Words table, it is necessary to check to make sure it is not already there, since the database is set to allow duplicates even though we don't want them.
Similarly, if you check to see if a word is already in the Words table and the database engine says it is, check to make sure that the capitalization is the same. That is, if you search for "ford" and the Words table finds "Ford", it will tell you that a match has been found. If the case does not match, continue searching to see if it finds the word with matching case.
Many years ago I was writing an HTML editor (which, in fact, I am using to write this document) and wanted to add spell-checking. To do this, I searched the Web for word lists. I found a bunch, but they were all pretty junky. I compiled them, cleaned them up, ran them through other spell checkers, and ended up with a list of about 100,000 words.
When I (re)started this NLP project, I began with that list for the Words table, adding to it when needed and creating entries in the Syllables, Pronunciation, and Cortex POS tables. Not every word in the Words table was linked into the Cortex. Eventually, unused words were removed from the Words table.
Common misspellings can be included in the database and linked to the proper spellings with a LinkType of misspelling. A spelling corrector added to the AI-C Lookup program in mid-2010 has proven to be so accurate that it almost always can find the intended word from any normal types of misspellings, so the entries for misspellings are probably not necessary.
In the late 1980's, I wrote an English-Spanish dictionary by the name of Ventanas: Spanish For Windows. (I guess that was my attempt at being clever since for you non-Spanish speakers, the word ventanas is literally the Spanish word for windows. And at the time the program was written, many Windows programs were identified as being for Windows since Windows was still relatively new.)
As of March 22, 2010, I had not looked at Ventanas for a long time, so I tried running it under Windows 7 and the program still runs (in Visual Basic 3). Looking at it again was funny because I had absolutely no recollection of how it was designed, so it was like looking at someone else's program. In the late 1990's, I wrote an updated version of the software (using the same basic database of words) that listed categories, synonyms, and more.
The programs have some interesting features, such as showing POSs, style, synonyms for both the English and Spanish words, other translations of the word in each language, words/phrases with the word's root, and full conjugations of verbs. But the most interesting feature of all at this time is the ability to export all the data to a text file, which will allow me to import it into AI-C at some point (but not right now). It was also of interest to be able to see where I was with this kind of project so many years ago.
The fact that Ventanas' database has a pretty long list of English words in it makes me think that this may have been my original database of words for AI-C, contrary to what I said above, though I have no memory of it. Ah, well. Not having a memory is what keeps things fresh! (In case it's not obvious, I'm kinda old.)
Where to put names and other languages:
I had intended to put proper names and vocabularies of other languages into separate tables. It just seems cleaner to have them this way rather than mixing everything into the Words table. However, I've been experimenting with the Lookup code to see how it works with an unlimited number of separate tables and it is basically a mess since each table has to be searched individually and it is easier to get unwanted duplicate entries for the same text (such as a person's last name and a company name).
So it appears that there is little choice but to put all text into the Words table.
Prefixes and suffixes
Entries for common Prefixes and Suffixes are included in the Words list and are given a prefix or suffix POS link entry in the Cortex. I debated doing this, but decided it might prove useful and couldn't really hurt, particularly for prefixes like un- and non-, which can be used with hundreds (if not thousands) of words to make new words. Actually, any kind of bits of text (such as other parts of words) can be stored in the Words table for use by the Cortex.
In addition to the above, the Lookup program, as part of its spell checking, uses a subroutine (FindAffixes) which looks for common suffixes and prefixes on "words" entered which are not in the Words table. It then suggests, based on the affixes found, what might have been the intended meaning of the word entered. For example, if "wiseful" is entered, the suggested correction is "very wise". (The comic strip Get Fuzzy is a mother lode of such words.)
Hyphenated words
Common word combinations are called compounds. (See this web page for more information.)
Two words can be connected with a hyphen, such as water-soluble powder and time-limited offer, and the word pair cannot be found in most dictionaries. Although hyphenated words may be stored in the Words table, it is more efficient to store the individual words and link them in the Cortex with a Link of "- (hyphen)".
Verb forms
Verb forms, such as past tense, present participles/gerund, and 3rd-person singular, have been included in the Words table, even though the book Speech and Language Processing, considered by many to be the Bible of NLP, says: the idea of listing every noun and verb [form] can be quite inefficient.
While it is true that space could have been saved by using rules for regular word forms instead of entering all the forms, the Words table is very small relative to what the Cortex will ultimately become.
Having all noun, adjective, and verb forms in the Words table should simplify (and thus speed up) parsing sentences and finding words, which is far more important than saving a little disk space.
Here's an example: What is the present tense word for the past tense word:
indebted?
.
.
.
.
Of course, indebted is not a verb at all; it is an adjective. But you probably had to pause a second or two to think about it. Because many words ending in -ed are past-tense words which can also be used as adjectives, you cannot simply dismiss the possibility immediately that it may be a verb.
This is the type of uncertainty and loss of processing time which can be avoided by putting word forms in the database, even though our brains, not having the unlimited storage capacity as computers have, undoubtedly use rules for regular verb forms rather than storing each form (although it can do both if needed).
In his book, Words And Rules, Stephen Pinker commends his spelling checker for storing only the roots of words and computing the other forms. What Pinker does not point out is that this can lead to erroneous input being accepted. Pinker gives the example that if his document contains the word frustration, the speller will start with frustrate, drop the e and add ion and decide that frustration is a good word.
But say that I mistype the word compilation as compiltion. His speller will start with compile and following the steps above (drop the e, add tion), end up with compiltion and say that my misspelled word is okay. Storing all the verb forms for all the words eliminates such false positives.
Another problem with storing only the stems and using rules to form noun/adjective/verb forms is that there are so many exceptions to the rules. After making the statement that the idea of listing [storing] every noun and verb form can be quite inefficient, the Speech and Language Processing book spends a lot of space figuring out how to write rules for creating word forms and dealing with exceptions, which is VERY inefficient compared to the miniscule disk space used to store all forms.
On the other hand, English has relatively few verb forms. For languages which have large numbers of verb forms, it would probably be more practical to use rules rather than to store all possible word forms. Also, rules can be used to form verb forms for words which are not normally verbs, such as proper nouns.
AI-C also has the syllabification and pronunciation of all verb forms, which is not the case in major online or printed dictionaries (as of March 2018).
Noun plurals have also been included. The easiest way to add a plural is to load the singular form into the New Entry boxes which will cause a button to appear which says to make a plural. Click it then save the new entry. This will also compute and save new pronunciation and syllabification entries.
In some cases, a noun may only have a plural form; if so, there would obviously be no link to a singular form in the Cortex. It would link only to the WordID in the Words table with a LinkType of Plural Noun.
Another case is that a noun may have two (or more) different plural forms. Some nouns may appear to be plural (ending in "s", for example) but use singular verbs and vice versa. Some singular nouns may take either a singular or plural verb.
Finally, some singular nouns use the same form as their plural, such as aircraft, deer, species.
The Links table also has codes for masculine and femine nouns for languages like Spanish which normally have different forms for each. Look at the Links table for other noun forms.
Errors, ambiguities, and vagueness
Even large, big-name dictionaries have errors, inaccuracies, ambiguities (see the Random House definition at the end of this document), and inconsistencies in them. In the course of this project, I have found hundreds and hundreds of basic errors (i.e.: typos, circular references, etc.) in such sources. (See Dictionary Errors.) This is understandable as these are very large works assembled by humans, and we all make mistakes. Unlike a computer database, dictionary publishers have no automatic way to enforce consistency or to verify accuracy.
The Cortex database may also have errors in it, having been created by humans (giving myself the benefit of the doubt), but with the difference that unlike printed dictionaries, the database can easily be corrected and over time, errors winnowed out. I have also written numerous routines which the computer can run to look for and correct some types of errors.
But even if errors get into the Cortex, it doesn't mean that they will be used. Before the Cortex can be used for NLP, such software will have to parse documents, wiki's, etc., and translate such text into linked concepts in the Cortex. Once the Cortex hits a critical mass, new text will be understandable to AI-C by examining links in the Cortex. If a word or link is incorrect, it will probably never become interlinked with the rest of the Cortex, so it will never be used; or if used and is recognized by a human as wrong, it can easily be corrected.
One likely source of errors is in the plural forms of nouns. I hand entered some plurals and monitored the program as it created plurals for a few hundred words in order to test the algorithms, but eventually I had to turn it loose to create as there were about 50,000 words (most of them unusual ones) which needed plurals and it would have taken forever if I didn't let the software do them. Even at that, the software would stop to ask how to handle a particular word, such as whether one ending in "-man" should be "-men" or "-mans" (there were some of each.
Finally, as mentioned elsewhere, a significant percentage of what people communicate is incorrect -- either wrong words, misspelled words, improper grammar, redundant words, or excluded words. On top of that you can add faulty logic and incorrect "facts", either by accident or on purpose. It is not enough that AI-C can understand proper English (or other language); like humans, it must understand what humans are trying to say, as well as being able to verify what is said.
When a word is entered (in the Lookup program or in text being imported/read) and it cannot be found in the Words table, the Spell Corrector routine is called to find the most likely correction. When multiple suggestions get the same (or a close) rating, we can use the frequency of usage of the words as an indicator of which to use.
Word frequency will also be useful when we get to the stage of trying to understand written text.
In addition to the frequency ranking in the Words table, there is a frequency ranking field in the Cortex table with which the frequency ranking of different parts of speech and even different categories of the same word can be recorded. Take the word bound for example:
In such situations, use the Frequency list under Enter Word(s) to select See POS entries and use the Freq. list in the Entries area to set the frequency for each part of speech entry.
Even for the POS entry rankings, a word of a particular POS may have different frequencies for different categories (TypeOf, etc.; AKA: superordinates). In that case, for the POS entry enter See categories. Next bring up the category entry and select the frequency.
When bound is seen when parsing a sentence, it is most likely to be one of the first two parts of speech, although the syntax would be a determining factor in this case (i.e.: is the article about people or rabbits or finance?).
A frequency should indicate how often the word will appear in common text, NOT how familiar a word is to you. The purpose of all this is that when a misspelled word is found and multiple suggestions are about equally valid, then the frequency ranking tends to indicate which is most likely the intended word.
There is no need to agonize over whether a word is common or less common, but unless the frequency with which a word is seen in print or heard in ordinary conversation is very clearly common, tend to use less common.
AI-C uses the following word and word:POS rankings:
The American National Corpus Frequency Ratings:
The frequency ranking in AI-C was supposed to be based on the American National Corpus ("ANC") word usage frequency list of about 300,000 entries broken down by Parts of Speech for each word, but even after cleaning it up, the list was such a mishmash of unknown "words" intermixed with very common words, all of which supposedly have the same usage frequency, that there seemed to be no point in using it. Example: "wrod" is tagged as being a simple noun which appears 88 times in the ANC, but it does not appear in any dictionaries I've checked.
The most frequently used word in the ANC list is the at 1,204,817. Usage by word and POS drops off quickly from there. For example, a word ranked 2200th out of 300,000 words only appears 1000 times in the ANC - quite a drop from 1.2 million. A word that ranked 14,500 out of 300,000 words appears fewer than 10 times in the ANC. This means that over 95% of the words in the ANC each appear fewer than 10 times out of the 300,000 individual words in the ANC. Most of the "words" in the ANC appear only 1 time each.
Over 121,000 entries in the ANC list (a whopping 40%) are tagged as proper nouns. The word new, tagged as a proper noun, appears 16,560 times versus 19,233 for the adjective new. We don't know if their tagging software just assumes that any word with an uppercased first letter is a proper noun, but it is hard to explain some of these tags otherwise (and the "proper noun" new was not even uppercased).
When you get to words appearing less than 10 times in the ANC, there are so many non-word entries, proper nouns and words whose POS are tagged as unknown ("UNC") that that section of the list is pretty much worthless.
The ANC does not tag words as archaic or taboo/vulgar or jargon, and we do not want to add all the words it lists as proper nouns, That leaves the question of where to draw the line in the list between common and less common and rare.
The word die (verb), which I consider to be very common, is about #2430 in the ANC list. I say "about" because I did delete some junk entries. Meanwhile, organisms and colleagues, each of which I consider to be rarely seen in ordinary text, are ranked above die in frequency of use. The verb play is ranked 2615 and apoptosis is ranked above it. (!!)
I've seen at least a half-dozen word frequency lists, and sadly, ANC is actually no worse than the others, plus ANC has far more entries than the others I've seen. There may be better lists around, but none that are being freely shared, unless I have just missed them. The fact that the ANC ranks by POS would be a worthwhile feature if the list itself weren't otherwise so useless..
Just to clean up the list enough to work with it, I deleted all entries tagged as proper nouns or as unknown, then I deleted 100,400 entries for words:POS which appeared in the ANC 4 times or less. This reduced the number of entries in the table from about 300,000 to about 56,000 -- a much less impressive number, and the table still contains a LOT of junk.
I've left the cleaned-up ANC table in the database in case anyone wants to see it, but it seems too unreliable to be worth using.
While on the subject, Dictionary.com recently (2016?) started showing "Difficulty index" for words. Here are some examples:
At any rate, for the purposes of a spelling checker, usage frequency is more significant than a supposed percent of people who might understand the word. When choosing between possible corrections of a misspelled word, the word most often used is the most likely word intended (with the exception of a word known to be a frequent misspelling of another word).
Because frequency lists are so unreliable, frequency rankings in AI-C are mainly what I have manually entered based on my own judgment. A Google for such lists now and then turns up a new list, though always of a limited number of words.
I recently (early 2018) downloaded a list of "5000 most common words" which wasn't too bad compared to lists like ANC's, but still not great. Because manually entering frequencies is a slow task, I imported the top half to the list's frequencies as "common" and the bottom half as "less common".
There were a lot of clear misclassifications in the list, but they can be corrected when seen and as previously noted, the difference between common and less common is not huge and much better than the difference between common and nothing.
Dictionaries have entries for common word phrases/idioms, such as hot dog. (Technically, this is called a spaced compound noun.) At first, I added such phrases to the Words table, but then felt that it would be more correct to put the individual words in the Words table and then link them in the Cortex table to create phrases.
The primary reason against unnecessarily putting word combinations in the Words table instead of just linking existing words in the Cortex is that it takes more space. At the time this is being written, the Words table is more than 3 times the size of the Cortex even though they have about the same number of entries.
A second reason is that if the computer is parsing a sentence, it can use the same routines to look for hot dog as it does for green apple, which is to look for two+ words being linked in the Cortex, as opposed to looking for two+ words in the same entry in the Words table and then if they are not found, having to look for the same two words linked in the Cortex.
Another reason for linking words together in the Cortex to form a phrase is that if someone uses a phrase in speech with slight wording differences, it is still easy to match up their input to a phrase stored in the Cortex while a search in the Words table will be very difficult to match if the input does not exactly match the stored phrase. For example, if the input phrase is hot diggity dog and that phrase is not in the Cortex database, hot dog would be returned as the closest match, even though diggity may not even be in the Cortex.
Dictionaries include entries for word phrases because it would be a major inconvenience for users to have to look up two or three different words, note the meaning of each, and then try to put them together and discern the correct combined meaning (which could be difficult for hot dog). But we can link the words in the Cortex and create a definition for the linked set, so you normally want to avoid combining multiple words in the Words table.
Here is how hot dog is stored in the Cortex:
(Entry1ID and Entry2 are the ID#'s of other Cortex entries.)
| CorID | WordID | Entry1 | Entry2 | LinkID |
| 209110 | 2 | 30910 (phrase) | ||
| 209111 | 45018 ("hot") | 55210 ("hot" = adj.) | 209110 | 30911 |
| 209112 | 27858 ("dog") | 35609 ("dog" = noun) | 209110 | 30911 |
| 209113 | 209110("hot dog") | 30010 (noun) | ||
| 209114 | 209110("hot dog") | 30090 (adj) |
Here is how to find the phrase hot dog in the Cortex.
The above is just a rough outline of the steps involved. See the software code later in this document for a complete routine for looking up phrases.
Because "hot dog" is a phrase which is the name of a single item, we can make defining entries for the phrase's entry, #209110, just as we would for "dog". Shown are entries which classify "hot dog" as a noun and as an adjective (i.e.: "showoff"). You could also link 209110 (hot dog) as a type of fast food, or to frankfurter as a synonym, etc.
The phrase entry (#209110) has no links in it. Its only purpose is to provide a point to which all words in the phrase can link in parallel. For a 2-word phrase, this is no big deal, but let's say that entry #217324 (made up) is: "No use crying over spilt milk", where some of the words in the phrase may vary (e.g.: "No sense crying...").
-
#217324
| | | | | |
no use crying over spilt milk
The alternative is to link the words in series; i.e.:
-
no - use - crying - over - spilt - milk
If you searched for "no sense crying over spilt milk", you would not find this phrase if all the words were linked to each other in series, just as one bad bulb can put out a whole string of Christmas lights connected in series rather than in parallel.
With the words connected in parallel to one entry, as diagrammed above, you can still locate the phrase if one or more words are different. In this example, the main words (verbs, nouns, adjectives), which in this case would be use, crying, spilt, milk, should all point to phrase #217324, which in turn gives you entry numbers for the other words in the phrase.
If the text you were looking for used spilled instead of spilt, when you looked for phrases for use, crying, spilled, milk, only use, crying and milk would point to #217324. However, in that phrase you would see the word spilt and could look it up to find that it is a synonym of spilled.
The first example was a phrase which is synonymous with single words and which can be classified as a noun or adjective. This does not apply to the "spilt milk" phrase. It is only synonymous with other phrases which express the same concept, such as "that's water under the bridge", "what's done is done", or even phrases in other languages such as "a lo hecho pecho" (Spanish).
This may sound a little complicated, but that's the tradeoff you make for flexibility. Also, all of this is handled in the background by software, so though I say "you" have to do such-and-such, it is really the software that has to do it. You never see the complications once the software is working, and I have already written the code for tracing a word back to a phrase.
Entries linking words to a phrase are normally entered in the order they appear in the phrase. While this can be useful in recreating the standard phrase, it is still possible to look up the phrase when the words are jumbled, such as: no use crying after the milk has been spilled. Looking up each word's WordID-POS Cortex ID# matched with the 30911 (link to phrase) LinkID# will still lead to phrase #217324.
The case of letters can throw off a search for a phrase. If you searched for "No use crying...", AI-C would not find "No" because the phrase has been entered using the ID# for "no". It is possible to have a program search for each word as the opposite case when the original case cannot be found, but it is more efficient to correct the case before searching. AIC-Lookup will alert you if an otherwise matching word is found with a different case than the word entered.
Idioms:
Generally, phrases are entered because they are idiomatic; that is - the meaning of the phrase cannot be inferred from the meaning of the words in it. Example: happy person should not be entered as a phrase, but by linking {happy} <modifier of> {person} because both words have their normal meaning, but happy camper should be entered as a phrase because the word camper is not meant literally.
A very simple example of an idiomatic phrase is kind of, an adverbial phrase which is synonymous with rather, as in: I'm kind of hungry. If you look up the word kind, not only will you not find a definition which is synonymous with rather, but you will not find any definition which is adverbial, thus to parse a sentence with kind of in it and correctly label the word as adverbial, you must not only have an entry for kind of, but a second entry is required to label it as being an adverb.
A difference in most phrase entries is that they contain a, an and/or the which regular Cortex entries do not include because they would take up a lot of space without adding any understanding while entering a phrase implies entering ALL the words in the phrase.
Update: I now tend to enter any 2-word phrases, even idiomatic ones, as regular entries rather than as Phrase entries. Entering happy camper as a phrase requires 3 entries: the header entry, and an entry for each word linked to the header. Saving it as a regular entry only requires one entry.
LinkID #31013 (idiom meaning) can be used to link an idiomatic phrase to its meaning.
Possessives:
Dealing with possessives formed by adding 's to a noun is a problem. This comes up mainly when entering phrases.
One way is to link a noun to entry #127865 which is 's, then use that entry for a possessive. To enter father's day, first link father to 's then link that entry to day.
An alternative is to enter father <'s> day. using Link ID#29121 for 's. The advantage to this approach is that it only takes one entry.
Nested phrases:
The idiomatic phrase birds of a feather flock together is so well known (to the point of being trite) that many times people just say birds of a feather which must now be considered a short phrase nested inside a longer one.
One possible approach to making nested entries is to make the short entry first, as say ID#125831, then enter the full phrase as [125831] flock together.
However, it seems best not to link a phrase into another phrase. While it may save a few entries to do so (rather than entering all the words of the phrase again), it will make searching for phrases by words more difficult.
As shown in the chart above, each word in a phrase is linked to the master phrase entry and each word entry also contains the Words table's WordID#. When looking up a phrase, each word entered is looked up in the Words table then a search is done in the Cortex table for a phrase.containing all (or most) of the WordID#s entered.
Linking to phrases:
Like any other entry in the Cortex, it is possible to link to phrases. For example: entry 125867 links birds of a feather flock together as an idiom meaning like minded people associate.
LinkTypes table
- 29010 - Type of
- 29020 - Element of
- 29510 - Relates to
- 31011 - Synonym of
- 29100 - characteristic of
- 29101 - not characteristic of
- 29105 - characteristic of most
- 29106 - characteristic of some
- 29107 - characteristic of a few
- 29110 - part of
LinkType - The Magic Key
The LinkID field of the Cortex is like the magic key to the kingdom. The Entry1 and Entry2 fields are usually the ID#'s of entries in the Cortex and the LinkType identifies the relationship between those entries. For example, if you have an entry for radio and another entry for device, you could use the type of link to say that a radio is a type of device.
But a LinkType can also be recognized by software, causing it to use the numbers in the Entry1/Entry2 fields as something other than entry ID#'s, such as (1) data, (2) pointers to records in other tables, such as the Numbers table or a table whose records are pointer to external files (e.g.: pictures, text files, etc.), or even (3) pointers to external programs to be run, like statistics programs, games, etc. In fact, a LinkID under 10 tells the LookUp program that the number in the Entry2 field is data and not an entry number. (See Numeric and date entries.)
LinkTypes are stored in the LinkTypes table and can be easily added to or modified. The AI-C Lookup program barely scratches the surface, but does give a small taste, of how software can use the LinkTypes.
The initial entry for a word is an entry linking the word's WordID# (from the Words table) into the Cortex using one of the Part Of Speech ("POS") links, which are ID#'s 30000 to 30120. This tells us nothing about the meaning of the word. To establish the meaning and "understanding" of a word, it must be linked to other words, starting with a broad classification.
Here are the main types of classification categories:
We should try to assign every word to another word using one of the above links. When a word (e.g.: apple) is linked to another word (e.g.: fruit) (or set of words) using the Type of link, the word being linked inherits all the characteristics of the word to which it is linked. This saves having to assign the same characteristics to a number of similar items.
The expression comparing apples and oranges means to compare things which are not alike, but the fact is that apples and oranges have many characteristics in common. They are both fruits. Fruits all result from the maturation of flowers. are generally high in fiber, water, and vitamin C, and so forth. All such common characteristics are assigned to fruit and the characteristics are inherited by apples and oranges when they are each linked as a type of fruit.
The element of link can best be described with an example: a tire is an element of a car, but it doesn't inherit any of a car's general characteristics. The troposphere is an element of the atmosphere, as is the stratosphere because combined, they make up the atmosphere and each has most of the characteristics of the atmosphere, but individually they do not have ALL the characteristics of atmosphere, so they cannot be a type of atmosphere, thus we have to say they are each an element of it.
Relates to is used for words when no word Type of classification can be found.
Synonym of is used when one word (or usually, a specific meaning of a word) is used identically to (the specific meaning of) another word. The less common word should be assigned as the synonym of the more common word. All other/subsequent entries should be made to the more common word and are inherited by the less common word.
To reiterate, the initial link for words should be to words from which they inherit many characteristics.
Here is an example:
132610: 17637:alphabet is a type of 132609:system of writing language
125741: 39448:English is a modifier (adj.:noun) of 132610:alphabet [system of writing language]
136438: 64728:letter is a type of 109972:symbol
136442: 136438:letter [symbol] is an element of 125741:English alphabet [system of writing language]
127614: 121741:vowel is a type of 136442:letter [of English alphabet [system of writing language]].
136443: 26145:consonant is a type of 136442: letter [of English alphabet [system of writing language]].
125740: 20: a is a type of 127614: vowel [letter [English alphabet [system of writing language]]].
125822: 125255: z is a type of 136443: consonant [letter [English alphabet [system of writing language]]].
Here are some inferences which can be made from the above entries by way of inheritance without having to make separate entries for them:
English alphabet is a system of writing language.
letter is an element of system of writing language.
a is an element of English alphabet
The union of vowel and consonant = a power set of English alphabet.
This means that the elements of vowel and consonant = all the elements of English alphabet.
Classifications such as those above are more art than science in that there is more than one way to classify these things and get the same logical results. For example, you could create a Link ID for subset of and say that letters is a subset of symbols.
Here is an example of the difficulty or properly classifying a word:
artichoke is a type of vegetable.
It is also a type of thistle which, by itself, is not a type of vegetable..
It is also an element of the taxonomic family Cynara cardunculus var. scolymus
AI-C considers all three of these to be categories and as such, each appears in the Categories box. But when we link some other word to artichoke, we don't want to link to just one of these but all three.
The only solution I can think of is to nest them: artichoke [[type of vegetable] type of thistle] element of Cynara. This results in just one line in the Categories box and other words can be linked to that entry.
Note that the above links (related to alphabet) are arbitrarily cut off at system of writing, which could be linked to language which in turn could be linked as a type of communication, etc. In theory, such upward linking would never end, but for discussion purposes, it must be ended somewhere.
Also note that letter is an element of English alphabet but it is not a type of English alphabet.
In contrast, letter is an element of the symbol set, and it is also a type of symbol. While either could be used, type of is more
precise because element of doesn't necessarily imply type of, while type of does imply element of.
Here is an analysis of musical notes which is similar to the classifications of letter:
musical notation is system of writing music
note is an element of musical notation
A is a type of note
The following are related to musical sound and not directly to musical notation:
note is a written representation of pitch which is the wave frequency of a sound
tone is a synonym of pitch.
A above middle C (or A4) is defined as representation of frequency of 440 Hz,
Following are some Links which describe things:
A characteristic is a feature of something which is normally innate. Nocturnal is a characteristic of aardvark, because an aardvark normally comes out at night, though it may rarely appear during daylight. Hair on top of a person's head is a normal characteristic because the genes for hair growth are still there even if a person loses his hair.
A characteristic of most is a characteristic (innate feature) of most (a subset), but not all, fully formed members of a broader set. Poetic is a characteristic of most, but not all epigrams.
A characteristic of some or a few is a characteristic (innate feature) of some (a subset), but not all, fully formed members of a broader set. Nocturnal is a characteristic of all aardvarks, but it is only a characteristic of a few mammals.
An adjective in AI-C is used to describe a feature of something which varies over time, such as ripe fruit, gray hair, full moon, etc. Note that Parts Of Speech Link ID#'s 30000-30300 should NOT be used to link entries. For example, Link ID# 30090 is used to mark a word as an adjective, but to link two words such as red - adjective - ball, Link ID# 40300 (adjective : noun) should be used.
To once again illustrate the difficulty of making these types of entries, I originally used part of, as in "wheel is a part of a car", while at the same time using characteristic of for things like "nocturnal". I eventually realized that the above definition of a characteristic also holds for a wheel being a characteristic of a car, so I changed a few hundred entries from part of to characteristic of.
ConceptNet's Relational Ontology - I have just (Sept. 28, 2009) come across ConceptNet which has some similarities to what I am doing. While AI-C's LinkTypes table allows you to input any kind of linkage, just as the brain's cortex does, ConceptNet appears to be limited to certain predefined types of links:
- Things: Is a, Part of, Property of, Defined As, Made of
Spatial: Location of
Events: Subevent of, Prerequisite event of, First subevent of, Last subevent of
Causal: Effect of, Desirous effect of
Affective: Motivation of, Desire of
Functional: Capable of receiving action, Use for.
Agents: Capable of.
The advantage of ConceptNet's approach is that it makes it easier to have standardized categories. The advantage of AI-C is that it is more flexible and thus more easily adaptable to the real world.
main screenCompare its page for "aardvark" to AI-C's.
LinkTypes Classes
Classes are a way to group link types so that the program can easily refer to a whole set of different links at once. For example, link ID#'s 3000-30035 all belong to the nouns class.
Programming Note: A separate table for classes was originally used to hold the class names and the class field in the LinkTypes table was used to link each link type to a class in the LinkClasses table; however, this meant first looking up a LinkID# in the LinkTypes table, then looking up the class for that entry. Since the program frequently has to look up class names, it is easier to have the class names in the LinkTypes table and save having to look up the class name. Since there are relatively few LinkTypes entries, any space wasted by repeating the class names instead of using a numeric pointer is small.
One advantage of putting classes in a separate table and using their class entry ID#'s is that the program could reference those ID#'s and any changes to the class names would not affect the program code. With the names in the LinkTypes table, if a class name is changed, the program code (and possibly the documentation) must be checked to see if they are affected. On the plus side, class names are pretty basic and should rarely have to be changed.
Parts Of Speech
In Phase One, the primary use of LinkTypes was to indicate the Part Of Speech ("POS") for each word linked into the Cortex.
Adverbs, conjunctions, articles, interjections, etc., normally just have one POS entry related to them. Nouns can have two -- singular and plural. (A plural noun is treated as a separate entry with no singular form.) Adjectives (and sometimes adverbs) can have three forms -- regular, comparative, and superlative (e.g.: high, higher, highest)
Most English verb entries have four forms -- present, past, gerund (or present participle), and third-person singular (run-runs, do-does). When entries are made for the words for the past, gerund, and 3rd-person forms, the entries contain a link to the entry for the present tense, which is considered the root. Some verbs also have an entry for a past participle form, which is also linked to the entry for the present. Irregular verbs, like to be have a relatively large number of forms and must be treated differently than other verbs.
Contractions
One-word contractions include o'er, 'bout, 'cause, 'em, 'n', 'neath, 'til, ma'am, and e'en (which can be even or evening), but in informal conversation as well as in writing done for effect (i.e.: eye dialect), almost any word can be contracted. One of my favorites is a countrified response to Are you done yet?, which is Not plumb, but p'ert' near, where p'ert' is a mangled contraction of pretty, which in this context means very. The word 'stache is sometimes seen as a contraction of mustache
Two-word contractions include pronoun-verb (e.g.: they've) and verb negation (n't on the end: aren't). These are entered by putting the contraction in the Word or ID box, the first word in Entry1, the second word in Entry2 and the LinkID for contraction (30930) under Link.
The third type is not not formally considered a contraction, though it does meet the definition of a shortened form of a word or group of words. However, this category might more correctly be called eye dialect.
Examples: sorta (sort of), kinda, gonna and whodunnit. When eye dialect is being used, the number of such contractions is virtually unlimited, so only common ones such as those just listed should be entered. Whether or not these are genuine contractions, they are entered in the Cortex the same as above.
A contraction of 3+ words is not common. O'clock is one, but nobody ever says of the clock, so o'clock is more a word of its own rather than a true contraction. Likewise, shoot-'em-up is classified as a contraction in dictionaries, but a contraction of what? Nobody EVER refers to a Western (movie or TV show) as a shoot-them-up, so as a phrase, shoot-'em-up is not a contraction, and just because the phrase contains a contraction in it does not make the phrase itself a contraction, since, again, its non-contracted form is never used.
This also applies to eye dialect forms. Example: wannabe actor (someone who aspires to be an actor) is never referred to as a want-to-be actor.
Nested contractions are rare, but possible. One example is 'tain't, which is a contraction of it ain't, which in turn is a contraction of it is not. A more modern example is sup for what's up which in turn has a contraction of what is. Note that the apostrophe is usually not used with sup.
Word insertions:
A word insertion is when one word, usually an exclamation or expletive, is inserted between the syllables of another word. Even multiple words can be inserted. This is actually common in German.
Example, sung by Liza in My Fair Lady: "Oh how loverly sitting abso-bloomin'-lutely still."
In America we lean more towards: "Abso-friggin'-lutely."
Some people refer to this as tmesis, but that seems to have a somewhat different meaning of separating words in a verb phrase and putting other words between them. Google tmesis for examples.
I haven't figured the best way to handle this, but thought I would mention it.
Affixes:
Affixes are another way to combine text with existing words to make new words, except that instead of combining two words, we combine all or part of an existing word with a prefix or (more commonly) a suffix. For example, to refer to a dog not on a leash, you may say that it is "leashless".
Since there is virtually no limit to words which can be made up in this way, trying to enter them all into AI-C would be pointless. So instead, if you enter a word with some common extension (such as "leashless") and that form is not in the Words table, the spelling corrector will suggest that it may be a word meaning "without a leash".
For purposes of understanding text in documents, a flag would have to be raised to indicate that an input word is not in the Cortex but could be a combination of words and then it would be up to the software to see if the combination fits in the syntax given. For example, if the text includes a discussion of leash laws for pets in a community, then it would be easy to understand the phrase "pit bulls running leashless...".
Links to data in other tables
Most of the links in the Cortex will be for describing the relationship between two Cortex entries specified in the Entry1 and Entry2 fields, but some LinkID's can identify numbers in the fields (the Entry2 field, usually) as pointers to entries in other tables or files, such as a Source table, Numbers/Dates table, Shapes table, etc.
LinkTypes which point outside the Cortex table or which call for data in a Entry1 or Entry2 field rather than CortexID#'s should be given LinkID#'s less than 1000. This will allow software searching for CortexID#'s in those fields to ignore those LinkID#'s.
How Cortex entries link to other tables is discussed in depth in the sections for the other tables.
synonym vs alternative vs definition
Synonyms are different words which have at least one identical meaning.
For example, the word abstract can mean remove, steal, summarize, generalize and more. We cannot say that steal is a synonym of abstract because abstract has all those other possible meanings with which steal is not synonymous. The next question is: what is abstract a type of which steal is also a type of? How about taking. If that is acceptable, we can link abstract (POS=verb) to steal <type of> taking.
All links which would ordinarily be made to abstract (synonym of steal) should be made instead to steal <type of> taking and then abstract inherits all those links, as will any other words which are synonyms of steal, such as rob or purloin. The word to which all the synonyms link is called the "root". For our purposes, it's best to link the less common word to the more common word, such as abstract being a synonym of steal rather than saying that steal is a synonym of abstract. If both words are equally common, such as rob and steal, it doesn't matter which is the root.
This process might be more easily understood if instead of a root synonym, we used a placeholder entry and linked all the synonyms, definition, and attributes to the placeholder. This would make it clear that these elements belong to ALL the synonyms and not just to the somewhat arbitrarily selected "root synonym".
The cost of doing it this way is that it adds a placeholder entry to the database for every set of synonyms. At this time, I'm not bothering with a placeholder; I'm just linking synonyms to a root.
An alternative link for main entries indicates an alternative spelling of two words which have precisely the same meaning. Usually, the two words have very similar spellings, such as buses and busses, though rarely, they may be two completely different words with identical meanings, such as abattoir and slaughterhouse. Because it is only a different spelling, all shades of meaning and usage meanings for the two words are normally identical.
However, buses and busses are alternative spellings only as they apply to the plural form of bus, which is a type of vehicle. The spelling busses is also the sole plural form of the word buss, which itself is a synonym of kiss. So we must link: buses <type of> vehicle as an alternative of busses <type of> vehicle
So neither synonyms nor alternatives can simply be linked to Word-POS entries because most words have more than one meaning and another word may only be synonymous with a particular meaning. However, as a starting point, Word-POS entries may be linked to each other and then as more (defining) links are added, the links changed to the actual meanings (where meanings are actually the links from a Word-POS defining its characteristics, etc.).
It is worth noting that words from different languages have the same relationship that alternatives and synonyms do within the same language. For example, adios has the identical meaning in Spanish that goodbye has in English, so they are essentially just alternative spellings of each other, although instead of linking them as alternatives, we link them as Spanish-English.
Example of usage of Links
The verb bind (e.g.: to tie up) has a past tense of bound. But bound is also the present tense of a verb meaning to jump, etc. The present-tense verbs bind and bound can also be transitive (LinkID #30060), intransitive (#30050), or both (#30065).
The verb forms for bound are bounded, bounding, bounds. Bound can also be a noun (#30010) or an adjective (#30090). Here is how the POS entries for all of this look. The dashes separate the entries for bind from the entries related to the present tense form of bound. (Text in the table below is not in the Cortex table; it is shown here for convenience.)
Note that entries with links for "verb trans.", "verb intrans." and "trans & intrans." are always present tense, then the other verb forms are linked to these entries.
| Words | Table | ID | WordID | Entry1 | Entry2 | LinkType |
| -------- | --------- | ------- | --------- | ------- | ------- | ------- ------------------- |
| 8706 | bind | 13581 | 8706 | 30060 - verb trans. | ||
| 10406 | bound | 13582 | 10406 | 13581 | 30070 - past tense | |
| 8712 | binding | 13583 | 8712 | 13581 | 30080 - gerund | |
| 8716 | binds | 13584 | 8716 | 13581 | 30045 - verb 3rd-prs.sing. | |
| ------- | --------- | ------- | --------- | ------- | ------- | ------- ------------------- |
| 10406 | bound | 15571 | 10406 | 30065 - trans & intrans. | ||
| 10409 | bounded | 15772 | 10409 | 15571 | 30070 - past tense | |
| 10413 | bounding | 15773 | 10413 | 15771 | 30080 - gerund | |
| 10418 | bounds | 15774 | 10418; | 15771 | 30045 - verb 3rd-prs.sing. | |
| ------- | --------- | ------- | --------- | ------- | ------- | ------- ------------------- |
| 10406 | bound | 15775 | 10406 | 30010 - noun | ||
| 10407 | bounds | 15776 | 10407 | 15775 | 30015 - noun plural | |
| ------- | --------- | ------- | --------- | ------- | ------- | ------- ------------------- |
| 10406 | bound | 15777 | 10406 | 30090 - adjective |
Notice that in the Entry1 column, entries for verb tenses other than the present link back to the entry for the present tense. Code in the AI-C Lookup program, given later in this document, show how descriptive links made to different word forms can be found when looking for just one of the verb forms. That is, if you look for the word ran, the code will look for all links not only to ran but to run, running, runs, etc.
Adjectives (and a very few adverbs such as far, farther, farthest) are entered in a similar manner where the comparative (-er) and superlative (-est) forms, if any, link back to the original adjective.
The word cannot presents a problem because it has to be categorized as a verb, but its only form is the present tense. It should be linked to the entry for can as its negative, but which entry for can? Well, it must be a verb entry, but the verb form has more than meaning ("is able to" and "to store food in an airtight container"). So it must be linked to the entry which links can to the meaning is able to. This illustrates why linking words without definitions is futile.
Noun phrase, verb phrase (etc.) Links
Entries 40000 - 40999 indicate various types of phrases as can be seen in the Links table. There are many ways to link words together, from 33000: link (generic) to any of the relationship links. The phrase links (not to be confused with links for entering a general phrase) have the advantage of identifying the POS of each of the linked words as well as indicating how the words are linked.
Examples:
40000 (noun : verb) is just a simple noun-verb link. The text in parentheses is not shown in the Links box (cat <> ran)
40001 noun {to} verb is mainly to indicate the infinitive form of a verb, such as permission to leave
40003 noun {can} verb such as we can go
40011 verb {to} object such as drive to work
Using the last line above as an example, without these links, you would have to first link drive and to and then link that entry to work, so the above method saves space. It also may make it easier to interpret text since if drive to work were in a sentence, you would have to figure out the relationship between those words and the meaning of to.
This link allows passing a command to the Lookup program. At present there only a couple of codes:
(Up) - says to capitalize the first letter of word in the Entry1/Entry2 field.
(s) - indicates that the entry applies to both the lower- and upper-case forms of the word(s)
Pronunciation table
-
Introduction to pronunciation
- Most dictionaries do not use a standardized set of pronunciation symbols. The u in cure, cute, and music is shown as yoo in Webster's and yoo with a cup over it in American Heritage. A desktop version of Merriam-Webster's shows it as yu with a diacritic over the u. And even using IPA, there are differences in the examples above between Dictionary.Com and Wiktionary.org (upside-down 'r' in IPA and a space before the 's' in Dictionary.com's version).
- It is virtually impossible to figure out without a guide how to pronounce some of the symbols used.
- The major standardized set, the IPA, is very difficult and/or time-consuming for the non-expert to figure out even with a guide.
- The symbols used by most other sources, and especially the IPA, cannot be displayed onscreen without installing special fonts, which is why graphical screen captures are used to display the above examples.
- Two-letter combinations are sometimes used for a single letter, but because they are in lowercase like the other letters, if you wanted to convert Dictionary.com pronunciations to a different format, it would be difficult to distinguish such letter combos from normal (non-combo) uses of the letters.
- The pronunciation of some Dictionary.com combos, such as ey, are not obvious because English words use "ey" in words with different sounds: key (EE in AI-C), eye (IE), and obey (AE in AI-C). In addition, "ey" has no obvious sound of its own while if you run together the sounds of the letters in EE, IE, and AE, you get the desired sound.
- Some combos are in italics, which creates extra steps in encoding/decoding pronunciation spellings. In the listing above, Dictionary.com shows [pruh-nuhn-see-ey-shuhn], following an italicized uh with an unitalicized uh and then ey in bold instead of using an accent mark.
- All uppercase letter combos are pronounced just as they are spelled (EH = the interjection: eh), as are all lowercase letters.
- If you want to convert AI-C's pronunciation table to a different format, the letter combos could be easily swapped out for other letters or symbols because they are uppercased and thus easily distinguishable from other letters in a word.
- All letters are from the English alphabet and can be displayed without special fonts.
- addict is pronounced ad'ikt as a noun and eh-dikt' as a verb.
- bass is bas when it means fish and bAEs when it means a low range of sound.
- read is rEEd in the present tense and as a noun ("the book was a good read"), but red in the past tense and as an adjective ("he is well read").
- lead is lEEd when it means "guiding someone" but led when it refers to the mineral.
- buffet is bu-fAE' in its noun form and buf 'it in its verb form ("to hit")
- ally is al'IE as a noun and EH-lIE' as a verb.
- alum is a problem because its pronunciation determines the meaning.
If pronounced al'EHm, it is a mineral, but as EH-lum', it is a shortened variation of alumnus, but unlike the other examples, it is a noun in either case. - chassis is both singular and plural, but it is pronounced shas'EE in the singular, shas'EEz in the plural.
- desert is des*ert - dez�EHrt as a large, arid, sandy area and de*sert - de-zEUrt� as abandon or as "just deserts".
- project is prAH'ject as a noun and prEH-ject' as a verb. Its syllabification also changes from proj-ect to pro-ject.
- duplicate is dEW'pli-kit as an adjective or noun, but dEW'pli-kAEt as a verb.
- salve is sav (as in "savage") when the meaning is "ointment" but sAOlv (as in "salvage") when the meaning is "salvage". It is interesting that both Random House and American Heritage (according to www.dictionary.com) show the same pronunciation for both meanings, but when you click on the recorded pronunciation for each meaning, you can easily hear the difference in the tonal quality of the "a".
- > (such as >ing) -- indicates that the last character of the preceding syllable moves to the start of this syllable. For example, dat*ing has a pronunciation of dAE'ting. In some cases, two letters move, such as itch*ing = it'ching. To get the > back, you must only submit whole syllables, indicated by a starting asterisk, such as *ing; otherwise, the program assumes you are not submitting whole syllables (which is possible, but not recommended).
- < (such as <zh'EHn -- indicates that the letters shown before the first pronunciation mark go with the preceding syllable, even though they are part of the sound of the word syllable submitted. Example: cian is submitted from the word ma*gi*cian. It's pronunciation is mEH-jish'EHn, where the shEHn sound of the cian syllable goes with the gi of the preceding syllable.
- @ (such as @OH for ough) -- indicates that the returned text is not reliable. You can choose to ignore the returned text and look for something better, or use it anyway.
- #__: text1, #__: text2 shows alternative pronunciations where the blanks contain the number of matches found for each.
AI-C has a pronunciation table in addition to a table of syllables.
The formal division of words into syllables frequently does not indicate how the word should be pronounced. Instead, it seems to be a device for indicating how a word should be hyphenated when at the end of a printed line of text. For example, quickly is syllabified as quick-ly, but its pronunciation is qui-klee, with the k moving from the first syllable to the second.
AI-C's pronunciation spelling
Here are examples of some other source's phonetic representations of the word pronunciation:
| www.Dictionary.com (alpha) |  |
| www.Dictionary.com (IPA) | 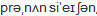 |
| www.YourDictionary.com | 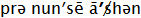 |
| www.Wiktionary.org | 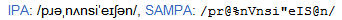 |
From this, it is easy to see why we created for AI-C a new means of showing pronunciation:
The Dictionary.com's alpha spelling comes closest to being usable, and had I found Dictionary.com in time I might have used its system, but it still has problems:
April 23, 2013: I have just come across Pronunciation Respelling For English on Wikpedia which acknowledges the difficulties with IPA and has a chart showing the respelling systems used by various dictionaries. I can't find a date of creation of the page anywhere, but based on the dates on the Talk page, it appears to have been in 2005.
An even more interesting article is Wikipedia: Pronunciation Respelling Key which appears also to have been created in 2005 and is a chart detailing the system used in Wikipedia articles. It is a much more extensive system than the one used in AI-C. It has 2- and sometimes 3-letter combinations, creating the same problem mentioned above for Dictionary.com. And for some reason, they retained the upside down "e" which is unprintable in Windows without a special font installed, plus the average person probably doesn't know how to pronounce it.
However, the biggest problem (for me) is that the resulting spelling is still not phonetic. Here are some of their vowel respellings:
In phonetic spelling, "a" should be pronounced the same whenever it appears. Yet, while the "a" is pronounced the same trap and marry, it's different in start. I understand that in Wikipedia's system, the "a" in "ar" is allowed to indicate a different sound than the "a" in "arr", but if the goal of the system is to make it obvious on the face of it how to pronounce words, that is not the way to do it.
While Wikipedia's system is doubtlessly more technically accurate (for those who understand it) than AI-C's, virtually nobody speaks with such precision, so it is better for Natural Language Understanding to have a more generalized pronunciation system. By the same token, for someone looking up how to pronounce a word for general speech, a highly scientific pronunciation is overkill (i.e.: it takes a trained ear to hear the difference).
sound example AI-C a trap trap ar start stAHrt arr marry mar�EE
A pronunciation guide is displayed in the bottom-right corner of the AI-C Lookup program. The long vowels (those which sound the way the letter is named and which are often displayed as the letter with a horizontal bar over it) come first: AE, EE, IE, OH, EW/YEW/YOO. Next are the short vowels: a, e, i, o, u. The upside-down e used in most systems (called schwa in phonetics) is pronounced eh, so AI-C uses EH for it.
AI-C's version of pronunciation is prEH- nun' sEE- AE� shEHn.
Notice that two accent marks are needed - the main accent ( � ) and the secondary accent ( ' ). Because there is not a key for the main accent, AI-C generates it when the backward accent ( ` ) is hit. (This is the key normally to the left of the 1 key.)
For a complete discussion of ways of showing pronunciation, see Cortex Pronunciation Guide.txt.
Linking to pronunciations
It would be easiest if the pronunciation of a word could just be linked to entries in the Words table, but the fact is that the same word can have more than one pronunciation, so the Pronunciation table has a field to link an entry to the word in the Words table and to the WordID-POS entry in the Cortex. However, this means that when the same word can be used as several different Parts Of Speech, a separate Pronunciation table entry must be made for each one. This is usually redundant because different POSs for a word normally have the same pronunciation, but it is necessary and appears to be less redundant than other approaches.
In rare instances, pronunciation has to be linked to the entry for one of the specific meanings of a word. For example, address is pronounced EH-dres' in its verb forms and some of the time in its noun form (such as in the phrase: polite forms of address), but for most of its noun usage (it was mailed to his address), it is pronounced ad'res.
Since an entry in the pronunciation table can link to any type of entry in the Cortex table, it does not have to link just to a POS entry; it can link to entries for different meanings of the same word. In this situation, you would not have an entry in the pronunciation table linked to the WordID-POS entry for address - noun as you normally would, in which case the next step would be to search the pronunciation table for the word's WordID and get the CortexID numbers for those entries to use in tracking back to the Cortex.
ha'rass and ha-rass' are two pronunciations of the same word with the same POS and same meaning. In a case like this, two entries can be made in the pronunciation table which link to the same WordID-POS Cortex entry.
It should be noted that at present, the Lookup program does not show multiple pronunciations of the same word with same POS, category, and meaning. This is such a rare event that changing the layout of the program to accommodate such exceptions doesn't seem necessary. For a word which has more than one entry for POS, the entry can be modified to show the appropriate pronunciation. For example, use as a verb is pronounced YEWz while as a noun, it is YOOs.
Different pronunciations of the same word
The words the and a introduce a problem which has not been addressed yet in AI-C. The problem is that before a vowel, the is pronounced thEE while before a consonant, it is thuh, and there is presently no way in AI-C to indicate that.
Sadly, the list above makes it seem unlikely that there could be any hard and fast rules for computing pronunciation based solely on spelling. (Saying "unlikely" is giving the benefit of the doubt, because it is barely possible that there could be rules which 99% of the words follow, and we are looking at some of the exceptions.)
Computing pronunciations.
Since it appears unlikely that rules can be used to compute the pronunciation of words, I use analysis of the pronunciation table to do that.
When adding a new word to AI-C for which you do not have the pronunciation, it is possible to compute it from the Pronunciation table. First drop one letter at a time from the end at a time until you can find a word (preferably many words) in the Words table with the same starting letters. Look up the pronunciation for those words and extract the part which applies to the starting segment you are using.
For example, say you have a new word, telespiel (a made-up word: the prepared script used by telephone sales people), for which you have no pronunciation. You would write code to look for telespie, telespi, telesp, teles and get a match with telescope. The matching text in syllables is tel*e with the s being part of the next syllable. So we now have tel*e and spiel.
We go back through the Words table and look up the pronunciation for all words starting with tele and find they all have the pronunciation of tel'EH. Then we go through the Words table looking for all words (or at least the first 100 or so with the same ending when looking for more common endings) ending with spiel, such as glockenspiel and find the matching pronunciation for spiel, which is spEEl or alternatively, shpEEl.
Put the two pieces together and you have tel'EH-spEEl -- a completely made-up word, but for which we now have a legitimate pronunciation and syllabification.
This procedure is very reliable when you get 100 matches from the Words table and all 100 have the same pronunciation, but it is less reliable when there are only a few matches in the Words table or if there are several different pronunciations found, more than one of which is in significant quantities. For example, ough is sounded as OH in though, but as EW in through and AOf in cough, but uf in rough. Thankfully, ough is a very unusual example.
But when there are few word matches and/or no predominant pronunciation among several alternatives, it is best to try other means of computing the pronunciation, or just taking a stab at manually entering it. Even if the pronunciation is wrong, it isn't the end of the world. Worst case scenario is that someone notices it is wrong in the future and corrects it.
Naturally, you do not want to manually perform the steps listed above. I have Visual Basic code (available by request) to do the steps, but it is fairly complex, and I can't guarantee that anyone can follow it despite ample comments and examples given.
The problem is that letters in actual words rarely match up one-for-one with letters in the pronunciations. Some letters are silent, some require two letters in the pronunciation and vice-versa, some letters/sounds get reversed (such as ble at the end of a word being pronounced bel), a letter at the end of a syllable in a word may be at the beginning of the next syllable in the pronunciation, and sometimes one syllable in a word may become two in the pronunciation or vice-versa. The routine has code to adjust for such things, which is what makes it complex.
If you use Visual Basic, all you have to do is add the routine to your program and pass it some text. Otherwise, good luck translating it.
My routine normally just returns the pronunciation for the text given to it, but it has a few special codes:
Syllables table
The Syllables table stores the syllabification of text in the Words table. It would be more efficient to have this data as another field in the Words table, but some words have different syllabifications for different definitions, such as pro*ject, proj*ect and des*ert, de*sert.
Numbers table
The Entry1 and Entry2 fields in the Cortex table are 4-byte long integers. They can store whole numbers with up to a value of 2,147,483,647, but they cannot, individually, handle larger numbers nor decimal numbers.
If we made these fields double precision, the cost would be a large increase in the size of the database in order to handle a relatively few entries with large numeric data. So instead, we use the Entry2 as a pointer to a record in the Numbers table which has two double-precision fields, Num1 and Num2, with a combined precision of up to 30 digits.
Such large numbers are entered as text, such as 123456789000987654321. The text is split into two parts of no more than 15 digits each, like 123456789000 and 987654321, and each part is stored as numeric data in the double-precision fields, Num1 and Num2. To extract the original number, the process is simply reversed.
In addition to the numeric input, 1 or 2 codes can be added which indicate the precision and/or format of numbers, as well as other things. Also, two numbers can be entered, separated by a comma, with a code which describes them, such as being the bottom and top of a range or some number plus-or-minus another number.
Not too often will anyone need to store numbers with greater than 7 digits of precision, but it does happen. But the real advantage of putting numeric data in the Numbers table is being able to use the precision/format codes to define the numbers being entered.
The Numbers table can also be used to store dates and/or time and anything else which can be reduced to numeric input.
For more information, see Creating a Cortex entry in the program documentation below.
Side note:
The maximum size of the Text field in the Words table is 50 characters. (The maximum allowed by Access is 255.) The Access help file says: "You should use the smallest possible FieldSize property setting because smaller data sizes can be processed faster and require less memory." However, if text fields are set for compression, then trailing blanks in a field would be compressed to almost nothing.
Shapes Table
The best way to understand the Shapes table is to look at in Access.
The Shapes table is a way to make rough drawings of things in the Cortex by using LinkID# 900 to link to various elements in the Shapes table. Each entry in the Shapes table is a different shape element, such as line(s), curve, ovals, rectangles, etc.
While each general shape can be linked to a numeric entry indicating how the shape is angled, each shape also comes with entries for standard angles, such as vertical and horizontal to save time and eliminate the need for entries to record numbers.
Shapes can be combined (linked) in the Cortex.
Nothing is being done with the Shapes table at this time. It is easier to click on Pictures in the Ext.Ref. menu.
Sources Table
The Sources table provides a means to reference external sources of Cortex data. Sources could include publications, web URLs, text files, or even a person's name. A source can be anything you wish to reference, although there would normally be no reason to reference something when multiple sources provide the same information, such as a common dictionary definition. On the other hand, while many sources may have information about a particular subject, if one source is significantly better than the others, it should be referenced.
If conflicting data comes from different sources where the correctness of neither source can be established with certainty, simply make two (or more) entries with the different data and reference the different sources, then link the two entries with a LinkType of 29160: different from.
The Sources table has four fields: (1) Cortex entry ID#, (2) Filename? checkbox, (3) reliability score, and the name of the source.
If a source is a file, include the full drive and path name. If the file is on removable media, enter a description of the media (e.g.: CD-ROM #1035 or DVD "ScienceBlog Downloads" or FlashDrive #3) followed by a comma and then (optionally) the full path and file name.
Obviously, linking to a file or even to a Web URL is iffy because either of them could disappear in the future. And a file link to your hard drive will not work if your database is given to someone else or simply moved to another computer. A rewritable DVD is preferable for storing referenced files because copies of the DVD can be made to go along with the database if it is moved or shared, plus software can be made to prompt for the insertion of the named DVD when needed.
Since the above was written, use of The Cloud has exploded and it should be possible to have shareable data files online.
Web pages can be downloaded and saved locally to protect against a site's disappearing, if considered important enough.
Reliability is rated 1-5 with 5 being the most reliable. The highest rating should be reserved for the most authoritative sources (and even that doesn't mean it's impossible for them to be wrong). Unless a source is widely acknowledged as a top authority in its field, the highest rating a source should get would be a 4.
For example, when I was looking for information about plant rhizomes, this web site came up. It looks very professional, it is a site dedicated solely to rhizomes, and everything on it is supported by other independent sources. I would rate it a 4 based solely on those facts, but it is also funded by the National Science Foundation, which is enough for it to be rated a 5.
In contrast, TheAnimalFiles web site also appears to be very professional and the creator says: I am an English teacher with a passion for animals... The information that I use is from a wide variety of trusted sources such as, IUCN (International Union for Conservation of Nature), ITIS (Integrated Taxonomic Information System), EDGE (Evolutionarily Distinct & Globally Endangered), The Cornell Lab of Ornithology, National Geographic etc.
It's very tempting to give TheAnimalFiles.com a 5 rating, but the fact is that the creator is not a leading expert and there is no way of knowing how accurately information was compiled from the authoritative sources. Also, a 4 indicates an excellent source, but 5 is reserved for "the most authoritative sources".
When entering a URL as a source, other information such as the source's name, date, etc. can be included before the URL. You can double-click the Source box to bring up a URL in a web browser. If the page does not come up, try copying and pasting the URL into a browser.
It was difficult to decide if the reference number in Source table entries should be a unique number for each entry, or if it should be linked to a specific Cortex table entry ID#. If the Source table has its own entry ID# field, then the Cortex table would need another field in it to point to the Source table entry ID#. On the other hand, if each entry in the Source table has the ID# of a specific entry in the Cortex, then if more than one Cortex entry has the same source, a duplicate entry would have to be made in the Source table to point to each Cortex entry. AI-C is using the latter -- each Source entry points to a specific Cortex entry.
To minimize duplication, the Source entry should point to the highest up entry for a subject in the Cortex. This would normally be a word's TypeOf entry ID#. Then it is assumed that other entries linking to that one share the same source. In some cases, that won't be true, but in some of those cases no source is really needed because the entry covers a widely known fact; otherwise, such an entry can be linked to a different source.
"z" Tables
Several tables are in the database with names starting with "z_". These are not essential parts of the database.
For example, the Brown Corpus table and the Internet table show the word frequencies in their respective sources. However, such lists do not indicate what definition of a word is being used, and capitalization cannot be trusted in most such lists.
E.g.: China is in the Brown Corpus list, but is it China the country or the dinnerware? (Remember: caps cannot be trusted.) Unfortunately, for the two lists mentioned, the numbers are for the combined usage of all possible meanings of each word, such as fire, which can be a noun, verb, or adjective, each with more than one meaning. (Example: fire an employee does not have the same sense as fire someone up or fire a weapon.) Therefore, these lists are only marginally meaningful. Nevertheless, the tables have been included in the database, though relegated to "z_" tables.
Using the AI-C Lookup Program
Introduction
- with a specific name like "document"
- to the default directory
- in the word processor's standard format.
- If a user doesn't want the file overwritten the next time he creates a document, he must use a file manager to rename it before saving the new one.
- If he wants the file stored in a different directory or drive, he must use a file manager to move it after saving it.
- If he wants the document in a different format, he must get a program to convert it after saving it.
- for a file name
- a place to store the file,
- and the format to save it in.
The ultimate goal of AI-C is to be able to understand text, to reason, and to communicate, but that is a long way off.
The purpose of the current AI-C Lookup program is to make it easy to examine, edit, and add new entries in the database. (See the main screen.) The white boxes are where data is displayed when you look up a word or phrase. The red boxes are where individual entries can be entered, viewed, and edited. The blue boxes are where phrases and multiple entries can be entered.
The picture of keyboard keys in the bottom right corner of the main screen shows the keys used to enter accented characters (for non-English languages). Only those which can be viewed in Windows 10 without any add-ins are supported in the current version of AI-C Lookup.
The Pronunciation Guide above the accented characters picture is a key to AI-C pronunciations.
AI-C Lookup can look up a word and display all links for it, including phrases with the word in it. AI-C Lookup can also search for a Cortex entry ID# and display it and all of its related entries. Likewise, you can enter a phrase and search for it (or the closest match) or search for a phrase ID#.
So although AI-C Lookup is a long way from being a full NLP/AI program, it can be useful for some things. Because I usually have it up on my system working on it, I often use it to check on the spelling or pronunciation of a word. The Ext.Ref. menu has links to see definitions, Wikipedia articles, synonyms, pictures, and more.
AI-C can also be used to store information about a particular subject, including source, reliability, date, and other data on the Web, as well as linking the new data to existing AI-C data or other new data, adding your own thoughts, and so on, and then use AI-C Lookup to access all that information.
For example, a while back I took a Master Gardener's course. I was still working on the AI-C program at that time, but if it had been functioning to the extent it is now, I could have entered the information from that course into the program as I was reading the books and listening to classes, then had an easy way to look things up rather than having to thumb through the manuals as I actually did.
For examples, look up "a", "aardvark", and "abacus". (If you are not able to run the program, see the screen shot link above.)
Complex vs Simple Code:
Programming bloggers frequently write that code should be simple. AI-C's code is not simple. There is a trade-off between providing simplicity for the user and simplicity in the code.
For example, say that you are writing the file saving routine for a word processing program.
The simplest code would be to ALWAYS save a document
This allows simple code at the cost of a lot of trouble for the user:
Alternatively, the program could prompt the user
This results in more "complicated" code, but in a greatly simpler experience for the user.
Set-up
Just make a directory/folder anywhere you wish and put all the AI-C files in it.
The layout of the Lookup program has been adjusted over the years as the resolution of common monitors has increased. I am using monitors which are many years old and they still have 1920 x 1080 resolution. Since such monitors cost well under $200 (under $100 in 2018), I consider them the minimum standard and have changed the layout to fit that size.
With monitors being so cheap, it is worth getting a second (or even third) one. I have three -- one with the program running, one displaying the VB source code for editing, the third with the Access databases for AI-C. Although changes to the databases can normally be made in the AI-C Lookup program, it is sometimes easier to look up and change some entries in Access.
Newer computers have HDMI out and newer monitors have HDMI in, so you all you need is an inexpensive HDMI cable. If the HDMI out is being used or if your monitor doesn't have HDMI in, you can connect a monitor to a USB port with an adapter and a cable to run from the adapter's output to your monitor's input.
See this screen shot of how AI-C Lookup, the source code, and the Access files look spread across three displays. This shot was taken in early 2013 and can be compared to the main screen to see the changes that have been made to the interface over the years.
Word look-ups
- Edit button: Loads the current POS entry into the New Entry boxes. Click it again to load the current Category entry.
- WordID#: The ID# in the Words table for the word shown.
- The box above the right end of the word box: lets you save words you want to go back to.
-
< Copies the word from the save box into the Enter word(s) box.
+ Copies the word from the Enter word(s) box into the save box.
- Removes the word shown from the save box.  The down arrow at the right end of the Enter word box: Drops down a list of the next 32 words in the Words table. Click on a word to make it the current word or click in the Enter word(s) box to hide the list.
The down arrow at the right end of the Enter word box: Drops down a list of the next 32 words in the Words table. Click on a word to make it the current word or click in the Enter word(s) box to hide the list.
- < > buttons: Go to the previous/next word in the Words table.
- Find cID: Finds the Cortex table entry for the ID# entered in the box to the right and displays the entry in the Enter word(s) box.
- Frequency: is important for making spelling corrections, among other things. Select a frequency here and it is automatically saved to the Words table.
The red Entries fields also include a Freq. field. Make a selection there and it is saved in the Cortex table when the entry is saved. Example: wrack can be a verb (wracked with guilt) which is a less commonly used word, or it can be a noun, which is archaic.
So Frequency for wrack in the white box should be set to See POS entries in the Words table and set to less common for the verb entry and archaic for the noun entry in the Cortex table. - If the text entered is not found in the Words table, the program will display a list of suggested corrections, including splitting up run-on words (for more info, see Spell corrector under Look-up buttons, below); otherwise...
- All Parts Of Speech ("POS") for the word will be displayed in the POS box.
- All Category entries for the first POS entry will be displayed in the Categories box.
- All links to the first POS entry's first Category entry (if any) will be displayed in the <Links> box.
- Double-clicking an entry in the POS list box will cause all Category links to it (if any) to be displayed in the Categories list, and all links to the first Category link in the list box, if any, to be displayed in the Links list.
- Double-clicking a line in the Categories list box will cause all links to it to be displayed in the <Links> list.
- The syllabification and pronunciation of the word are displayed in those boxes on the right.
- The usage frequency of the word is displayed just below the word entered and its Words table ID# is shown just above it.
- both men and women are retired from the Navy, were at the festival, and are missing
[[retired [men and women] from the Navy] at the festival] are missing - only the men are retired, and both they and the women are from the Navy, were at the festival, and are missing.
[[[retired men] and women] from the Navy] at the festival are missing - only the men are retired, and only the women are from the Navy, and both were at the festival and are missing
[[retired men] and [women from the Navy]] at the festival are missing - only the men are retired, and only the women are from the Navy and were at the festival, and both are missing
[[retired men] and [women from the Navy at the festival]] are missing
If you have a second monitor, you may want to put this shot of the main screen on it for reference while reading this description of the features found in the upper left area.
To look up a word, put it in the Enter word(s) box and press Enter or click Look up word .
Here is part of a definition in Wiktionary:
- A mammal that lays eggs and has a single urogenital and digestive orifice.
Does it mean it has a single urogenital and it also has a digestive orifice or is it saying that it has a single orifice for both urogenital and digestive purposes?
To avoid ambiguity, square brackets are used in AI-C to group words when displayed, such as
- ...a single [[urogenital and digestive] orifice].
Here is a more complex example:
retired men and women from the Navy at the festival are missing
Here are possible interpretations of that sentence followed by bracketed sentences which remove ambiguity:
Ambiguity only exists when the text of the entries is displayed without brackets. There is no ambiguity in the Cortex because the entries are made as shown in the bracketed examples above. If you linked retired and men first and then linked that entry to and women then it would be displayed as [[retired men] and women] and if you linked men and women first and then linked retired to that entry, it would display as retired [men and women].
Another example:
-
130827: air <consists of> [gasses <which are> [mostly [oxygen <and> nitrogen]]]
The brackets around oxygen and nitrogen are necessary to make it clear that mostly applies to both words, but the brackets around the last part of the entry starting with gasses are not necessary because there is no ambiguity without them. The problem is in creating a simple algorithm to determine when there is ambiguity. Since there is no real harm in the extra brackets, the code errs on the side of having too many, even though it can make the text visually more difficult to read even while it makes it easier to understand:
To simplify the appearance of the text in the Links List, the use of brackets can be turned off or on using the Brackets check box.
All of this once again illustrates the advantages of how data is stored in AI-C compared to storing information in the forms of sentences.
Accented/diacritical characters:
Keep pressing the following keys (normally unused when entering words) to cycle through the letters shown. Note that on the keyboard, these are on three adjacent keys working left to right and the shift of those keys working left to right to get variations of a, e, i, o, u and then � and y, so they should be easy to remember.
|
[ = � � � � � � � � � � � � �
] = � � � � � � � � \ = � � � � � � � � { = � � � � � � � � � � } = � � � � � � � � | = � � � � | 
|
This feature works on all input boxes in the program. The picture above was added to the main screen for easier reference.
Finding words with affixes added:
If a word is not found, AI-C will check for various prefixes and suffixes and show any possible matches. I recently saw the word "penster" online and entered it in AI-C to see if it was in the database.

So AI-C was spot-on with its definition without having the word in its database, If a future version of AI-C is used to translate text and came across the text "John Smith made his living as a penster," AI-C would start with the clue "one who pens" and would find the verb "pens" to be a synonym of "writes" and that a person who writes is a "writer" and conclude that John Smith was a writer.
To edit a word, look up the word to find its POS entry, then edit the POS entry. Edit the word in the Word or WordID box, leaving the WordID# unchanged, then press Tab to leave the box. You will be asked if you want to save the change. Say yes.
After editing a word, you will then need to change the entries in the Syllables and Pronunciation boxes and click [Save Changes].
To delete a word, bring up its POS entry and click [Delete]. You will be asked if you want to delete the word from the Words table. If so, the program will automatically delete the Syl and Prn entries.
Anytime an entry is deleted, the software will check to see if another entry is linked to that entry and if so, it will tell you to change that entry first.
Compound words
A typical definition of "compound word" is "a combination of two or more words that function as a single unit of meaning." This is somewhat vague, since it is up for debate as to whether any two words "function as a single unit".
For example, it would seem that the phrase "single unit" itself meets the definition, but few experts would likely say that the term is a compound word. For that matter, is "compound word" a compound word?
My first thought was that it depends on frequency of usage, just as with any word, as explained by Merriam-Webster which says that wether or not they add a word to the dictionary (thus recognizing it as being a "word") depends upon which words people use most often and how they use them.
Compound words can be formed in any of three ways -- (1) combining the words together, such as flypaper, which is not a concern for us since a closed compound is a single word which should already be in the Words table, (2) combining the words with a hyphen between them, such as high-priced goods, (3) and pairing the words together with a space between, which raises the question: what is the point of calling them compound words if they are just two words side-by-side with no special punctuation.
As a matter of fact, many words in AI-C are linked together because every entry in AI-C's Cortex table is made up of two fields linked together and those fields are often made up of individual words.
Well, one reason for identifying them as compounds is that the individual words may have somewhat different meanings when in a compound. For example, we can say that the compound hot dog is a noun which is a type of food when we would ordinarily say that hot is an adjective which relates to temperature and dog is a noun which is a type of animal.
When there is a series of words which we want to link together, we could link the first two words together, then link the third word to the entry for first two, then link that entry to the fourth word, and so forth, as shown here. Using this approach almost guarantees that none of the entries would be usable in other situations because you would never be linking pairs of words after the first entry.
What we normally try to do is link together any word pairs in the series which are most likely to be used in other series of entries. For example, with the phrase "predict cold weather <in> winter" the two words most likely to be used together the most in other situations are "cold weather" so we would link them together first and then make entries linking each of the other words to them, such as predict <(verb : object)> [cold weather] in one entry, then linking that entry to <in> winter.
Closed compounds come about by being used as word pairs for so long that they eventually just become a single word.
Some hyphenated compounds are always hyphenated no matter how or where they are used, such as father-in-law, re-elect, and not-for-profit. So there is no need for rules for them either.
The open compounds are where hyphenation rules are needed, but there are no hard and fast rules for when to hyphenate them. Normally it's done when a compound comes just before a noun, such as "deep-fried Twinkie", and only then if needed to avoid ambiguity. One exception is that adverbial compounds are not hyphenated if the adverb ends with -ly.
Although hyphenated words may be stored as such in the Words table, it is more efficient to store the individual words and link them in the Cortex with a Link of "- (hyphen)". The rare exception would be if one or more words in the compund is NEVER used outside of that compund because if you are going to make an entry in the Words table for such a word only to use it in the compound, you may as well use that entry to store the entire compound.
For example, there is no point in making a Words table entry for diggity when it is only ever used with hot (i.e.: hot diggity), even though hot is already in the Words table. It takes the same number of entries for hot diggity as just diggity.
Reduplications are words, usually rhyming, which are paired for effect, such as helter skelter. Here is an interesting web site about Reduplications. (Though the reduplications listed on that page are all hyphenated, they would normally be used as unhyphenated if used as nouns and only hyphenated otherwise.)
It is usually more efficient to pair individual words in the Cortex rather than entering word pairs in the Words table when the individual words are already in it; however, reduplications often consist of made-up words which will likely never be linked individually to any other words. In that case it is more efficient to make one entry in the Words table for the pair..
If a reduplication does consist of words already in the Words and Cortex tables, such as chick flick, then they should be linked (normally as compounds) in the Cortex. If just one of the words is already in Words, such as gritty in nitty gritty, it takes no more space to make an entry for the word pair (e.g.: nitty gritty) than to make an entry for the made-up word (nitty) and then have to pair it to the other word (gritty) in the Cortex.
To look up the text a Cortex entry represents, enter its ID# in the box to the right of the Find cID button and press Enter or click the button.
Look up any series of linked entries by entering up to ten words (or other text entries, so long as they are in the Words table) in the Enter word(s) input box and clicking Look up word. If all the words entered are linked in a series of entries, those entries will be displayed in the Links list.
Note that we are not talking about looking up compound words, but any words for which you would like to find entries in which they are linked together.
Example: entering plant, seed would cause the following line to be displayed:
- seed
You can find the same entries by entering any one of the words and looking through the Links listing for sets of linked entries which contain the other words, but the previous method saves you having to look through such a list.
Phrases
To understand the use of phrases in AI-C, see Phrases in the previous section.
One way to enter a phrase in AI-C is by linking two words together, then making another entry to link that entry to another word, etc. See Entering multi-entry scripts.
The advantage of this approach is that you end up with a lot of entries in which two or more related words are linked to each other with a LinkType which indicates how they are related. Then these individual entries can be linked with other entries or sets of linked entries to create a new phrase or concept without having to reenter all the same words.
Another way to enter a phrase is to type it into the Phrase box and click Save. A base entry is created followed by an entry for each word in the phrase, in order, linked back to the base entry.
The advantage to this is that it is faster and easier to look up a phrase.
To look up a phrase by text, enter all or most of the words in the white Enter word(s) box and click Look up word or enter the text in the blue Phrase box and click Find Phrase..
To look up a phrase by ID#, enter the number in the box to the right of the Find Phrase button then click the button.
To edit a found phrase, make the changes and press Enter or click the Save button.
To add a new phrase, start typing it into the blue Phrase box and press Enter or click the Save button.
The Links List Box
The purpose of the Links list (the large box in the picture below) is to display the links found for a specified word or words. First the links to the selected POS are shown, then links to the Categories/Hypernyms entry for the word are displayed. Normally, links are only made to a word's Category/Hypernym entry so that's all that would be shown.
When looking up a word and an entry is found which is linked to the word's entry, the program looks to see if another entry is linked to that entry, and if another entry is linked to that one, etc., until the complete series of linking entries is found. Then the series of entries are combined into one and displayed.
Each entry in a combined series of entries is connected to the others with a link type which is in angled brackets. The highlighted entry in the screen shot below is pretty simple: the entry for nocturnal is linked to the entry for aardvark with a link type of characteristic of.
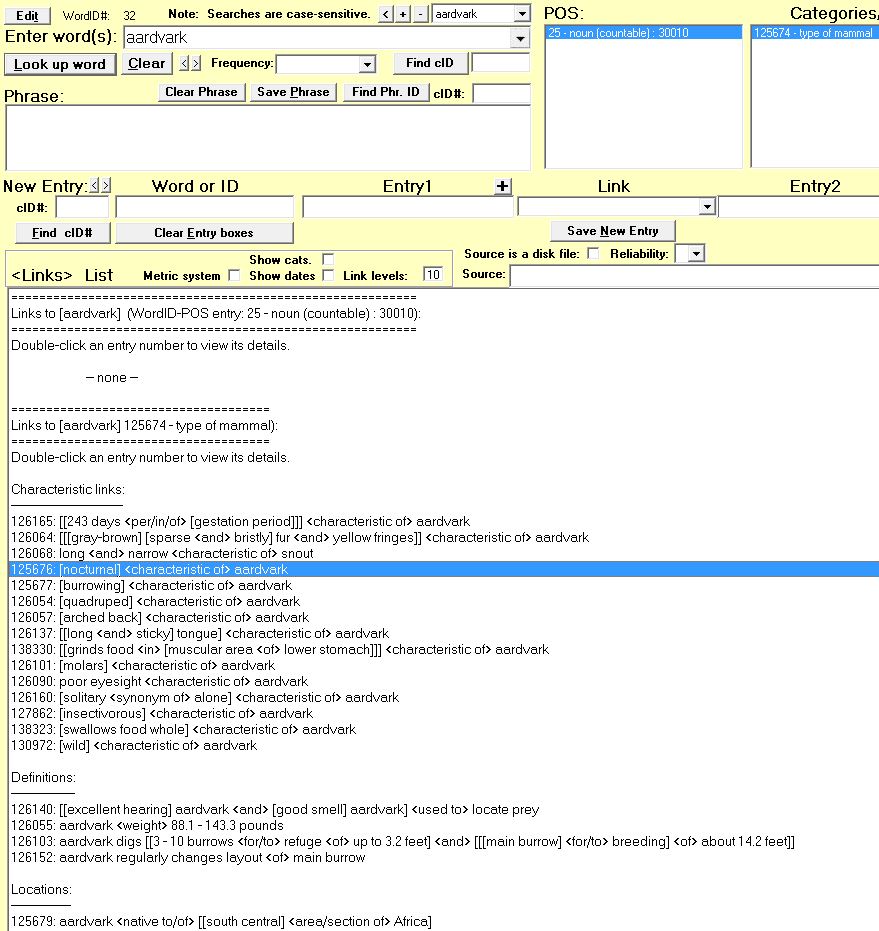
Double-clicking on the line shows the entries making up that entry in more detail:
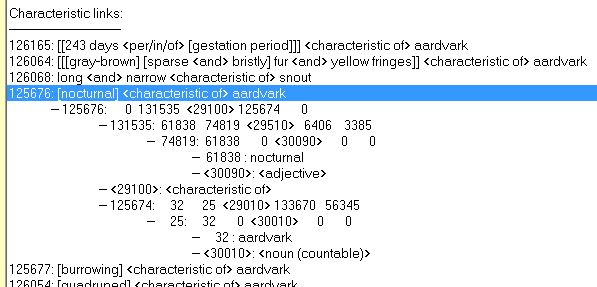
Checking the Show cats box (currently named Show links) above the Links List box, shows the Category/Hypernym details on one line:

Double-clicking an entry while Show cats is checked shows all the details:
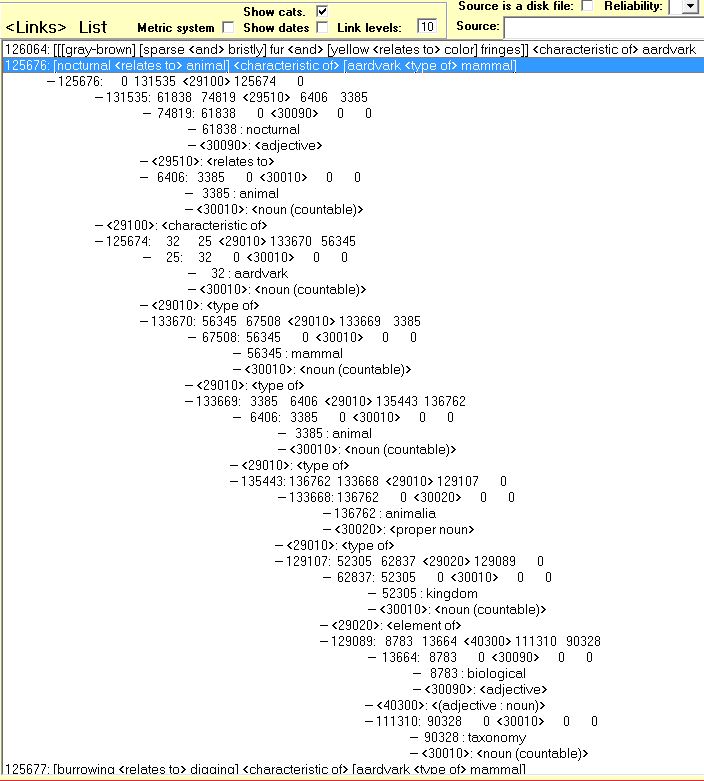
Other display options include:
- Show the date of the main entry at the end of the line.
- Double-click a detail line to load it into the red edit boxes.
- The Link levels check box indicates how many levels of linking entries should be shown. For example, if entry #1002 links entry #1001 to another ID#, then 1002 is a direct link to 1001. If entry #1003 links entry 1002 to another ID#, it is a 2nd-level link to 1001. If you look up entry 1001, it would show #1002 but it would not show #1003 unless Link levels is 2 or higher.
An exception is that if #1001 links a word to a phrase in entry #1000, then all the other entries linking words to the phrase pointer 1000 are shown when looking up the word in 1001. For example, #136182 is "=someone=", 136183 is "comes" and 136184 is "around" -- all of which link to the phrase pointer 136181. A search for "around" would not just show the entry linking around to the phrase pointer; it would show what would normally be a 2nd-level link of "=someone= comes around". Then if you wanted to show the meaning of that phrase, you would need to set the Links level to 2, which would show #136189 "136181: =someone= comes around" -- "31013 - idiom meaning:" -- "136185: changes =one's= mind".
I leave Link levels sets on 10 and if too many entries are shown in the Links box, I lower the number so that fewer and fewer less direct links are shown.
The Links Table Window
The Links table is displayed automatically when the Lookup program is run. It can also be called up under the Tools menu. It lists all the entries in the LinksType table.
To add a new entry, enter an ID#, link name/description, and class, then click the Add button.
( ) - Text in parentheses is only there to aid in picking the correct link; it does not appear in the Links box in the LookUp program.
Example: 29710 to (something) displays as to.
{} - Text in curly brackets is the only part of the link name to be displayed.
Example: 40001 noun {to} verb displays as to.
[ ] - Text in square brackets is displayed along with the rest of the text.
Example: 29210 make[s] displays as make[s].
To edit an entry, double-click on the entry in the list or single-click and then click Edit. Changing the text for a LinkType has no effect on entries already made since only the link's ID# is stored in the Cortex.
When an AI is just conversing with someone, most LinkTypes do not need code written specifically for handling them. For example, If the AI is saying where something is located, it could use whatever the appropriate code is for the location class, which includes entries 5000 - 5500.
Another example is that changing the text for LinkID# 29010 from "type of" to, say, "element of". will have no affect on the program and any entries with a LinkID# of 29010 will still be listed in the Type-Of list box. However, if you change link ID 29010 to 39010, the Links table will automatically change all entries with 29010 to 39010 and they will no longer be displayed in the Type-of list.
So when you change a link type entry's ID#, the program checks the software's source code and the documentation file (Index.htm) to see if the entry's ID# is used and if so, warns you. This does not assure catching every use of the ID#, though. The number you are changing may be part of a range of numbers. You still need to examine the files to catch those. To help solve this problem, the program code has been changed wherever possible to use LinkType Classes instead of ID#'s to cover ranges of LinkType entries; however, at this time there are still some link type ID# ranges used in the program which could not be replaced by Classes, so it is still necessary to manually search for them.
More importantly, if multiple people are working on individual copies of the AI-C database and make such a change in LinkID #'s, his database will no longer be able to sync up with the others, so such changes should only be made rarely and by coordinating with everyone else working from copies of the same database.
See the Declarations section of the frm_Lookup.frm code for constants used to store Class names.
The program does search the Cortex for the LinkID number being changed and changes those entries.
The purpose of all link types may not be 100% intuitive. Select a link by clicking on it and then click "Show Examples" to see a list of Cortex entries which use the selected link type. The examples are listed in the Links list box in the main program window.
Creating new Cortex entries
Creating a new Word and/or WordID-POS entry I put the following in a table instead of a list because I wanted some spacing between the lines, but not as much spacing as separate paragraphs would create.
| Enter the following data in the red boxes under the caption, Entries: | |||
| 1. | Enter the word in the Word box, or if you know the word's ID# from the Words table, you can enter that. If the word entered is not in the Words table, you will be asked if you want to add it. | ||
| 2. | If the word is a form of another word ("root"), such as past tense or noun plural, enter the root word in the Entry1 box. | ||
| 3. | Look up the Part Of Speech in the Link drop-down list box. | ||
| 4. | Leave the Entry2 box blank. | ||
| 5. | When entering a word in the Word Table, you should enter the syllabification and pronunciation. You can look them up at www.dictionary.com. The pronunciation there will need to be converted to AI-C format. The Pronunciation Guide on the right side of AI-C Lookup should help, or if there is a similar word already in the Cortex, look it up and double-click its Syllables and Pronunciation to put them into the New Entry boxes as starting points. For example, if you were entering unthinkable, you could look up think to get that part of the word and something like capable to get the -able part.
A primary accent mark looks like this:  while a secondary accent mark is a single quote mark: while a secondary accent mark is a single quote mark:  .
Since the primary accent mark is not on the keyboard, the program accepts the backward single-quote key which is on the [~] key and converts it to the primary accent. .
Since the primary accent mark is not on the keyboard, the program accepts the backward single-quote key which is on the [~] key and converts it to the primary accent.
| ||
| 6. | Select a word usage frequency from the drop-down list. (See Frequency for more information.)
| 7. | Click the Save new entry button. The word's Soundex code and sorted-letters form are computed for it automatically and saved with the word. | |
Making Linking Entries:
The Cortex database does not contain any text, only entry ID numbers. Many examples are given in this document, but here are a few additional notes:
The Word Table boxes each have a check box above them. When an Entry ID# traces back to a single Words Table entry, the program will look it up when saving the entry and put the number in the Word Table box(es) if the check box is checked. Alternatively, you can manually enter a Words Table ID# or word.
When an Entry also has a Worda Table number, the program will look up and display that Words Table entry rather than the Entry's Cortex table ID#. For example, if Entry2 is Cortext entry number 138715: armadillo <type of> mammal and Entry2 Word Table is 4771: armadillo, the program will look up 4771 in the Words Table rather than looking up Cortex entry 138715 and tracing it back to the WordID-POS entry which has the same 4771 Word Table #.
This means that if the Word Table box and Entry box don't trace back to the same Word Table entry, whatever is in the Word Table box will be used, even if it doesn't match what's in the Entry box.
Entering Prefixes and Suffixes:
Like other Cortex entries of text from the Words table, prefixes and suffixes ("affixes") are entered in the Word box in the red Entries section. If an affix just has one meaning, it can be entered in the Entry1 box.
An affix should not show a hyphen unless it is always used hyphenated in words. For example, "fore" as in "forefathers" has no hyphen in the Words table while "great-" as in "great-grandfather" does have one.
To see a list of affixes, use Show Examples in the Links window:
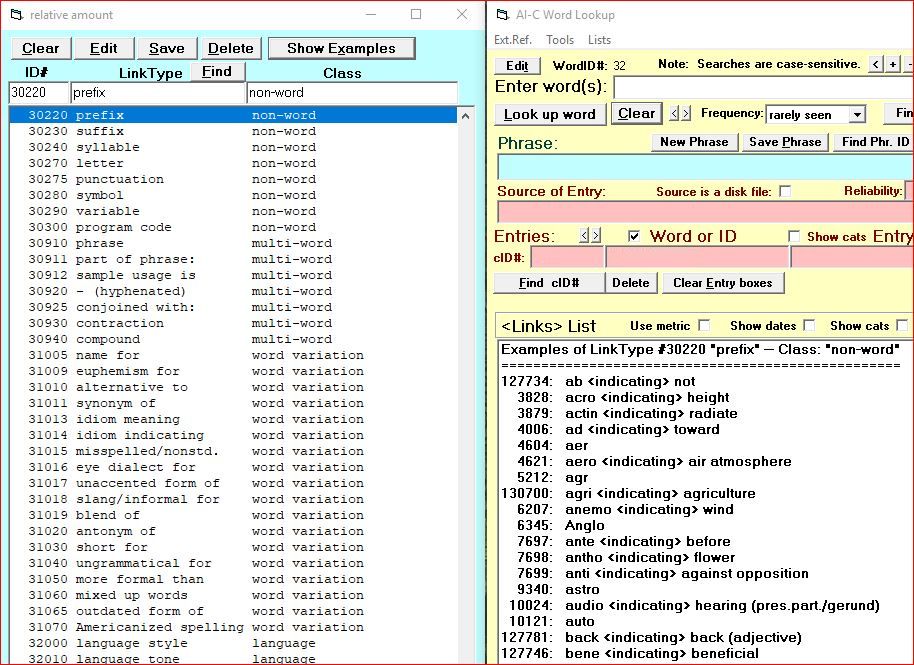
Code boxes are at the top of the Entry1, Link, and Entry2 boxes. When displaying entries in the Links List box, it is often helpful to use brackets or parentheses ("groupers") to eliminate ambiguity about how words should be grouped, as has been explained elsewhere in this document.
The program code initially attempted to compute when and where to add groupers, and while it mostly worked well, it was not perfect and required a lot of very specific code.
The Code boxes can be used to exactly specifiy when and where to add them. The boxes can also be used for other purposes:
- ( or [ can be opened in one box, such as Link, and closed in Entry2. Example: cat (<type of> animal).
Or you can open and close groupers in the same box just by entering "[ ]" or "( )" with no spaces. - U will cause the first letter of the word to be uppercased. To uppercase other letters, specify the letter number, such as "U1,U5" to change "somebody" to "SomeBody". This isn't needed for words (mainly names) already uppercased in the Words table, such as "McDonald's". To uppercase all following letters, enter "U*" for the whole word, or "U1,U5*" for "SomeBODY" or just "U5*" for "someBODY"
- s will create a singular/plural display by adding "(s)" to a noun or something like "box/boxes" if the plural form requires it.
Uppercase letters, numbers and symbols are made plural by just adding s, such as A, B, Cs and He made all As.
Plurals of lowercase letters are formed by adding 's, such as watching your p's and q's. - < > Some links have alternative wordings, such as #31018: slang/informal for (see screen shot above).
While you can usually figure out which wording a link requires, it is cleaner to be able to indicate which to use for a specific entry you are making. This is done by entering "<" for the word before the slash (slang) and ">" in the Link's code box to use the word after the slash (informal).
Any leading or trailing text will be included with whichever word is specified, such as slang for. To avoid this, links use "_" to connect such words, such as 29430: causing/cause_to. The programming routine can be made to replace "_" with a blank space.
If a Link has three options, such as 5010: located in/on/at, enter "\\" (the word after the two slashes) for the left-most word (in), "/ \" (no spaces) for the middle word (on) ("/" says after the first slash and "\" says before the second slash), and "//" for the third word (at).
If a link contains optional text none of which you want, put "x" after the < or >.
Example: for in a/an/the use <x to just show in. - t adds the to the end of a link before the Entry2 text. Example: the link caused by may sometimes read better with or without an article: floods caused by rain (non-specific rain) or floods caused by the rain (specific rain).
- a adds a/an to the end of a link before the Entry2 text.
An article can even be added to link text which is in parentheses such as <(verb : object)> which is not displayed in the Links List. Example: change brought < > cake to brought <a> cake
What Parts Of Speech are numbers?
Numbers are usually adjectives and sometimes nouns. There's some debate about whether or not they can be pronouns.
Entering different pronunciations or syllabifications of the same word and POS:
If a word has different pronunciations or syllabifications ("prn/syl") for different parts of speech, just make the entries as described above. Example:
| ID# | Word | Entry1 | Link | Entry2 | Syls | Prn |
| 64238 | 53564: lead | 30010: noun | lead | led | ||
| 64234 | 53564: lead | 30060: verb | lead | lEEd |
When the prn/syl are different for different meanings of the same POS, we want to attach the prn/syl to the meanings, not to the POS. To do this, create a normal word-POS entry(*), then create an entry for each meaning with a different prn/syl. Example:
| ID# | Word | Entry1 | Link | Entry2 | Syls | Prn |
| *11684 | 7273: bass | 30010: noun | ||||
| 127677 | 7273: bass | 11684: bass | 29010: type of | 44322: fish | bass | bas |
| 127678 | 7273: bass | 11684: bass | 29010: type of | 104200: sound | bass | bAEs |
Note: The only reason for putting 7273: bass in the Word field for the last two entries is to get the boxes to open up for entering the syllables and pronunciation. This was simpler than putting another button to open them and I don't want them open all the time when they shouldn't be used. 05-12-2018 Update: I now leave the syllables and pronunciation boxes open all the time.
Creating entries for related Parts of Speech
Several features are included which make it easier to create entries for related Parts Of Speech ("POS"). First bring up an entry in the Enter word(s) box, then click the Edit button.
The entry will be displayed in the New Entry boxes where you can modify the existing entry. All you have to do is click Save Entry (or press Enter) to save it. In addition, a new button appears which lets you create an entry for the next related POS.
For example, if you enter the (made up) verb fligle, the button on the right will say Make entry for: past tense Click the button and an entry will be created for fligled (including the syllabification and pronunciation) and the button will then say Make entry for: gerund, then for -s (verb), which is the 3rd-person singular form.
If you enter a noun, the button will offer to create an entry for the Noun Plural. Enter an adjective, and it will create the comparative form and then the superlative.
This makes it very easy to create a set of entries, but look to make sure that the computed entries are correct, particularly the syllabification and pronunciation, which can be difficult to compute.
After reviewing the entry, you must click Save Changes.
Normally a word with a POS of uncountable noun cannot have a plural form; however, a plural form can be created to indicate that the word can be plural on very rare occasions.
After creating a WordID-POS entry for a word, the next step should be to link it to some other word which helps define and categorize it. A WordID-POS can have many different meanings, and it is preferable to link descriptors and other entries to one of these major definitions or categories.
Any links made to the other word apply to the word being linked to it without having to make the same types of entries to the linking word too. This saves a lot of effort and storage space, as explained next:
Using the letter "a" as an example, here are some Type of classifications for each of its Parts Of Speech:
- indefinite article
- "a" <type of> determiner [grammar]
- "a" <type of> quantity (e.g.: "I would like a Coke and two Sprites.")
- noun
- "a" <type of> letter <element of> English alphabet
- "a" <type of> tone <element of> scale <part of> music
- "a" <type of> vowel
- preposition (as in: each, every, per; e.g.: "Take one a day.")
- suffix (mostly slang: kinda, sorta)
When a word/element is linked as a <type of> another word/set, any entries linked to the set automatically apply to the elements of the set. For example, if "a" is a type of "tone", then anything which is a characteristic of "tones" is also a characteristic of "a [<type of> tone]".
A Synonym of a word has the same meaning as a specific definition of another word, which can be called the "root synonym" for convenience. Again, any words or concepts which link to the root automatically apply to the synonym. The more common word should normally be the root synonym, such as "abode <synonym of> home", then related entries should be made to the root (home, in this example) which are then inherited by the word linking to it (the linking word). Exceptions are phrases which specifically use the linking word, usually for effect, such as "Welcome to my humble abode."
Relates to is used when no convenient type of can be found for a noun or when a POS other than a noun is being entered. For example, address (noun) is a type of location, but that is too broad for convenience because there is a huge difference between a street address and a computer memory address. So we say that address <relates to> computer memory location and that it <relates to> physical location. Note that address is not a type of either of these categories which would mean that it has all the same characteristics of them.
Only nouns can have type of links because an adjective (or adverb or verb), for example, can't be a type of anything. So we say that an adjective relates to something. Example: red (noun) can be a type of color, but red (adj.) is not a type of color but it relates to color.
Picking what seems like the best TypeOf (etc.) entry can sometimes be difficult, but sometimes, simplest is best. For example, I struggled for a few minutes with airborne (adj.) until I realized that relates to 'air' is best. While obvious to humans, it is an essential link for the software to have in order to be able to "understand" what the word is about.
Before linking a word as a TypeOf another, ask yourself what the other word is a TypeOf. For example ability could be called a type of capability (the obvious link), but what is capability a type of? More likely, ability is a synonym of capability. Is ability a type of characteristic?
The following are used to describe people and things:
- How was it created? (Who/what was it made by?)
- What is it made of?
- What are its characteristics ("distinguishing features or qualities")?
- What is it able to do. (What are its abilities?)
- What is its appearance (shape, size, etc.)?
Since ability is one of these things, it must be a TypeOf whatever this list of things can be called. "Descriptor" is defined as a significant word or phrase used to categorize or describe text or other material, especially when indexing or in an information retrieval system. Wow! That could not be any more on target. So I linked ability (as well as characteristic and appearance) as a TypeOf descriptor.
When I'm having trouble thinking of a good TypeOf for a noun, I usually Google the word to get ideas, often ending up in Wikipedia.
Take the word shade as used in regards to landscaping and gardening. Reading Wikipedia led me to believe at first that shade is a type of darkness.
But one definition of landscape shade is an area of comparative darkness caused by the blocking in whole or in part of the direct rays of light from the sun.. I don't think that this is right.
Darkness normally indicates the complete or nearly complete absence of light from any source while landscape shade is virtually never a complete or even nearly complete absence of light. It's possible to read a book in shade but not in the dark. So I don't think that landscape shade is a type of darkness. In fact, it is more accurate to refer to it in amount of light it contains.
The primary (if not sole) reason for sitting in the shade outside is not to get less light but to escape the heat of the sun. Likewise, a plant which prefers to be planted where it gets afternoon shade is also trying to escape the heat of the sun's rays, not the light.
Next arose the question of whether or not shade is a type of shadow since both shade and shadows are caused by the blockage of light..
However, a shadow is an area of comparative darkness on the surface of one or more other objects while shade is the area between the blockage of the light and the surface.
A tree's shadow is what appears on the surface of the things below it while its shade is the entire space between its leaves, limbs and trunk and the things below it. Therefore, landscape shade is not a type of shadow.
Shade comes from the blockage of the sun's rays, whether you are talking about light or heat, but it is not a type of blockage, it is the result.
So based on all this, it may be best to say that shade is an ElementOf the environment. It could even be considered a TypeOf environment since shade has its own degree of light and temperature compared to the surrounding environment.
Creating a standard linking entry
A standard linking entry links two other Cortex entries by entering one number in the Entry1 field and the other number in the Entry2 field and a link type in the Link field.
- In the Entry1 box, enter the Cortex ID# for the first entry to be linked.
If you do not know the ID#, enter the word and AI-C will look up the number. - In the Word Table box, enter a word or Words table ID#, if any, for the Entry1 ID#. (See below.)
- In the Link box, enter the Link name or ID#..
- In the Entry2 box, enter the Cortex ID# for the second entry to be linked.
- In the Entry2 Word/ID box, enter the word or ID#, if any, for the Entry2 ID#. (See below.)
If you do not know the ID# of the second word, enter the word. - Click the save button.
Auto-Complete: When you start typing in Words or Entry 1 or 2, a list will pop up showing what words are possible from what you have typed so far. You can click on a word in the list to enter it. If you don't see the word you want in the list, that may indicate that the word is not in the Words table.
Word/ID numbers
When software is converting an entry to text, most Entry1 ID#'s and Entry2 ID#'s must be tracked back through other linking entries to a single Words table entry. To save the time needed to do the tracking, enter the Words table entry ID# in the Words boxes.
Click the check box to the left of the Entry1 and/or the Entry2 captions to have AI-C automatically enter the WordID for the Entry1 and/or Entry2 entries. It will only enter words which appear alone in the Entry 1 or Entry2 fields unless the additional word(s) are a Category entry because it must enter only a WordID#, which normally can be for just one word.
For example, if the Entry1 field has red <(adjective : noun)> car, the program will not make an entry in the Words field. You could enter the word car in the Entry1 field, but the word red would never be displayed.
However, if the Entry1 field has text like car <type of> vehicle, it put just car in the WordID field since type of vehicle is a Category.
Entering a series of linked entries
Enter a series of linked entries by clicking the New Multi button above the blue Phrase box. The box below will be displayed:

Example: entering a definition of aberration based on entries in www.dictionary.com:
focus - the clear and sharply defined condition of an image. |
Not only are the phrases brought to a sharp focus and form a clear image redundant, but sharp focus is too since focus has sharp in its definition. And of course clear and sharply defined is also redundant.
So here is the revised definition:
|
When a sentence like this is entered into AI-C, it must be broken down into two words or groups of words linked together. When making such entries, we do not make entries of articles such as "a" and "the" although an article could be part of a link.
|
The underlined words are linked by the words between them:
When the entries are saved, the program will show the parts of speech for each word and the TypeOf or ElementOf, etc, so that you can click on the one you want to use.
Note that this definition contains a single fact about aberration. Sometimes you will see multiple facts about something combined into one definition. In that case, a separate set of linked entries such as the above should be created for each fact. This will be discussed further later on.
Also note that while the above looks like a phrase or sentence, it is not entered as an AI-C Phrase in which every word in the phrase is simply linked to the phrase's entry ID#.
Linking order:
The numbers in the Order boxes above determine the order in which linking entries are made. The words can be linked in any order, but it's best to link words together which are more likely to be usable in other entries.
For example, pencil of light could be used in describing a small, focused flashlight without needing the word rays. In that case, you would want to make the link between pencil and light to be 1 and the link between rays and pencil of light to be 2.
Any series of linked entries can be entered this way, not just definitions. Having a printed copy of the LinkTypes on hand may make the job easier, or if you have screen space, press Ctrl-L to bring up a list onscreen. Because the part of speech is needed for each word, as well as each word's category, if any, the program will show you the POS's and categories already set up for each word and ask you to pick.
If a word is not in the Cortex or if it is in the Cortex, but not with the POS you need, you will have to cancel the entry and make an entry to set up the word. WordID-POS linking entries may not be entered this way because the word's syllables and pronunciation must be entered, and it is just more efficient to use the red New Entry input boxes for this task.
Here is a more complex example:
Normally it is best to try to simplify definitions to as few words as possible, but sometimes there is no way to do so. Here is how I entered a definition for actuary, starting with text from Wikipedia:
|
An actuary is a business professional who deals with the financial impact of risk and uncertainty. Actuaries provide expert assessments of financial security systems, with a focus on their complexity, their mathematics, and their mechanisms.
Actuaries mathematically evaluate the probability of events and quantify the contingent outcomes in order to minimize financial losses associated with uncertain undesirable events. |
The first paragraph doesn't seem like a stand-alone definition the way the second paragraph does does. Here is how I modified it:
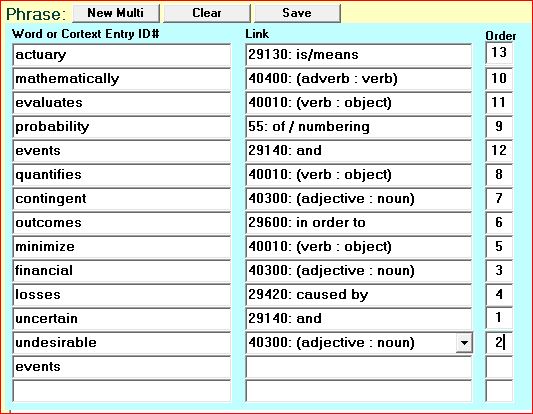
The entry numbers are not shown in the Word column. When Save is clicked, the software will display Part Of Speech and Categories for each word to allow the desired classification to be entered.
A Cortex entry ID# could be entered if the number is known. Multiple words/entries can be entered in one Word box by just entering the Cortex ID#.
When a Link name is being entered, auto-complete helps and the LinkID is entered when you tab to the next Word field. Order numbers are not entered until everything else is done.
Following is the order in which the linking entries are best made. The goal is to first link words which may are more likely to appear together in the future so that the link can be reused or which have already been linked before and that link can be used here. For example, we could link minimize financial and then link that to losses, but it makes more sense to link financial losses first.
So first we break the sentence up into phrases, then link words which are the most closely related such as adjective-noun combinations. If a noun has more than one adjective, then the adjectives are linked first, such as uncertain 2
actuary
13<one who:>
- mathematically 10<(adverb : verb)> evaluates
11<(verb : object)> probability 9<of (something)> events
12<and>
- quantifies 8<(verb : object)> contingent 7<(adjective : noun)> outcomes
6<in order to> minimize
5<(verb : object)> financial 3<(adjective : noun)> losses 4<caused by>
uncertain 1<and> undesirable 2<(adjective : noun)> events
The order of links above matters only in that it makes it easier to reuse some of these links in other entries. For example, uncertain and undesirable could describe many things besides events. On the other hand, undesirable events could be used in other situations without uncertain, so the linking order is a judgment call.
The reason for starting at the end is that you must link the last words first in order to have entries to which to link the earlier words. The parentheses in the link names indicate words which do not show up in the Links list; example: financial <(adjective : noun)> losses will appear as just financial losses in the Links list.
The above is an attempt to optimize the links, but doing so is not absolutely essential. The important thing is to get the links into the database in whatever format. Some day software should be written to examine the database and make changes itself which will optimize the links, so if the example seems confusing, don't worry about it too much, just link in whatever order you wish, or don't add linking order numbers and let the software link them.
When one Cortex entry is linked inside another one, that is a nested entry. All standard linking entries contain nested entries, one Cortext entry ID# in the Entry1 field and another in the Entry2 field. Either or both of the nested entries may link to other nested entries, but eventually, all series of nested entries end with a link to a non-Cortex entry, such as a link to the Words table or Numbers table. This structure, while simple, has the ability to store all information known to man.
For example, the text of an entire book could be entered in a single series of linked entries:
| Entry1 | Entry2 | 1. | it | was | 2. | #1 | the | 3. | #2 | best | 4. | #3 | of | 5. | #4 | times |
In the Links list, a Cortex entry looks like this (which is the first line of the block of links below):
- 126064: 126082 [L29100: 125674]
Again, Entry1 and Entry2 are just the ID#'s of other Cortex entries.
To see all the entries which make up the above entry, double-click the entry. Double-click it again to hide the details. Double-click an indented ID# to load it into the red edit boxes.
In the list below, each nested entry is indented to make it easier to see. Indented below it are the parts of the entry: Entry1, LinkID, and Entry2. If Entry1 or Entry2 is the ID# of a WordID-POS entry, then to the right of the ID is the word. If Entry1 is to a nested entry (a non-WordID-POS entry), the new entry is indented below it and looked up before continuing with looking up the first entry's LinkID and Entry2.
An easy way to see this is to look at the second line which starts with "--- 126082". As you can see, that is Entry1 of the first entry. Look down in the same column until you get to "--- L29100", which is the LinkID of the first entry. Between the two are the nested entries which start with entry #126082.

There is usually no one right way to do things. In the first entry above, gray-brown was linked to sparse bristly fur and then that was linked to and yellow and white fringes, but we could have linked gray-brown to yellow and white fringes before linking to sparse bristly fur, or we could have linked the colors to the fur and then linked sparse and bristly to that.
- red is a characteristic of some ripe apples
- yellow is a characteristic of (ripe) Golden Delicious
- green is a characteristic of (ripe) Granny Smith
- Mcintosh is a type of red apple
- Golden Delicious is a type of yellow apple
- Granny Smith is a type of green apple
For AI-C's purposes --
A characteristic is a normally permanent feature which is common to all members of a class (or set). Seeds are a characteristic of apples.
In the physical world, there are no absolutes, hence the phrase normally permanent. For example, we may say that dogs have a permanent feature (characteristic) of four legs, yet if a dog were to lose a leg, he would not stop being a dog.
But while having seeds is a normal characteristic of grapes, man has figured out how to make grapes seedless, and they have become so predominant in the marketplace that it doesn't seem right to consider seeds a characteristic of grapes any more. Instead, there are two subsets of grapes: seeded and seedless.
A characteristic of some/most members of a class is not a characteristic of the whole class. Yellow is a characteristic of (ripe) Golden Delicious apples, but yellow just a characteristic of some of the members of the class: apples.
Assume we have the following entries:
We could also link each of these colors as a characteristic of some apples, but the above entries already imply that, so making such entries would be redundant and thus a waste of disk space.
On the other hand, if only the above entries were made and AI-C needed to find out if yellow is a characteristic of some types of apples, it would have to search through all entries for types of apple (entries 1-3), then search (entries 4-6) to see if any of them are linked to yellow.
As has been discussed previously, CPU time is more valuable than disk space, so if having redundant entries reduces CPU time, then being redundant is worthwhile. So
A temporary characteristic is a non-permanent feature of a class. Example: unripe, ripe, and overripe are temporary characteristics of fruit. However, rather than linking such things as temporary characteristics, it seems more correct to me to use the (adjective : noun) link.
For modifiers such as in dish washer, where the two words make up a single common term, compound can be used as a link. Such phrases are almost all idiomatic. For example, a dish washer is used to wash more than just dishes.
A char. of no link clarifies that a feature which is a characteristic of some members of a class is definitely not a characteristic of a particular member. This can be very important. For example, fatal bite is not a characteristic of an adder snake.
- Make an entry as above but with a Link of 30940: Compound..
- Make an entry with the above entry's Cortex ID# in the Entry1 field and the compound's POS # in Link, such as:
138333: 30350:day (compound) 127632:lily.
13833x: 138333:day lily (noun) ---
Some words are linked together by general usage such that none of the specific links are appropriate. For example, hot dog is a compound when it is a synonym of frankfruter, but not when it describes an overly-warm canine.
A less obvious example is when a word is usually used with some other word. Example: account - to give an explanation (usually followed by "for"), such as account for the incident.
Note that account by itself is not a synonym of explain. We say explain the incident, but not account the incident. So account should be linked with for. They could be linked with verb - preposition, but using compound makes it clearer that for needs to be with account and that it is not just some random preposition. So use LinkID #30940, compound, then account <compound> for can be entered as a synonym of explain.
Another example: One type of account is financial. But it seems circular or redundant to say that bank account is a type of account - financial. One way to make it less circular is to use the WordID-POS entries for compound words, especially since the implication is that compound words are two words with their own meaning. So we say that bank[noun] account[noun] is a type of account[finance].
Compounds are normally given a POS, such as hot dog - noun and account for - verb A problem arises when the words need to be other noun forms like hot dogs or verb forms like accounted for or accounting for.
And some compounds are idiomatic and can't be used as other word forms. For example, you could call someone a happy camper, but the phrase doesn't work as happier camper.
How to Enter Compounds:
At one time I tried linking compound words using POS links instead of the compound link, like this:

My thinking was that this would save space; since a POS entry normally does not have anything in the Entry2 field or Entry2 WordID fields, if there is something in those fields when there is a POS link, then AI-C assumes that the entry is for making a compound word and that the POS link refers to the compound, not to an individual word.
In looking back at the entry above, even though the program may recognize what is going on, it doesn't seem obvious to me as a non-program entity.
So I'm now using this procedure (assuming the constituent words have already been individually entered into the Cortex table):
In step 1, a decision must be made as to which POS entry to use. For example, "out of" is a compound preposition (according to this page), but the word "out" can be a verb, noun, adjective, adverb, or preposition.
Some judgment may be involved is deciding which to use. In this case, it might make more sense to use the same POS as the compound, which is preposition.
Entering a contraction of one word, using o'er as an example:
| CortexID: | 100140 |
| WordID: | 62804 (the Words table's ID# for o'er) |
| Entry1: | 78160 (the CortexID# for the word over, POS=prep.) |
| LinkID: | 30930 (the LinkTypes table's ID# for contraction) |
| Entry2: | (--blank--) |
Normally, when a WordID# appears in a Cortex entry and the Entry2 is blank, then the LinkType is its part of speech ("POS"). A contraction's LinkType is 30930 - Contraction, so no POS is directly linked to the contraction. Instead, the contraction inherits the POS of the word entry to which it is linked.
The Cortex table has 5 entries for over, one for each possible POS for the word. However, o'er is normally either an adverb or a preposition. The entry above points to #78160, which is over - prep.. Entry #100141 has a Entry1# of 78161, which is the CortexID# for over - adv.. Even two entries may be overkill since a contraction virtually always links to the raw (Words table) word. It may be better to have the Entry1 actually point to the Words table ID for contractions.
Entering a contraction of two words, using aren't as an example:
| CortexID: | 8699 |
| WordID: | 4690 (the Words table's ID# for aren't) |
| Entry1: | 8697 (the CortexID# for the word are, POS=present plural) |
| LinkID: | 30930 (the LinkTypes table's ID# for contraction) |
| Entry2: | 75323 (the CortexID# for the word not, POS=adverb) |
Contractions of three (or more) words are rare, but to enter one (using a three-word contraction as an example), first make an entry linking two of the adjacent words (just using the generic link), then make the contraction entry linking the third word to the entry with the other two words.
One web site says "Dictionaries don�t all agree on the definitions of these words [acronym, initialism, abbreviation] and neither do style manuals." That site goes on to say that acronyms are abbreviations that are pronounced as words. Sounds good to me.
A later clarification is that if an abbreviation is pronounced as a word in whole or in part, it is an acronym; otherwise, it is technically considered an initialism. However, not discussed are abbreviations such as Dr. and Mrs. which are abbreviations which are pronounced like the unabbreviated word.
One significance of "acronym" versus "initialism" is that "the" is omitted before an acronym, so AI-C should say "the USA" because it is an initialism but just say NATO without a leading the. Example: JPEG is pronounced "J-peg". OTOH (an initialism for on the other hand), we might say "Did you send me the J-peg file?", so that rule doesn't seem to hold up unless you consider that the to be a modifier of file and not of J-peg.
Which is correct: "M.D." or "MD", "PhD" or Ph.D"? Again, according to that site: "there is no definitive answer... we recommend choosing your method and staying consistent." Which means that for AI-C's purposes, both should be entered as alternatives, or it might be possible for AI-C to just have "MD", for example, then if a user enters "M.D." or even "M. D.", AI-C could look for punctuation variations the way in now looks for uppercase and lowercase variations when a word entered by a user is not found.
However, if an abbreviation normally ends with a period, it should be saved that way so that when AI-C uses it as output, it does it correctly. That is, if "Evil Corp" is entered without a period at the end, AI-C will look for "corp" (without a period) and "Corp." (with a period but uppercased), but if the Words table didn't have it with a period, then AI-C would not add one when using it in output,
Entering an abbreviation or acronym ("a/a") is like making a POS entry for a regular word. Put the Word's table ID# for the abbreviation in the Word/ID field. For a regular word, we would put the root for the word being entered in Entry1 field. In the case of an a/a, the root is the word being abbreviated. Use its POS entry, not a Category entry (e.g.: If an a/a can separately represent more than one word (e.g.: ad for both advertisement and advantage in tennis), make an entry for each one.
If an a/a can represent multiple words, such as ASAP for #129676: as soon as possible, link those words together first as a phrase, then link the acronym to the phrase.
To enter a common misspelling, enter the misspelling in the Word or WordID field for New Entry. Set the Link to 31015 - misspelled/nonstandard. In the Entry1 field, add the entry ID# for the correct spelling. If the correct spelling is more than one word, link the words together and put the ID# for that linkage into the Entry1 field. For example, backorder is a misspelling of back order, so we link back and order and link backorder to that entry.
We don't want to try to enter every possible misspelling of words, especially since the spelling correction routine is so fast and accurate, but for very common misspellings, it is more efficient to enter them in the Cortex. Some become so commonplace that if you Google the word, it will not even suggest the correct spelling. An example is chewyness, a misspelling of chewiness.
Entering Definitions
Definitions of words can be entered in several different ways. As an example, here is a dictionary definition of aardvark, obtained from Dictionary.com. (The numbers were added to illustrate that the definition contains 9 different facts about aardvarks in one sentence.)
An aardvark is a (1)large, (2)nocturnal (3)burrowing (4)mammal (5)of central and southern Africa, (6)feeding on ants and termites and having a (7)long, extensile tongue, (8)strong claws, and (9)long ears.
One way to enter a definition is as a phrase. (See Phrases above and in the previous section.)
| ID | Entry1 | LinkType | Entry2 |
| #97453 | phrase | ||
| #97454 | a | link to phrase | #97453 |
| #97455 | large | link to phrase | #97453 |
| #97456 | nocturnal | link to phrase | #97453 |
| #97457 | burrowing | link to phrase | #97453 |
| #97458 | mammal... | link to phrase | #97453 |
The advantage is that this is very easy to do. You do not have to worry about coming up with the best LinkType to connect each pair or set of words; you simply link each word in the definition to the phrase's entry ID#. The drawback is that the usefulness of such an entry is very limited compared to the other methods which follow.
A second way is by creating a series of linking entries which connect each of the words:
| ID | Entry1 | LinkType | Entry2 |
| #81201 | large | [and] | nocturnal |
| #81202 | 81201 | [and] | burrowing |
| #81203 | 81202 | [characteristics of] | mammal... |
The problem with this method is that it is unnecessarily cumbersome when you get into long definitions, which brings us to...
A third (and the preferred) method is to break long definitions down into their component facts. This is simpler and more logical. Rather than list an example here, the reader is encouraged to run the AI-C Lookup program and enter aardvark to see all the entries for it. In the resulting listing, you will also see that breaking the definition into parts allows the program to arrange those parts by category so that it is easier to see, for example, all the characteristics of the aardvark, all the actions it is capable of, etc.
And as is pointed out above, Dictionary.com's definition contains 9 separate facts about aardvarks. If you link them all together, then to be consistent, as you add more facts, you should link those together with original set of links. Pretty soon you have what looks like War And Peace combined into one sentence. So the obvious choice is to break the original 9 facts (in this example) into 9 different sets of links as we have done in AI-C.
A fourth method when dealing with one-word definitions is to enter the definition as a synonym of the word. For example, one definition of accomplished (as in an accomplished pianist) is expert. You could enter this as accomplished (adj.) [a definition is] expert (adj.) or as accomplished (adj.) [synonym of] expert (adj.). Note that since both words have more than one possible POS, you have to specify the POS you want linked.
Entering Synonyms
- See if w2 has a syn-link to another word ("w2a") in which w2 is the Entry1 (not the root).
(It's okay if other words are syn-linked to w2 where w2 is the Entry2/root
since the purpose of having a root word is for all other synonyms to link to it.)- If so, tell the user and verify that w2a should be the root.
- Change the new w1-w2 link to w1-w2a.
- See if w1 has a syn-link to another word ("w1a") in which w1 is the root.
- If so, tell the user and change the w1a-w1 root to w1a-w2/w2a.
- See if w1 has a syn-link to another word in which w1a is the root.
- If so, we now have two entries (counting the new one) in which w1 is linked to different roots.
- Show the Entry1 words syn-linking to each of the two possible roots and
- ask the user which root to use ("new-root").
- Change all the old-root syn-links to a Entry2 of new-root.
- Make a new entry linking the old-root to the new-root.
- Make an entry linking w1 to the new-root.
When two words are synonymous, they are rarely synonymous for all definitions (much less all nuances of each definition) of each word; if they were, then rather than synonyms, they would be more like alternative spellings. So it is best to link as a synonym to a specific meaning of another word.
Originally, I would just link one word directly to its synonym, then I might have descriptive entries linking to each of the words individually. However, if one word is a synonym of another, all links to each word, such as characteristic of and even the TypeOf/PartOf entries, also apply to the other synonyms. So when a program is processing text and comes across one of these words, in order to interpret it, the program must look up all synonyms of the word in order to find all the entries which apply to the shared definition.
The second problem is that each word in a group of a bunch of synonymous words may each have the same or similar links going to it, which is a redundant waste of database space as well as the time needed to look up the entries and analyze them.
Instead of randomly linking any two synonyms together, choose the most frequently used word to be the "root" synonym and have each of the other synonyms link to it, For consistency, the word in the Entry2 field of a "syn-link" entry is assumed to be the root. As an example, the WordID-POS entry for peruse would be linked to the TypeOf entry for read rather than vice-versa.
If a user then tries to link any entries to peruse, the software should change the entry to link to read. When a user first links peruse to read, the software should check for any other types of entries linking to peruse and change them to link to read; but if the same link has already been made to read, then the software should just delete the entry linking to peruse.
By definition, a synonym does not share every meaning with any other word because if so, they would be linked as alternative (spelling) rather than as synonyms. Consequently, to link words as synonyms, both words should first be linked to a Type-Of, Part-Of, or definition-is entry.
Say that word "w1" in the Entry1 field is entered as being a synonym of "w2" in the Entry2 field (a "syn-link" entry).
Here are the steps the Lookup program takes:
A benefit of linking entries only to the root synonym is that it makes it clear to the user what is implied by saying that one word is a synonym of another because all the root word's links will be in the Links list when a word syn-linking to that word is looked up.
Entering city, state, country, etc.
- Make an entry for state [in] United States
- Make an entry for Arkansas [type of] [state in United States]
- Make an entry for city [in] Arkansas [type of] [state in United States]
- Hot and Springs are each entered as a proper noun and linked as a compound.
- Make an entry for Hot Springs [type of] city [in] Arkansas [type of] [state in United States]
Names usually should be entered in the Words table as individual words, such as Central and America or North and Carolina so that they can be linked to create other names such as North America.
The Compound LinkID is used to link the words in a name because we rarely, if ever, consider the words individually when using them.
In this system, every state must have an entry in the form of city in StateName and every country must have an entry for state in CountryName. The advantage of doing this rather than just saying that CityName is a TypeOf city is that the full location is shown in one set of linked entries:
- CityName [a type of] city in StateName [a type of] state in CountryName
Here is an example using Hot Springs, Arkansas, United States as an example:
Entering chemical symbols
Example: C2 H5 OH is the chemical symbol for alcohol. Here's how it is entered.
| CortexID | WordID | Entry1 | Link | Entry2 |
| 138607 | 105742: C | 19712: carbon | 30130: chemical symbol for | |
| 51618 | 113688: H | 55808: hydrogen | 30130: chemical symbol for | |
| 75693 | 120692: O | 78903: oxygen | 30130: chemical symbol for | |
| 131872 | 136702: OH | 55930: hydroxide | 30130: chemical symbol for | |
| 131867 | 105742: C | 18572: C | 7: subscript | 2 [numeric value] |
| 131868 | 113688: H | 51618: H | 7: subscript | 5 [numeric value] |
| 131869 | 131867: C2 | 30131: part of chemical symbol |
131868: H5 | |
| 131870 | 131869: C2 H5 | 30131: part of chemical symbol |
131640: OH | |
| 131871 | 131870: C2 H5 OH | 30130: chemical symbol for |
131859: alcohol |
Changing an entry
Enter the existing entry's ID# under New Entry and click Find cID# or press Enter. Then change what you wish and click on Save changes.
Changing an entry affects all other entries which are linked to the changed entry. Normally, this is what you want, but if it isn't, then you will need to take appropriate action when making such changes.
Here is an example of modifying an existing entry:
The following entry had been made:
- hairy is a characteristic of aardvark
Another source said that an aardvark's fur is coarse and bristly, so a new entry was made linking coarse (adj.) and bristly (adj.).
A second entry was made linking coarse and bristly as a descriptor of fur.
Finally, the original entry was changed from hairy to coarse and bristly fur as a characteristic of aardvarks.
Here's an example of how to track down and fix a wrong entry:
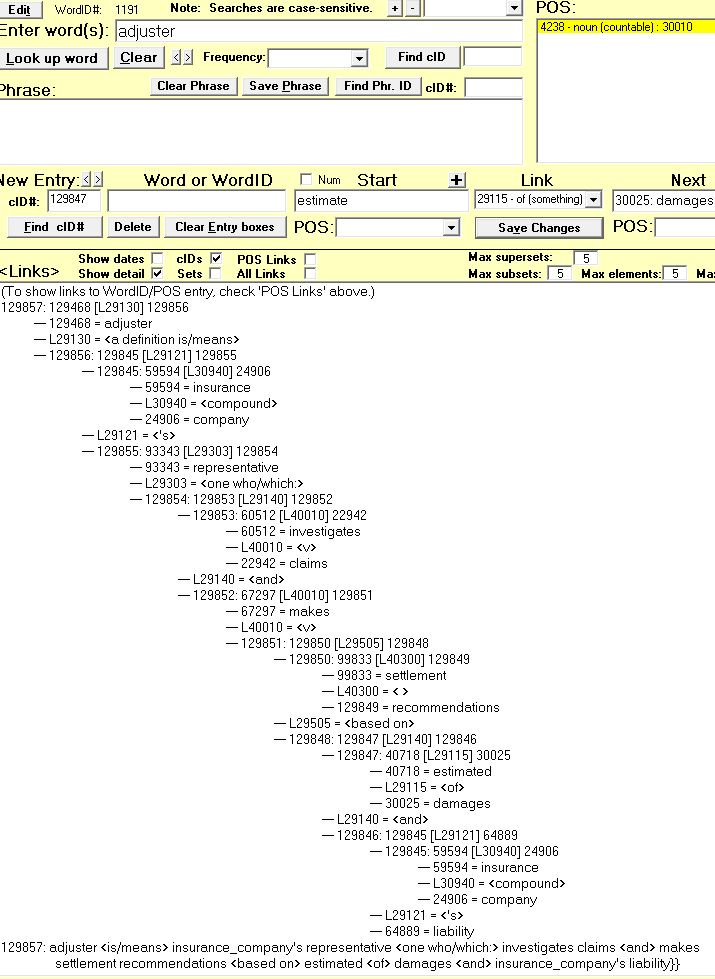
The definition of adjuster [insurance] above says "estimated <of> damages" when it should have been "estimate <of> damages". After seeing this error, I clicked on Show detail to display the breakdown by Cortex entry and in the entry editing section above, entered the cID# 129847 where the error was made. In the Entry1 field, I changed "estimated" to "estimate" and saved it.
Deleting an entry
Under Entries, enter the cID# of the entry to be deleted and click on Find cID#. Next to that button will appear a Delete button which you can click to delete the entry.
If you try to delete an entry whose ID# is used in some other entry, AI-C will tell you that the other entry must remove that link first.
Numeric and date entries
- Link month <of> year first so that it can be used for each month.
- Make an entry with entry 1 above in Entry1, LinkID# 2 <seq.#>, and the number 3 in Entry2.
This results in the string: month [of] year <seq.#> =3
which the software translates to 3rd month <of> year - Make an entry with entry 2 above as Entry1, link of [characteristic of], and Entry2 as March.
which displays as [3rd month <of> year] <characteristic of> March - larger numbers
- numbers with decimals or
- rounded numbers
- numbers with modifiers (descriptors)
- The default format is YYYYMMDD. For example, June 23, 2010 would be 20100623. When the entry is displayed, the entry would be converted to a standard date display format, such as 06-23-2010 (or if you write your own code, you can make the format whatever you wish).
- If a number is only 7 digits, it is assumed that the year is one prior to 1000. For example, 8490421 would be 04-21-849.
- Likewise, if a number is 6 digits, it is assumed to be a date prior to 100, such as 490421 being 04-21-49.
- If 5 digits, the date is prior to 10 such as 90421 being 04-21-9. The reason for this is that even if you enter the number as 0890421, when read back, the leading 0 would be dropped by the programming language.
- 1 or 2 digits indicates the day of a month in ordinal format, such as an entry where
129188:July is the Entry1, 4:Date is the LinkID, and 4 is in the Entry2 field. AI-C displays this as July 4th.
Link #2 is also an ordinal number, but the number is displayed first, such as 3rd letter, not letter 3rd
Integers which are small enough to be stored in the Entry2 field are stored there using LinkID#s 1-9.
More complex numbers (including dates) are stored in the Numbers table.
A record in the Numbers table consists of the following fields:
- ID#, Num1, Num2, Precision
When creating an entry for the Numbers table, a Link ID of from 10 to 899 is used. Three drop down list boxes are shown for selecting Precision specifications. These are discussed below.
The thing(s) to which the number applies goes in the Entry1 field, and the numeric data goes in the Entry2 field.
Obviously, every number entry must have at least one number. The second number field is for entering ranges, one number plus or minus a second number, and so on, as discussed below.
LinkID#s under 10 (in the LinkTypes table) indicate that the number in an entry's Entry2 field is numeric data (rather than a Cortex or Number table entry ID#). Since the Entry2 field is a long integer, it is accurate up to 2,147,483,647, but it does not allow decimals nor any of the special formatting options described below which are for LinkID#s 10-899.
Example (neutral pH = 7):
| ID | Entry1 | LinkID | Entry2 |
| 126473 | neutral | (adj.: noun) | pH |
| 126474 | 126473 | 1 | 7 |
LinkID# 2 is a sequence # such as 1st, 2nd, etc. This is also known as an ordinal number. The best way to record a sequence number is as follows in this example for March is the 3rd month of the year.
To do April, make an entry with [month <of> year <seq.#> 4] <char.of> April
which displays as [4th month <of> year] <characteristic of> April
and so on for each month.
The same format is used for [1st day <of> week] <characteristic of> Sunday
LinkID#s from 10 to 899 indicate that the Entry2 field contains the ID# of an entry in the Numbers table. By storing numbers in the Numbers table, you can save...
Example (acidic pH = less than 7):
- Since the Entry2 field can only hold a single number with no modifiers
and we want to enter "<7", we have to use the numbers table:
-
Cortex table:
| ID | Entry1 | LinkID | Entry2 |
| 126475 | acidic | (adj.: noun) | pH |
| 126472 | 126475 | 10 | 18 (pointer to Numbers table entry) |
| ID | Num1 | Num2 | Precision |
| 18 | 7 | - | < |
If a LinkID between 10-899 is entered in the New Entry's Link box, then when you exit that box, three drop-down list boxes appear under the Entry2 box. You can leave those boxes as-is, or drop down the lists and pick codes which you want to enter, then in the Entry2 box, enter a single number or two numbers separated by a comma.
The third drop-down list box lets the user choose whether to save the number(s) in metric or decimal format (or other American formats, such as Fahrenheit vs. Celsius , PSI vs. bars, etc.).
Giving all such entries LinkID #'s under 900 makes it easy for the program to recognize an entry in which the Entry2 is not a pointer to a Cortex entry but to a Numbers table entry.
Note that more than one Cortex entry can point to the same Numbers table entry. If one of the Cortex entries subsequently changes the value of the Numbers table entry, the software making the change should check to see if other entries link to that Numbers table entry and offer to create a new entry with the changed data while leaving the original entry as it is..
Entering a Numbers table ID#: If you know a Numbers table entry ID number, you can enter it in the Entry2 field preceded by a "#", such as "#34" for Numbers table entry 34.
When AI-C looks up an entry in the New Entry area, it will display it like this:
- "#34: 95, 115" in the Entry2 field with "c" in the first drop down Precision list and "r" in the 2nd.
In the Links list box, it would be displayed as part of an entry as "...95 - 115 centimeters...".
When you enter a number like 123456789000987654321, you are just entering text. It is not a number yet. This text is split (by the software) into two parts of up to 15 digits each, such as 123456789000 and 987654321, then saved as numeric data in Num1 and Num2 of the Numbers table. A number of less than 16 digits can be stored in a single field, Num1.
When you call up a Numbers entry for display, if it is a number which was split into two fields, the two fields are converted from numeric data back to text and concatenated, unless the LinkID indicates they are two separate numbers, in which case they are not concatenated.
When concatenating two numbers, the second half of the number (in Num2) cannot start with a zero because any leading zeros would be lost when converted back (e.g.: if you convert the text "003" to a number, then when you convert it back to text, you just get "3"). If you split the above number into 123456789 and 000987654321, when you converted it back from numeric data, you would get 123456789 and 987654321, which combined would be 123456789987654321, which is not the number entered.
If the original number is 123456789.000123456789, then it can be split into 123456789 and .000123456789 because the decimal holds the zeros in place. However, when that number is converted back to text, you would actually get 0.000123456789 which is not a problem because the software can just remove the 0 before the decimal.
The Num1 and Num2 fields can also store two different numbers, such as a numeric range like 525 - 580 or 10150 ± 10 or 200 with standard deviation of 3.
Numeric data for Link ID#s 200-299 can be saved in metric or decimal format using the third drop-down list box. When viewing an entry in the New Entry boxes which has one of these Link ID#s, a check box appears above the Entry2 box with the caption Metric.
You can change between metric and decimal display in the Entry2 box by checking or unchecking the box.
The Numbers table can also be used to store date and date-time formats
LinkType ID# 4 indicates that the the number in the Entry2 field is a calendar date.
LinkType ID# 100 is also in the format YYYYMMDD, but is saved in the Numbers table. Since the date in this format fits in the Entry2 field, the only reason to put it in the Numbers table would be to also use one or both Precision fields described below.
LinkType ID# 5 and 110 indicate that the time is stored as HHMMSS, where HH is the hour portion of the time in 24-hour format, ID# 5 saves the number in the Entry2 field while #110 saves it in the Numbers table with the Numbers entry ID# saved in Entry2 field. The only reason to use #110 would be to add fractional seconds in the format: "HHMMSS.sss..." or to use other Precision characters.
LinkType ID# 120 indicates that the date and time are stored as YYYYMMDDHHMMSS.sss... (optionally ending in fractions of seconds). November 3, 2009, 3:01:29 p.m. would look like this: 20091103150129. The date's number is stored in Num1 and the time, down to fractional seconds, in Num2.
Obviously, when retrieving this, a program would have to convert the numbers to a more readable form, such as 2009-11-03 15:01:29 or the 15:01 could be changed to 3:01 p.m.
Date and/or time entries should be recorded in Greenwich Mean Time, which can easily be adjusted by software to whatever time zone is needed. For example, if you are in the Central time zone and want to store the time 1:52 p.m., you would first convert it to 24-hour format: 13:52, then you would add 6 hours to get GMT of 19:52. When Daylight Savings Time is in effect, you would add 5 hours instead of 6. If you convert 2010-02-28, 22:15:00 CST to GMT, you would get 2010-03-01, 04:15:00 because adding 6 hours has moved into another day.
An important part of entering information about plants is what balance of fertilizer they need, such as 24-2-8 where the first number is the % of nitrogen in the mix, the second number is phosphorus, and the third number is potassium. ("Up, down, and all around" - nitrogen promotes vegetation growth, phosphorus encourages root growth and fruit/flower production, and potassium is for overall plant health.)
The Numbers table only has two fields for numbers and there are three numbers in the specs. The numbers could be split over 2 or 3 Cortex entries using LinkID# 1, but that seems inefficient.
I at first tried putting one number in the Num1 field and the next two numbers in the Num2 field divided by a period, such as 24, 2.8. Using LinkID #90, Fertilizer, let AI-C know how to divide the numbers up.
But there is no reason not to put the specs in a Words table entry. Doing so doesn't take up any more space than putting the specs into Numbers table entries. Plus, when entering the Words table entry into the Cortex, the pronunciation can also be entered, such as twen'tEE-fAOr-tEW-AEt.
While fertilizers may come in a wide variety of mixes, they usually conform fairly closely to one of a few ratios. For example, if a ration of 1:1:1 is specified for a plant, then 13:13:13 could work.
Numeric precision/format indicator codes
The Precision field in the Numbers table indicates the degree of precision or confidence in the numbers, or the format of the numbers. The International System of Units has an official set of prefixes which is, for the most part, what is used below.
You do not have to try to remember all of this because when you enter a LinkID of less than 900, drop-down list boxes appear which contain these codes.
deci = tenth (10-1 = 0.1)
centi = hundredth (10-2 = .01)
milli = thousandth (10-3 = .001)
u=micro = millionth (10-6 = .000 001)
nano = billionth (10-9 = .000 000 001)
pico = trillionth (10-12 = .000 000 000 001)
femto = quadrillionth (10-15 = .000 000 000 000 001)
atto = quintillionth (10-18 = .000 000 000 000 000 001)
zepto = sextillionth (10-21 = .000 000 000 000 000 000 001)
yocto = septillionth (10-24 = .000 000 000 000 000 000 000 001)
Kilo = thousand (103 = 1 000)
Mega = million (106 = 1 000 000)
Giga = billion (109 = 1 000 000 000)
Tera = trillion (1012 = 1 000 000 000 000)
Peta = quadrillion (1015 = 1 000 000 000 000 000)
Q = quintillion (1018 = 1 000 000 000 000 000 000)
Zetta = sextillion (1021 = 1 000 000 000 000 000 000 000)
Yotta = septillion (1024 = 1 000 000 000 000 000 000 000 000)
O = octillion (1027 = 1 000 000 000 000 000 000 000 000 000)
N = nonillion (1030 = 1 000 000 000 000 000 000 000 000 000 000)
D = decillion (1033 = 1 000 000 000 000 000 000 000 000 000 000 000)
The codes above are just in the first drop-down list; those below are in both.
Note that the following do not do any math.
They indicate to software what to do and/or how to interpret the numbers.
[blank] = as entered
| R | Rounded |
| & | the sequence of numbers after the decimal place in the format entered repeats
For example, 1.3 with Precision = & is 1.3333333. |
| A | Average |
| ~ | approximate (roughly �10%) |
| e | rough Estimate (may be �20%) |
| ? | very rough estimate (�30% or more) |
| V | very exact |
| x | not equal to |
| > | greater than |
| < | less than |
| ± | num1 plus or minus num2. [In Windows, ± is CHR$(177) or press Alt-241] |
| r | range of numbers; if only 1 number it means "up to and including" (e.g.: "up to and including 5") |
| % | percent |
| + | plus |
| - | minus |
| / | divide by |
| \ | integer divide by |
| * | multiply by |
| ^ | to the power of |
| v | root (as in square root) |
| m | mod (as in 5 mod 2 = 1) (In 2nd list only.) |
| ! | factorial |
The third drop-down list box contains units of measure in English and metric systems. Normally, software would use whichever unit of measure would result in the smallest number over 1, such as saying 4 yards rather than 12 feet, but there can be cases where you would want to override this. In construction, it would be normal to refer to a building as being 50 feet wide, not 16.67 yards.
So use this list only when the number(s) given are not to be converted to another unit of measure.
Codes in the third list (below) may have a different neaning than in the first two lists, as noted below). Codes i, f, y, and m should be used with Links indicating distance. Codes o, p, t, g, K, and T should be used with Link ID #270 - weight or #280 - mass/density.
| i | inches |
| f | feet (femto in list 1) |
| y | yards |
| m | miles (milli in list 1, mod in list 2) |
| o | ounces |
| p | pounds (pico in list 1) |
| t | tons |
| O | fluid ounces (Octillion in list 1) |
| C | cups |
| P | pints |
| Q | quarts |
| G | gallons |
| M | milliliters (Mega in list 1) |
| L | liters |
| g | grams |
| K | kilograms (just Kilo- in list 1) |
| T | metric tons |
| N | North (latitude) (Nonillion in list 1) |
| S | South (latitude) |
| E | East (longitude) |
| W | West (longitude) |
One, two, or three codes can be used in one entry. For example, 525 with codes K~ means about 525K. Entry with 675, 700, ~ r means about 675 to 700. Entry with 40, 82, ~ r K means about 40 to 82 kilograms with a link of 270:weight.
V A numeric code such as 100G means that the number is likely rounded, though not necessarily. To make it clear that such a number is not rounded, add V, such as 100GV. This is uppercase V. Lowercase v is root.
[blank] = just a normal number. Take the number at face value. The number is generally accepted as fact, but is not gospel. The V code is used to indicate stronger belief in the accuracy of a particular number.
R is used for rounded numbers when you do not want to use one of the other codes. Examples: the result of 10/5 would be entered as 2 with blank Precision, but the result of 10/3 would be entered as 3.3 (any number of places you wish) with a Precision of R indicating that the .3 is rounded or it could be entered as 3.3 with & in the Precision field, indicating that the 3 after the decimal repeats infinitely, as explained next.
& indicates that the string of digits after the decimal place in the format entered repeats. For example, 1 divided by 7 is 0.142857142857... where 142857 keeps repeating. It should be entered as 0.142857 with a Precision of &.
The result of 1 divided by 14 is .0714285714285... where the 714285 keeps repeating, but not the 0 at the start. You cannot just add & to it because that repeats all digits after the decimal, including the 0, so instead enter 0.714285 d& where the d indicates that the decimal has been moved one place to the right and the &, that the 714285 repeats infinitely.
The result of 1 divided by 28 is .03571428571428... which is 3.571428 c& where the c indicates that the decimal has been moved two places to the right and & says the 571428 repeats.
Average needs no explanation, but see Standard Deviation below.
± (plus or minus) requires two numbers to be entered. In the Lookup program, the two numbers are entered in the Entry2 field, separated by a comma, such as 10, 2 which is 10 ± 2.
range can use two numbers, but if only one is entered, the "r" means "up to" the number entered. "r" is used instead of "-", because "-" is used for minus.
The other codes should be self-explanatory.
- The year is evenly divisible by 4.
- The year is NOT evenly divisible by 100 unless it is also evenly divisible by 400..
- Non-integer division: 2017 / 4 = 504.25
- Integer division: 2017 \ 4 = 504
- Non-integer division: 1964 / 4 = 491
- Integer division: 1964 \ 4 = 491
- 176707: aspartame <is (x) times> #97: 150,200 r
When AI-C sees LinkID#65, it substitutes Entry2, the Number tables entry #97, for "(x)". - 176708: sweeter <adj. {than} noun> sugar
The Link adj. {than} noun says that only the word(s) in curly brackets are shown. - 176709: 176707: <(adjective : noun)> 176708
The Link adjective : noun has parentheses around it, so it is not shown.
Plus (+), minus (-), divide (/), integer divide (\), multiply (*).
You cannot enter something like /4 in the Entry2 field to indicate division by 4 because only numbers can be saved. Instead, enter 4 and select the / function from the drop-down list.
The Cortex itself cannot perform calculations. Instead, calculations must be performed by software and compared to the expected results specified in the Cortex.
Here is an example which specifies how to determine if a year would be a leap year.
The rules for calculating if a tear is a leap year are:
A number is evenly divisible by another number if the result of integer division with them is the same as the result of non-integer division. (Integer division rounds the results and non-integer division does not.)
- Examples:
The year 2017 is not evenly divisible by 4 and the year 1964 is, so 1964 meets the first specification above for being a leap year while 2017 does not.
In order for the Cortex entries to apply to any year, we use a variable for year number. In AI-C, a variable is denoted as being the text of any entry in the Words table which starts and ends with "=", thus Words table entry ID# 136614 =year(####)= is a variable for a year in the format like 2016. (Variables are not just numeric. For example, 127997: =place=" represents any place, 126502: =verb= represents any action, etc.)
The Words table entry is incorporated into the Cortex with entry
ID# 129268: WordID#136614: =year(####)= LinkID# 30290: variable.
Of course, the Entry1 field in the Cortex only has the ID#; the text from the Words table is shown here for convenience.
| ID# | -------Entry1#------- | LinkID | Entry2 | |
| 129269: | 129268: =year(####)= | 10 (#) | / 400 | |
| 129270: | 129268: =year(####)= | 10 (#) | \ 400 | |
| 129271: | 129269 (year / 400) | 18120(=) | 129270 (year \ 400) --- Evenly divisible by 400. | |
| 129272: | 129268: =year(####)= | 10 (#) | / 100 | |
| 129273: | 129268: =year(####)= | 10 (#) | \ 100 | |
| 129274: | 129272 (year / 100) | 18125(< >) | 129273 (year \ 100) --- Not evenly divisible by 100. | |
| 129275: | 129268: =year(####)= | 10 (#) | / 4 | |
| 129276: | 129268: =year(####)= | 10 (#) | \ 4 | |
| 129277: | 129275 (year / 4) | 18120(=) | 129276 (year \ 4) --- Evenly divisible by 4. | |
| 129278: | 129274 (not =/ by 100) | 29150(or) | 129271 ( =/ by 400) --- where "=/" means "evenly divisible" | |
| 129279: | 129277 ( =/ by 4) | 29140(and) | 129278 (not =/by 100 or is =/400) | |
| 129280: | 129225 (leap year) --- | (is/means) | 129279 |
Entry 129279 defines a year which
is evenly divisible by 4 <and> not evenly divisible by 100 or is evenly divisible by 400
This was the rule we started with above for calculating leap years.
You do not have to remember these codes when using the AI-C Word Lookup program. They can be found in drop-down list boxes. I have tried to avoid using characters which would require the installation of a particular Windows character set. The only oddball is ±, the symbol for plus or minus, and then only because I could not think of a reasonable alternative. That symbol is part of the standard font in Windows 7, but I don't know about other systems.
I would like to have added ≤ (less than or equal to) and ≥ (greater than or equal to), but I could not come up with a good one-character symbol for each, and they are not part of the standard Windows character set. (They only appear in a browser thanks to HTML code.) So if you would have said ≤ 400, then you have to say < 401, which may not read as well, but mathematically is the same thing. Or you can use LinkIDs 40 (less than or equal to) and 45 (greater than or equal to) for those.
IF YOU ADD CODES to the list above, keep in mind that all these codes relate to the accuracy and/or format of the numbers and not to units of measure. The codes should apply to all units of measure. Units of measure, such as pounds, liters, light years, etc., are indicated in the LinkTypes table (entry ID numbers under 1000) rather than as codes in the Numbers table.
This section is presented as an example of how various math functions can be added.
When an entry has a LinkID# 15 (standard deviation), its Entry1 points to another CortexID entry which has the average number, and its Entry2 points to a Numbers table entry which has the standard deviation number.
Example:
Cortex table entries:
| ID | Entry1 | LinkType | Entry2 |
| 100001 | 37690 | 10 - number | 7721 |
| 100002 | 100001 | 15 - std.dev. | 7722 |
Numbers table entries:
| ID | Num1 | Num2 | Precision |
| 7721 | 500 | Average | |
| 7722 | 25 |
Entry #100001 links Cortex entry #37690 (which could be anything which can have a value associated with it) to the Numbers table entry #7721 via the LinkType ID# 10. In this example, the value in entry 7721 is 500, and the Precision code of A indicates that 500 is an average.
Entry #100002 links Cortex entry #100001 to Numbers table entry #7722 as indicated by LinkType ID# 15, which is the LinkType for standard deviation, which is 25 in this example.
The sum of all this is that when you enter text which ultimately links to entry #37690 (a made-up entry for this example), it would use the (also made up) entries above to display:
- [37690's text] = an average of 500 with a standard deviation of 25
A Tough Situation:
When entering the word aspartame, a source said that it is 150-200 times sweeter than sugar.
I added LinkID# 65: is (x) times and made these entries:
This displays as
- 136894: aspartame <is 150-200 times>
136892: sweeter <than> sugar
I don't want to add new LinkTypes for every situation that arises, but this illustrates that making entries is seldom easy, and in this case, I could not think of an alternative.
I did NOT add a link for "# times less than". To me, it is illogical to say that 20 is "3 times less than" 60. Three times what? The most logical interpretation is that 20 is a number which is 3 times that number less than 60, but 20 is 40 less than 60, which is just 2 times 20, so the logic escapes me.
Apparently, when people say "20 is 3 times less than 60" what they really mean is that "20 is a number which taken 3 times equals 60". I guess. Anyhow, we can avoid the problem by using LinkID#65 to say that something is more than something else by n rather than something is less than something else by n..
This is really easy when reading text since "a is 3 times less than b" simply switches to "b is 3 times more than a".
Entering cities
-
Example: Montgomery <type of> city <in> Alabama <type of>state <element of> United States <type of> federation
- ##### = Cortex entry ID# for name of city or town
- 29010 type of
- 131529 city [type of government]
- 5000 in
- ##### = Cortex entry ID# for the following:
(Cortex ID#) ##### name of state (could put county/parish first)
29010 type of
131481 state [element of] United States [type of federation]
See a complete list of states with their ID codes
Entering plant data
-
Because there are so many plants, their entries should be uniform, so the formats are for different types of entries are listed here (where "X" would be the name of a plant). Use the Cortex ID# shown.
- fertilize X <in/during time period> ...
- <1075: after> bloom
- 105489: spring
- 137822: early spring
- 135428: late spring
- 138107: summer
- prune X <in/during time period> ...
- <1075: after> bloom
- 105489: spring
- 137822: early spring
- 135428: late spring
- 138107: summer
- 138106: fall
- 138108: winter
- 135362: bell-shaped flower
- 137424: discoid and radiate flower head
- 38476: elongated
- 132403: round flower
- 137819: trumpet-shaped flower
- 138562: tubular flower
- 138561: ovate (shaped like egg)
- 138555: ternate (three divisions or leaflets)
- 138515: blue 137889: blue flower
- 138482: brown 138580: brown flower
- 138586: cream 138587: cream (colored) flower
- 133793: green 138581: green flower
- 138577: lavender 138578: lavender flower
- 138572: pink 138579: pink flower
- 138574: purple 138580: purple flower
- 138302: red 138410: red flower
- 138575: reddish 138583: reddish flower
- 138589: scarlet 138590: scarlet flower
- 127655: violet 138588: violet (colored) flower
- 123362: white 138570: white flower
- 125003: yellow 138584: yellow flower
- 125017: yellowish 138580: yellowish flower
- [[(color 1) and/or (color2) and/or (color 3, etc.)] flower] <characteristic of> X
- 126071: perennial ...
- 133880: annual ...
- 13330: biennial ...
- 53591: herbaceous ... (no woody stems)
- 132409: herbaceous perennial
- 41188: semi-evergreen
- 137832: evergreen or semi-evergreen ...
- 138007: dormant during <in/during time period>
- 138107: summer
- 138108: winter
- 135416: hardiness zones <10: number> #, # (example: 3,8 with "r" for "range" = "3 - 8") ...
- 137894: hardiness zones 3-10
- 138421: hardiness zones 7-10
- 136136: aromatic ...
- 135411: deer resistant ...
- 135396: dry soil
- 138406: normal moisture (1" per week)
- 138407: wet soil
- 138408: plant in water
- 135421: drought tolerant ...
- 135386: full sun
- 137354: part sun
- 137356: part sun <or> full sun
- 138386: morning sun <and> afternoon shade
- 135388: part shade
- 135390: full shade
- 135394: part shade <or> full shade
- 138387: part shade <or> part sun
- 135392: part shade <up to or equal to> full sun
- 137854: full shade <up to or equal to> part sun
- 135393: full shade <up to or equal to> full sun
- 138549: ... crown division ...
- 94560:: ... rhizomatous
- 138413: ... runners ...
- 138368: ... seed ...
- X <width> # - # (default is meters)
- X <height> # - #
- 137840: foliage <height> 2 - 4 inches <characteristic of> X
- 138431: scale
For example:
-
fertilize X <in/during time period> 105489: spring
138562: tubular flower <characteristic of> X
Action::
Flower shapes <characteristic of> X:
Leaf shapes <characteristic of> X:
Colors:
Characteristics of plant X:
X <prefers or needs> (moisture)...
X <prefers or needs> (sun)...
Propagates <by means of> ... <characteristic of> plant X:
Measurements:
Diseases and Pests:
External Reference menu
- Acronyms
- Dictionary.com
- Idioms
- MacMillan Dictionary
- Oxford Adv. Amer. Dict.
- Pictures
- Thesaurus
- Urban Slang dict.
- Wikipedia
- Wiktionary
- Phrases
- Grammarist
- Pronunciations
The external reference menu has these options for looking up the word in the Enter word(s) box:
Click any of these menu items to look up the entered word at the specified web site and display it in a browser window. You will need to modify the code to point to your web browser of choice.
OneLook is not a dictionary but it provides a list of links to many dictionaries and other types of reference tools. It doesn't appear to be possible to pass a word to it, so you have to manually open the site and enter the word when the page comes up. OneLook supports wildcards and also has a reverse look-up where you enter all or part of a definition to find the word.
Tools menu
- The ideal match would have a first digit of 1 (only 1 change needed to match the word entered) and also have a frequency rating of 1 or 2, but
- If no such entry exists, then the code looks for the first entry with a first digit of 1 or 2 and a frequency rating of 1 or 2, and
- If found, the code makes it the first entry.
Example: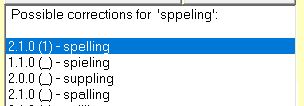
When "sppelling" is entered, "spieling" is the closest match, but it has a blank frequency rating. Ideally, such a word should have a frequency of 3, which is "rarely seen". A blank means that no frequency has been entered for the word, so we downgrade it to 3.The word "suppling" has a first digit of 2, meaning it would take two changes to it in order to match the word entered, but it also has a second digit of 0, meaning that the consonants match exactly, so it would also normally rank above "spelling", but again, "spelling" has a better frequency rating so it comes first.
But if "suppling" had a frequency rating of 2, it would come before "spelling" because there is not a huge difference in frequency between 1 and 2 as there is between 2 and 3, so the other ratings would take precedence.
Prints the current word, POS list, Categories list, and Links list.
Spell corrector
If you enter a word and press Enter, the program will look up and display the Cortex entries for it. If the word is not in the Words table, AI-C will assume it is a misspelling and display a list of suggested corrections. You can also click Spell Corrector in the Tools menu (or press Ctrl-S) to get a list of suggested corrections for a word that is in the Words table, but was not the intended word.
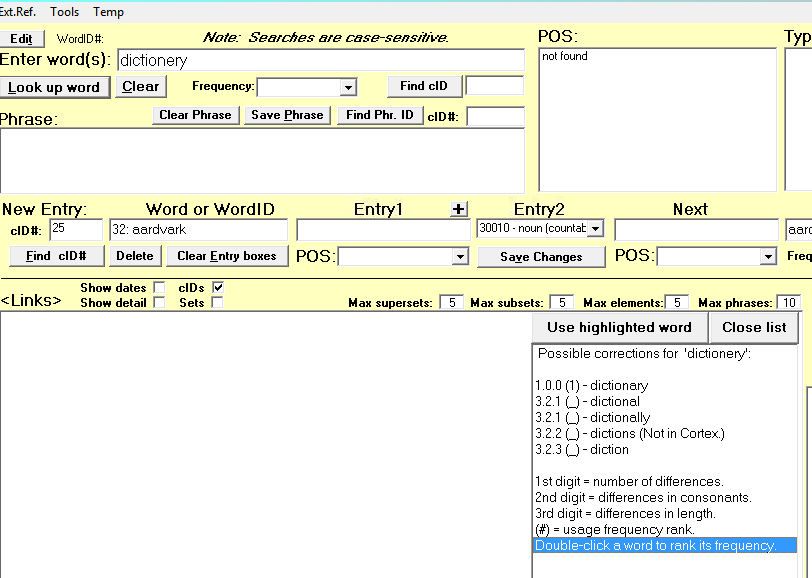
The list of words is ranked first by the number of changes required to get from the entered word to each suggested correction. Example: dictionery needs one change to get to dictionary and three changes to get to dictional.
The second digit is the number of edits to get from the consonants in the entered word (dctnry to the consonants of the suggested word. The digit after the next decimal is the difference in the length of the suggested word and entered word. The number in parentheses is the frequency ranking.
An exception to the ranking ordered just described is as follows:
Text entered may actually be two or more words run together, so the program lists all ways the entered text can be split into smaller words. Example: grandfatherclock can be split into grandfather clock and grand father clock. At some point, grandfather clock will be linked in the Cortex and the words grand father clock will not, so we would choose the former.
Another reason that a word may not be found in the database is if someone makes up a word by adding a common affix (prefix or suffix) to an existing word. The routine FindAffixes will check for such affixes and if it finds an affix tacked on to a word in the database, it will let you know and will add it to the list of suggestions.
A blended word (or portmanteau) combines all or, most often, just parts of two words to make a new word. Many now common words, such as brunch (breakfast + lunch), are actually blended words. Anyone can make up a blended word, but most of the time their meaning is not obvious, so until a word is in wide circulation, there is little point in using it since few people, if any, will get its meaning. For example, most people will not know what smaze is (smoke + haze) because even though it has seen some use for quite a while, it has not reached a critical level of usage needed to make it instantly recognizable by most people. In contrast, smog (smoke + fog) is a portmanteau recognized by most people.
Another problem is that there can be tens of thousands of words which might possibly be combined to form a particular blended word. Take brunch -- Over 1000 words in AI-C start with "b" and about 20 end with "unch". You would think that context would help, and it would if we knew for certain that a word was blended, but we don't, so we could spend a lot of time trying to come up with a blended word combination for what is simply a misspelled word. There is just no way to come up with a likely candidate for the actual combined words for most blended words, so AI-C doesn't try.
Look up Homophones
Homophones are words which are pronounced the same but have different meanings and often have different spellings. Example: red and read (past tense).
Rhymes
Displays a list of words which rhyme with the word in Enter Word(s). When you click the button, a box drops down and displays some options for you to select, then click Get Rhymes to view the rhymes.
Click here for more information in Wikipedia about rhymes and the options presented.
Rhyming functions may not do anything for NLP, but makes it easy to put together phrases like:
I got a pleasant peasant a present of a pheasant, for whatever that's worth.
If a word has more than one pronunciation, AI-C uses its first one when looking for rhymes. If you want to rhyme a different pronumciation, enter a different word with the sound you want. For example, if you enter "read" it will look for words rhyming with "rEEd". If you want words rhyming with "read" in the past tense (as in Yesterday the book was read.) enter another word which rhymes with it, such as bread.
Unscramble jumbled letters
Unscramble jumbled letters to find real word(s) or multiple real words which use the same letters. This may be of no use to an NLP program, but it was a simple routine to add, so here it is.
Some newspapers have a jumbled word game, or you can try it here.
Enter word frequency
A usage frequency can be entered for each word in the Words table, as well as for each entry in the Cortex.
A menu option used to be available which would bring up a box for entering word usage frequency ratings, but now it can be done using the word look-up box and the frequency box below it.
See Frequency for more information.
Links table
Entering new links or deleting or changing old ones is a risky business because the source code and the program documentation may reference individual Link ID#'s or even worse, range of ID#'s (worse because an individual number is easy to find and change but finding ranges pretty much requires manually going through the files).
The Cortex table also must be changed when LinkID#'s change, but that is simply a matter of search and replace; nevertheless, all of these files should be backed up before making such changes.
As this is being written, Link ID#'s 30010-30035 are various forms of nouns. Say that you want to add a new noun category. If you give it the number 30000 or 30036, it will not be included in any computations in which the source code is looking for ID#'s 30010-30035 (obviously).
If a LinkID# is not used in the Cortex, deleting the LinkID# is not a problem, but if any entries are using the LinkID#, you must first either delete the entry or entries using the number, or you must either change the old number to a new one rather than deleting it or you must change the entries to a different number first.
Word endings
The function of the menu option was replaced by using wildcards in the Words lookup box. For example, enter *ity to see a list of words ending with ity.
This option will display a list of all words in the Words table which end with the specified letters. You can also add two sets of characters which, if they come before the specified ending letters in a word, the word will not be listed.
For example, if the specified ending letters are ility, you will get a long list of words ending in those letters. You could then winnow out some of that list by entering "ility, t", which causes it to skip words ending in tility. If you entered "ility, t, ab", it will also skip any words ending in ability
The main use of this function is to manually examine common word endings to see what changes must be made to a word when removing the ending to get back to the root word. The routine FindRunOns is used to examine a user-entered word which is not in the Words table and split it into multiple words. So if the input text has veryrarely, the routine will split it into very and rarely.
Let's say we are parsing the text: "I loved the realisticity of this movie." We find that realisticity is not in the Words table, nor does it divide into multiple words which are all in the Words table. But the sub FindAffixes will convert a word ending in ity back to its root word. In this case, all we have to do is drop the ity to come up with realistic, which IS in the Words table.
So even though realisticity is not a good word, we can derive the meaning of this non-word from the real word. And since adding "ity" to an adjective makes it into a noun, we know that the writer was using the non-word form of the adjective realistic as a noun.
The methods used in Sub FindAffixes came, for the most part, from studying a list generated by the Word endings option.
Categories List
Ideally, every WordID/POS entry linking a word into the Cortex should then be linked as a Type Of or Element Of some other entry if it is a noun or Relates To if it is some other part of speech.
There are no restrictions on what a word can be linked to, but when there is a choice of similar words to which to link, the same one should always be used. For example, do not link wing to aircraft and then link engine to airplane.
This list lets you see what words have already been used to help avoid such duplication. At some point, it would make sense to add code to check to see if a category link is to a word which is a synonym or POS of another word and use the "root" word as the category instead.
The Category List starts with Type Of categories, the Element Of categories, then Relates To links. Double-clicking a word in the list brings up a list of words which link to the selected category.
Variable Words List
Words with equals signs before and after them, such as =someone= are called Variables.
Example: admit <(verb : object)> =someone= <to> =something=.
If a sentence has admit Sam to the party, it could plug it into the entry above and follow that entry's links.
As with most things about AI-C, you can add variables if you wish and use them however you want, though of course you also have to write NLP code to use them.
Shortcuts
- Pressing [+] will add the word in the Enter Word(s) box to the list.
- If a word is displayed in the list box, pressing [<] will put the word into the Enter Word(s) box and look up the word.
- Selecting a word from the drop-down list will put it into the list box and into the Enter Word(s) and look it up.
- Pressing [-] will remove the word from the list.
- Above the cID# box, click < and > to scroll entries down and up by ID#. If the New Entry boxes are empty (after pressing Clear Entry Boxes, for example), press > to display the last entry added (highest cID#)
- Double-click the Entry1 caption to copy the current cID# to the Entry1 box for a new entry.
- Double-click the Entry2 caption to copy the current cID# to the Entry2 box for a new entry.
- When entering a new POS entry, a button will appear on the right end of the input boxes which will offer to make new forms of the word just added, such as a plural for a noun or various forms of verbs.
- Double-click in the Entry2 box to display a list of entries which use the same Link-Entry2 combo. Both the Link and the Entry2 fields must have ID numbers and words in them (e.g.: "29010 - type of" and "79135: pain").
Enter Word(s):
-
The [<] and [>] buttons scroll through the words in the Words table starting from the word currently shown in the Enter Word(s) box. For example, if alternate is in the box, pressing [>] will display alternated.
The brings up a list of words following the current one:
Click Scroll up or Scroll down or press PageUp or PageDown on your keyboard to see more words. Click a word to make it the current one or click on the Word(s) box (or anywhere else) to close the list.
Above the Enter Word(s) box is a drop-down list box with three buttons to its left. This works like the memory buttons on a calculator.
New Entry:
AI-C Lookup Program Code
Introduction
The purpose of this section is to explain in detail how the program code works. This should make it easier for others to modify the code or write their own code.
To understand this section requires reading everything up to this section about the structure and nature of the database.
To follow along in the code, bring up the VB6 source code (frm_Lookup.frm) which should be with this file. Ideally, you should load the VB6 Project file AIC_Lookup.vbp into VB6 where you can not only read the code, but run the program and single-step through routines if you wish.
If you do not have VB6, you can read the frm file in any text editor, but then you will need to scroll down quite a ways (over 1300 lines) past where VB6 describes the controls to the line that starts ' Program: AIC_Lookup. Be sure to see the notes below that line.
If you do not have VB6, I recommend going to www.kedit.com and downloading the demo version of their text editor with which you can view frm_Lookup.frm file. I have used Kedit for over 25 years, so obviously, I really like it. One of the nice features of it is that it highlights programming source code files for easier reading.
Complexity of the code
This code has grown in size and complexity over the years and continues to grow. Much of the added complexity is related to functions not everyone will need, so it is not necessary to read and understand every routine or even every part of every routine to make use of the AI-C database. What you need depends on what you want to do with the code. All that most people may need is under Looking up a word, below.
House-keeping code
Here is some house-keeping code used in the program. The items are necessary, but having them tends to obscure the actual working code. If you write your own code, these are steps you should also follow. (This section does not apply to using the program, just to how the code should work.)
- Before adding any kind of entry, see if it already exists. It's pretty easy to add an entry without realizing that you've already added it, then the database gets junked up. Text in any of the tables is NOT case sensitive. If you search for White and get a response that the word is there, it may be white that was found.
Here is what kind of duplication is allowed in the tables:
- In the Cortex table, there should be no duplication of the combination of Entry1, Entry2 and LinkID. Example: the user enters 10021 and 54321 for the Entry1 and Entry2 fields with a LinkID of 29050. Some other entry has the same Entry1 and Entry2 ID#s or has the same numbers reversed into the Entry2 and Entry1 fields, and also has a LinkID of 29050. These are duplicate entries.
Another type of duplication is linking an entry to a word when the same entry has already been linked to a synonym of the word, the superset of the word, an alternative form of the word, etc.
- Words and LinksType tables should have no duplication in any of their fields.
- The Syllables table should have no duplication in the Text field, but the same word in the Words table can have more than one syllabification, meaning there can be duplication in the WordID field.
- The Pronunciation table can have duplication, and often does, because there must be a pronunciation link for each WordID-POS entry in the Cortex, and since the same word can have more than one POS, the same word (but not the same POS) can be in multiple Cortex entries, each requiring the same pronunciation to be entered in the Pronunciation table.
- The Numbers table should have no duplication of the combined contents of Num1, Num2, and Precision fields. Unlike Cortex entries, if the same numbers are interchanged in Num1 and Num2, it is not a duplication, since the numbers in Num1 and Num2 are each converted to text and then concatenated to form a large number.
- Before adding an entry which references another entry, make sure the other entry exists. This includes references to entries in other tables, such as Words, LinkType, Numbers, etc.
- Before adding a new WordID-POS entry, make sure the user has provided the syllabification and pronunciation and that the letters in the syllabification match the letters in the word.
- Before deleting an entry:
- Make sure the entry exists,
- Show it to the user and get his verification,
- If the entry is linked to other Cortex entries, alert the user to change those entries before deleting.
- If the entry is a WordID-POS entry, delete the linked entries in the Pronunciation table.
- If the entry has a LinkID# less than 1000, delete its entry in the Numbers table if that entry is not linked to another Cortex entry..
- If deleting an entry from the Words table, delete its entry in the Syllables table, as well as from the Cortex (its WordID-POS entry) plus any entries linked to the WordID-POS entry.
- If a word is changed in the Words table, change its entry in the Syllables table (and vice-versa), and probably in the Pronunciation table.
- Before saving a changed entry, see if any of the fields which changed were linked to other entries, either in the Cortex or in other tables. If so, take appropriate action as previously described.
- If an entry is added to link a WordID-POS entry to a set, check to see if any other entries are linked to the WordID-POS entry and if so, ask the user if he wants those entries changed to the new set entry (keeping in mind that it is better to link to a set entry than to a WordID-POS entry).
- A new entry to the Words table should NOT have spaces in it (i.e.: single words only) -- normally. Ask the user to verify if he is entering multi-word text.
- Check for circular references in the Cortex. This could be an entry which has its own number in the Entry1 or Entry2 field, or one which references another entry which directly or through other entries, references the original entry.
- Remove leading or trailing blanks from any words entered by the user.
- Before changing anything in the LinksType table, check the software source code to see if the LinkID is hard-coded into the software. Since LinkTypes are meaningless without software to interpret them, there's a good chance that each LinkType is hard-coded in the software either individually or as part of a range of numbers.
- Before changing an entry in the Numbers table, see if other Cortex entries reference the same Numbers entry. If so, show the user the other entries and ask if the Numbers entry should be changed for all of them, or if a new Numbers entry should be added for the current Cortex entry.
VB6 programming quirks
Following are some VB6 programming procedures (or personal quirks) used in the program. Most of these are also documented with comments in the source code.
- Text searches are not case sensitive, so if you look for "White" and get a match, make sure you didn't get "white":
x = "White"
With WordsRS
.Index = "Text"
.Seek "=", x
If .NoMatch = False Then
Do While !Text <> x And LCase$(!Text) = LCase$(x)
.MoveEntry2
If .EOF Then Exit Do
Loop
End With
The underlined code says that if the words don't match case, but match without case, keep looking.
- Converting null and numeric data to strings: If x is a string variable, you may see code such as
x = "" & CortexRS!Entry1.
That is a shortcut for:
If Not IsNull(CortexRS!Entry1) Then
x = Str$(CortexRS!Entry1)
Else
x = ""
End If
If Entry1 is Null and you just say
x = CortexRS!Entry1
you will get a VB6 error message, and if it is not Null, you will get a string starting with a blank before the number. Saying x = "" & CortexRS!Entry1
solves both problems.
- If .EOF Then Exit Do is needed in loops like this:
Do
.MoveEntry2
If .EOF Then Exit Do
Loop While !ID = x
because if .EOF is True, then testing !ID will create a No record error.
- Project-wide variables declared at the start of the code begin with the data type: long_, bln_, etc. Local (subroutine) variables are DIMed as specific data types, but do not include the prefix; e.g.: i, x, cID.
- With... End With is a shorthand option in VB6. Any control or dataset named in the With statement can have its properties or fields names accessed without repeating the control/dataset name. See the block of code just above for an example. Record set features are preceded by a "." while data fields are preceded by a "!", such as !Entry1 instead of CortexRS!Entry1.
With... End With blocks cannot be nested, so you will still see some use of the long form.
- You can leave .Text off a control name when getting its text. Example: if you say x = t_Word where t_Word is a text box, it is the same as saying x = t_Word.Text. Likewise for combo list boxes, etc.
- Long lines can be split onto following lines in VB6 by ending them with an underscore character. I do this so that I don't have to scroll the editor horizontally to read long lines.
- Multiple record sets are used for accessing the Cortex table. Many times when searching the Cortex table, I use .MoveNext to advance to the next record in the search criteria. If I need to branch off to search for something else, I would lose my place in the .MoveNext series, so instead, I open another recordset into the Cortex to do the other search, thus leaving the original recordset undisturbed. Sometimes I even open a third recordset. These are identified as Cortex2RS and Cortex3RS. I'm not the world's leading authority on database programming, so this may not be the technically best way to do this, but it works for me.
- An ampersand (&) is used for concatenating variables, numeric data, and/or string data into a string variable. The plus sign is used only for math.
- I don't always use the multi-line If ... Then, End If structure for short lines such as:
If .NoMatch Then Exit Do
Looking up a word
Overview
When the brain tries to understand text that it reads or hears, it may trace the links of each word through a huge number of connections, back through your entire lifetime of memories. Links which are deemed probably not relevant are suppressed by a chemical reaction. Signals that get through create a big parallel network of information which the brain analyzes to understand what is being said and then to create a response.
Ultimately, I expect AI-C to work the same way, though without the parallel linking for now, unfortunately. Meanwhile, this program not only serves as a way to view, add, and edit entries, but as a framework for developing routines which will allow us to extract all the data we need.
When a word is entered and Look up word is clicked (Sub b_LookItUp_Click):
- The word is looked up in the Words table to get its WordID# (Sub FindWordID)
- The Cortex is searched for the WordID with any POS LinkID# (Sub FindPOS).
- The POS list box shows all the word's POS entries
- Using the first WordID-POS entry number in the POS list box,
the Cortex is searched for entries linking that number as a
type of another entry and those entries are displayed in the
Type Of list box. (Sub lb_POS_DblClick)
- All links to the selected POS entry and type-of/part-of entry, if any, are displayed.
See below for details.
- The syllables, pronunciation, and other boxes at the right side of the window are looked up and displayed.
Selecting POS and part-of/type-of entries
I've tried a number of different methods for displaying links and concluded that the single List box method is the simplest. Following is a brief walk-through of the code. See the comments in the source code for detailed explanations.
Sub lb_TypeOf_DblClick performs these steps:
- Clears the Links list box.
- Gets the ID# of the selected type-of/part-of list entry, if any.
- Adds a heading for it to the Links list.
- Calls the FillLinks sub to look up the links to the selected ID#.
- Gets the ID# of the selected POS entry in the POS list box.
- Adds a heading for it to the Links list.
- Calls GetOtherWordForms to find related POS entries for the selected POS entry.
For example, if "ring - verb" is the word-POS, it will find the other verb forms,
"rang, rung, ringing, rings".
- Calls FillLinks to look up the links to the selected POS.
See the next section for finding and displaying links
The purpose of this section is to explain in detail how the program code works. This should make it easier for others to modify the code or write their own code.
To understand this section requires reading everything up to this section about the structure and nature of the database.
To follow along in the code, bring up the VB6 source code (frm_Lookup.frm) which should be with this file. Ideally, you should load the VB6 Project file AIC_Lookup.vbp into VB6 where you can not only read the code, but run the program and single-step through routines if you wish.
If you do not have VB6, you can read the frm file in any text editor, but then you will need to scroll down quite a ways (over 1300 lines) past where VB6 describes the controls to the line that starts ' Program: AIC_Lookup. Be sure to see the notes below that line.
If you do not have VB6, I recommend going to www.kedit.com and downloading the demo version of their text editor with which you can view frm_Lookup.frm file. I have used Kedit for over 25 years, so obviously, I really like it. One of the nice features of it is that it highlights programming source code files for easier reading.
This code has grown in size and complexity over the years and continues to grow. Much of the added complexity is related to functions not everyone will need, so it is not necessary to read and understand every routine or even every part of every routine to make use of the AI-C database. What you need depends on what you want to do with the code. All that most people may need is under Looking up a word, below.
Here is some house-keeping code used in the program. The items are necessary, but having them tends to obscure the actual working code. If you write your own code, these are steps you should also follow. (This section does not apply to using the program, just to how the code should work.)
- Before adding any kind of entry, see if it already exists. It's pretty easy to add an entry without realizing that you've already added it, then the database gets junked up. Text in any of the tables is NOT case sensitive. If you search for White and get a response that the word is there, it may be white that was found.
Here is what kind of duplication is allowed in the tables:- In the Cortex table, there should be no duplication of the combination of Entry1, Entry2 and LinkID. Example: the user enters 10021 and 54321 for the Entry1 and Entry2 fields with a LinkID of 29050. Some other entry has the same Entry1 and Entry2 ID#s or has the same numbers reversed into the Entry2 and Entry1 fields, and also has a LinkID of 29050. These are duplicate entries.
Another type of duplication is linking an entry to a word when the same entry has already been linked to a synonym of the word, the superset of the word, an alternative form of the word, etc.
- Words and LinksType tables should have no duplication in any of their fields.
- The Syllables table should have no duplication in the Text field, but the same word in the Words table can have more than one syllabification, meaning there can be duplication in the WordID field.
- The Pronunciation table can have duplication, and often does, because there must be a pronunciation link for each WordID-POS entry in the Cortex, and since the same word can have more than one POS, the same word (but not the same POS) can be in multiple Cortex entries, each requiring the same pronunciation to be entered in the Pronunciation table.
- The Numbers table should have no duplication of the combined contents of Num1, Num2, and Precision fields. Unlike Cortex entries, if the same numbers are interchanged in Num1 and Num2, it is not a duplication, since the numbers in Num1 and Num2 are each converted to text and then concatenated to form a large number.
- In the Cortex table, there should be no duplication of the combination of Entry1, Entry2 and LinkID. Example: the user enters 10021 and 54321 for the Entry1 and Entry2 fields with a LinkID of 29050. Some other entry has the same Entry1 and Entry2 ID#s or has the same numbers reversed into the Entry2 and Entry1 fields, and also has a LinkID of 29050. These are duplicate entries.
- Before adding an entry which references another entry, make sure the other entry exists. This includes references to entries in other tables, such as Words, LinkType, Numbers, etc.
- Before adding a new WordID-POS entry, make sure the user has provided the syllabification and pronunciation and that the letters in the syllabification match the letters in the word.
- Before deleting an entry:
- Make sure the entry exists,
- Show it to the user and get his verification,
- If the entry is linked to other Cortex entries, alert the user to change those entries before deleting.
- If the entry is a WordID-POS entry, delete the linked entries in the Pronunciation table.
- If the entry has a LinkID# less than 1000, delete its entry in the Numbers table if that entry is not linked to another Cortex entry..
- If deleting an entry from the Words table, delete its entry in the Syllables table, as well as from the Cortex (its WordID-POS entry) plus any entries linked to the WordID-POS entry.
- If a word is changed in the Words table, change its entry in the Syllables table (and vice-versa), and probably in the Pronunciation table.
- Before saving a changed entry, see if any of the fields which changed were linked to other entries, either in the Cortex or in other tables. If so, take appropriate action as previously described.
- If an entry is added to link a WordID-POS entry to a set, check to see if any other entries are linked to the WordID-POS entry and if so, ask the user if he wants those entries changed to the new set entry (keeping in mind that it is better to link to a set entry than to a WordID-POS entry).
- A new entry to the Words table should NOT have spaces in it (i.e.: single words only) -- normally. Ask the user to verify if he is entering multi-word text.
- Check for circular references in the Cortex. This could be an entry which has its own number in the Entry1 or Entry2 field, or one which references another entry which directly or through other entries, references the original entry.
- Remove leading or trailing blanks from any words entered by the user.
- Before changing anything in the LinksType table, check the software source code to see if the LinkID is hard-coded into the software. Since LinkTypes are meaningless without software to interpret them, there's a good chance that each LinkType is hard-coded in the software either individually or as part of a range of numbers.
- Before changing an entry in the Numbers table, see if other Cortex entries reference the same Numbers entry. If so, show the user the other entries and ask if the Numbers entry should be changed for all of them, or if a new Numbers entry should be added for the current Cortex entry.
Following are some VB6 programming procedures (or personal quirks) used in the program. Most of these are also documented with comments in the source code.
- Text searches are not case sensitive, so if you look for "White" and get a match, make sure you didn't get "white":
x = "White" With WordsRS .Index = "Text" .Seek "=", x If .NoMatch = False Then Do While !Text <> x And LCase$(!Text) = LCase$(x) .MoveEntry2 If .EOF Then Exit Do Loop End With
The underlined code says that if the words don't match case, but match without case, keep looking.
x = "" & CortexRS!Entry1.That is a shortcut for:
If Not IsNull(CortexRS!Entry1) Then
x = Str$(CortexRS!Entry1)
Else
x = ""
End If
If Entry1 is Null and you just say
- x = CortexRS!Entry1
- x = "" & CortexRS!Entry1
Do
.MoveEntry2
If .EOF Then Exit Do
Loop While !ID = x
because if .EOF is True, then testing !ID will create a No record error.
With... End With blocks cannot be nested, so you will still see some use of the long form.
If .NoMatch Then Exit Do
Overview
When the brain tries to understand text that it reads or hears, it may trace the links of each word through a huge number of connections, back through your entire lifetime of memories. Links which are deemed probably not relevant are suppressed by a chemical reaction. Signals that get through create a big parallel network of information which the brain analyzes to understand what is being said and then to create a response.
Ultimately, I expect AI-C to work the same way, though without the parallel linking for now, unfortunately. Meanwhile, this program not only serves as a way to view, add, and edit entries, but as a framework for developing routines which will allow us to extract all the data we need.
When a word is entered and Look up word is clicked (Sub b_LookItUp_Click):
- The word is looked up in the Words table to get its WordID# (Sub FindWordID)
- The Cortex is searched for the WordID with any POS LinkID# (Sub FindPOS).
- The POS list box shows all the word's POS entries
- Using the first WordID-POS entry number in the POS list box,
the Cortex is searched for entries linking that number as a
type of another entry and those entries are displayed in the
Type Of list box. (Sub lb_POS_DblClick) - All links to the selected POS entry and type-of/part-of entry, if any, are displayed.
See below for details. - The syllables, pronunciation, and other boxes at the right side of the window are looked up and displayed.
Selecting POS and part-of/type-of entries
I've tried a number of different methods for displaying links and concluded that the single List box method is the simplest. Following is a brief walk-through of the code. See the comments in the source code for detailed explanations.
Sub lb_TypeOf_DblClick performs these steps:
- Clears the Links list box.
- Gets the ID# of the selected type-of/part-of list entry, if any.
- Adds a heading for it to the Links list.
- Calls the FillLinks sub to look up the links to the selected ID#.
- Gets the ID# of the selected POS entry in the POS list box.
- Adds a heading for it to the Links list.
- Calls GetOtherWordForms to find related POS entries for the selected POS entry.
For example, if "ring - verb" is the word-POS, it will find the other verb forms,
"rang, rung, ringing, rings". - Calls FillLinks to look up the links to the selected POS.
See the next section for finding and displaying links
Sub FillLinks
- Look up and save the links to the target ID# (Level 1 links).
- Get the first/next testEntry from the testEntries() array,
- Look for an entry with (2) as Entry1 or Entry2.
- If a matching entry is found:
-
- Add it to the end of the testEntry array.
- MoveNext for another entry linked to the (2) testEntry.
- Repeat (4) - If a new entry was saved to testEntry, return to (2).
- Move the last entry found to the array displayEntries() and delete it from testEntries().
- Go to (2).
FillLinks is passed a Cortex ID# which is the first target ID#.
The target ID# becomes the first in an array named testEntries.
The following steps are then followed:
Note that it only takes 4 steps for AI-C to find EVERY entry which links directly or indirectly to any other specified entry in the Cortex and that it does so virtually instantaneously.
Sub CvtEntry2Text
This routine takes a Cortex entry passed to it, broken down into fields: ID#, WordID#, Entry1#, LinkID#, Entry2#, and entry date, and looks up each of those numbers to find the text they represent. When the text is acquired, it calls Sub AddTextLine to add the text to the Links list box.
The ID# of the original entry is stored in the variable str_EntryLinksShow and this sub checks that variable to make sure the same entry is not listed more than once.
Here is sample data passed to the Sub and further explanation from the source code:
' Sample data passed to this routine: '
' 125836 is the Cortex ID# (cID) '
' 0 is the WordID# (wID) '
' 44303 is the Entry1# (sID) '
' 29010 is the LinkID# (lID) '
' 99697 is the Entry2# (nID) '
' This routine turns this into a Links entry like:'
' cID sID lID nID '
' 125836: 44303 [L29010] 99697 '
' '
' Entry1 and Entry2 may point to entries which '
' point to other entries which, in turn, will '
' either be WordID-POS entries or which, again, '
' point to WordID-POS entries or other entries, '
' and so on, but eventually, every entry must '
' track back to WordID-POS entries and give us '
' text to substitute for the ID#s. '
' '
' The purpose of this routine is to convert the '
' submitted entry into text by tracking back the '
' entry numbers to Word entries via LookUpLinks. '
' '
' When an entry links to another entry which is '
' NOT a WordID-POS entry, that entry is plugged '
' into the original entry where that ID# was. '
' For examples, look up "aardvark" in AI-C Lookup '
' check Show detail, and study the longer entries.'
Treatment of several different LinkTypes are hard-coded into this routine, so if any changes are made to the LinkTypes table, this routine should be checked to see if it is affected. In some sections of this sub, calls are made to the sub LookUpLinks in which a Cortex ID# is passed and the text for it is returned. In many cases, the entry represented by the ID# is a nested entry, in which case the text returned will be for the complete set of nested entries.
Some sections of this sub result in a finished entry, ready to display, in which case the entry text is passed to the sub AddTextLine to be added to the Links list.
Some sections call the sub ChangeLink2Text which replaces an ID# in the entry with the ID#'s text. See that sub to understand why a simple text replacement will not work.
Sub LookUpLinks
A Cortex ID# and a text string with that number in it is passed to this routine. The ID# is looked up. If the entry has a WordID#, the text for the WordID is looked up in the Words table. Sub ChangeLink2Text is called to substitute the ID# in the string with the text.
If the entry is not a WordID-POS entry and if Entry2 is not Null, then it is a nested entry. The global variable int_Nested is incremented and Sub CvtEntry2Text is called, passing this entry to it. This is a recursive call since that Sub called this one, and it may call this sub again to find text which will be plugged into the original string and returned to CvtEntry2Text.
If Entry2 is Null and WordID is Null, then the entry is (may be?) a phrase. Call Sub GetPhrase to get the text of the phrase.
Find cID
Under New Entry, you can enter the Cortex ID# (cID) of an entry and press Enter or click Find cID#. This displays a single entry plus syllables and pronunciation if the entry has a WordID. The code for the button is in Sub b_FindCID_Click
The Find cID button and box (just below the Enter word(s) box) can be used to look up the text of an entry and a list of all entries linked to that ID#. The code is in Sub b_FindEntryID_Click.
Both of these routines are simple and straightforward.
Controls for the Links display
The Links display is a standard list box. On the surface, it would seem like a Treeview list box would be easier than the code in the AddTextLine subroutine, but Treeview has complications of its own.
If the use of any of the following controls is not clear, just try displaying an entry and checking and unchecking box(es).
Show dates: Shows the dates entries were made.
Metric system: When an entry is shown which has a link to the Numbers table or numeric data stored in the Entry2 field, the Metric system check box appears. Numeric data is stored as metric, but if the box is unchecked, it is converted to U.S. units of measure.
Link levels::
Say that you look up the word apple and in the Category box it shows entry #1001 type of fruit. When you double-click on fruit, the program direct looks for entries with #1001 as either the Entry1 or Entry2 ID#, such as if entry #2001 links 1001 apple [type of fruit] to char. of some pies. Such entries are level 1 link entries.
If entry 3001 links 2001: apple - char. of some pies to type of dessert then this is a level 2 link to 1001.
Entering a new phrase
- Look up the word in the Words table to get its WordID#.
- Find the WordID-POS entry for the word in the Cortex.
- If no entry is found for either of these first two steps, ask about creating one.
- If more than one WordID-POS entry for the word is found, display them and ask which to use.
- Find all entries linking the WordID-POS entry as a part of or type of something.
- If no part-of (LinkID# 29010) or type-of (#29110) entry is found, use the WordID-POS entry.
- If more than one part/type-of entry is found, display them and ask which to use.
- Save the cID# to be used for each word of the phrase in an array.
- Create a placeholder entry for the phrase.
- Enter the number of words in the Entry1 field.
- Enter a LinkID# of 30910.
- Leave the other fields blank.
- Go through the array and create an entry for each word's entry in the array:
- Put the word's WordID in the WordID field.
- Put the entry ID# for the word's part/type-of entry in the Entry1 field.
- Put the placeholder entry's ID# in the Entry2
- Enter a LinkID of 30911.
Ordinary sentences are normally not stored in the Cortex. Idiomatic phrases (those whose meaning cannot be derived from the individual words in the phrase) and phrases very frequently used are the main candidates for saving in the Cortex.
Enter the text of a phrase, such as "birds of a feather". Do not capitalize the first letter unless it is a word which is normally capitalized within a sentence. When you click Save, the program will perform the following steps for each word in the phrase:
The steps above link each word in a phrase to the phrase placeholder entry. This means that the words are linked in parallel. If each word in a phrase were linked to the next word in the phrase, they would be linked in series. The significance of this comes when looking up a phrase. If you enter a phrase such as no use crying over spilled milk and the Cortex has no sense crying over spilt milk, you would not be able to find the phrase if the words were linked in series because you would not find a link of no and use nor of over and spilled.
But when the words are linked in parallel, you just have to look for a phrase which has the most words linked to the same phrase. In this example, no, crying, over and milk would be linked to the same phrase placeholder. A program could either display this message to the user and ask if it's correct, or it could look up each of the non-matching words in the phrase to see if they are synonymous or alternatives of the words entered.
Searching for a phrase
- Divide the phrase entered into an array of words and look up their WordIDs and POS's.
- Get all phrases linked to the first word in the array which is not a secondary word.
(A secondary word is an interjection, preposition, conjunction, etc.
A primary word is a noun, verb, adjective, or adverb.) - Find one of these phrases to which all the words in the array are linked.
- If a 100% match is found, exit; otherwise:
- For any entries with only 1-2 non-matches, check the word in the found phrase versus
the user-entered words to see if they are synonyms, alternatives, or similar words.
If they are, exit; otherwise, tell the user that a match was not found. - If the closest match has more than 2 non-matches, then repeat steps 2-5 using the
second primary word since the first word could be the one non-matching word.
If the second primary word doesn't generate matching phrases, then there is no point in
checking the other words because we already have the limit of two non-matching words.
The idea of allowing only 2 non-matching words is arbitrary, but seems reasonable.
As usual, you can change it to any number you wish.
Looking up linked entries
When it comes time to parse sentences, it will be necessary to find all entries in which words in the sentence are linked to each other, either directly (in the same Cortex entry) or indirectly (in different entries in a series of linked Cortex entries).
At this time, up to 10 words, separated by commas, can be entered in the Enter word(s) input box and clicking the Look it up button.
The program searches all standard linking entries for the first word, then searches those entries for the other words specified. Linked entries with all the specified words in them are displayed in the Links list box. An option could be added to show entries with a specified number of matching words short of requiring all words to match.
ran, across
The only POS for "ran" is past tense and it has a root of "run".
So look up links for "run" and each word for which it is the root
and for each Type-of/Part-of for each word.
Look at each link set for the word "across" and if found, list it.
"across" can be preposition, adjective, or adverb, but it does not
have a root for any of these nor is it the root for other words.
So we do not have to look for other forms of "across" in the links.
run, across
"run" can be noun or verb, so look up links for "run - noun" and
"run - verb" and for each word for which either is the root and
for each Type-of/Part-of for each word/POS.
cut, operating
Do "cut" as above, but in addition to looking for "operating" in the
links, also look for its root ("operate") and all words for which
that word is the root (operated, operates).
An option could be to show links to synonyms of these words, though that really stretches things out. I think that for parsing, that is definitely something which should be done.
Adding a new word/linking entry
The New Entry section is somewhat complex because associated with it are so many features designed to help automate many of the steps for adding/changing entries.
The Save New Entry button changes to Save Changes when a cID# has been entered and the Find cID# button has been clicked and an entry displayed. Save Changes is also set to being the Default button so that if Enter is pressed while in any input box, the Save Changes click event will be executed.
In the GotFocus event of text boxes, you will see .SelEntry1=0 and .SelLength=32768. This causes any text in the box to be selected so that when the user starts typing, it replaces the old text.
The LostFocus event of the t_NewWord text box looks up the word entered, if any, and if it is in the Words table, it adds the ID# to the box. If the Entry1 box is blank, the default lb_POS cID# is entered in the Entry1 box as the root of the new word.
Changing an entry
Under New Entry, enter the cID# of the Cortex entry to change, then press Enter or click on Find cID#. Make the changes and save.
Look-up buttons
This is pretty simple and self-explanatory in the code.
- Convert non-English characters to English, such as any of ������ to A.
- Convert non-phonetic leading letters to the letter they sound like, such as PS to S, PN to N, PH to F, etc.
- Convert non-phonetic non-leading letters, such as STLE or SCLE to SEL (as in whistle and muscle).
- The Metaphone algorithm converts letters to their sound-alikes. Some of these conversions are used here, though not all of them apply.
- Convert doubled codes to non-doubled: S17735 to S1735. This not only gets rid of the second T/3 in RATTY (R330), but also the second and third T in RATATAT (R333), both of which end up R300.
- Soundex converts each of CGJKQSXZ to the digit 2, but that seems wrong to me if the intent is to group letters which sound alike. GJKQ are all hard-sounding letters while CSXZ are sibilants, so I have changed CSXZ to the digit 7. (C usually has a hard sound when it is the first letter, but we are dealing here with letters after the first letter, such as dice. Exceptions, such as in SC, CT and SK are manually changed.)
- Add words with a code where the 1st and 2nd digits are reversed, such as S415 versus S145. Likewise for the 2nd and 3rd digits, such as S415 and S451. If the input has consonants swapped, the Soundex codes will not match, so the correct alternative will not be added to the list of possible alternatives.
- Split up the submitted word to look for run-on words, such as greatforehand instead of great forehand. See comments in the source code for more detail and examples.
- Test each letter in the submitted word to see if swapping the letter for each of the keys around the letter on a QWERTY keyboard will result in a good word. Example: OHNE - swap I,K,L,P for O and when you get to P, you'll find a match: PHONE. The assumption is that if the person typing the word hit a wrong letter by mistake, it is far most likely to be one around the intended letter.
- Test each letter in the submitted word to see if dropping the next letter will result in a good word. Example: PHJONE. When you get to the J, dropping it results in a good word, PHONE. Again, the assumption is that if you hit an extra key while reaching for the intended key, the wrong key will be adjacent to the intended key. This test applies to the letter itself, since it is easy to double-hit a key by mistake (e.g.: PHOONE).
- After each letter, try adding each letter from a to z and check for a good word. This is the only sure way to get a dropped letter, such as "write" for "wite". Even with this, which is a lot of crunching (26 tests for every letter in the word), if there are any of the other errors mentioned here, including a second dropped letter, the correct word will probably not be found. The only way to improve the odds from here is to run the entire GetSuggestions routine for each letter. That would REALLY be a lot of crunching.
When a word is not found in the Words table, it may be a misspelling. The spelling corrector routines find good words most closely matching the misspelled word. There are two steps for getting suggestions. The first is to compile a list of words roughly matching the word entered. The second is to evaluate those words to find the closest match(es).
Compiling words for suggestions::
Soundex: When a word is added to the Words table, the Soundex routine is called to compute its Soundex code to save with the word. When a word is not found in the Words table, we compute its Soundex code and look up all entries in the Words table with the same Soundex code.
Soundex is normally the first letter of the word followed by 3 digits representing the consonants following the first letter. Vowels after the first letter are ignored. Similar sounding consonants, such as d, t, and p, are assigned to the same numeric digit. Consonants after the first three are ignored (with some exceptions).
Here are changes made to Soundex in AI-C:
After getting the words with Soundex codes which match the code of the submitted word, we add more words based on these tests:
Evaluating possible alternatives:
GetSuggestions presents the user with a list of likely alternatives. The suggestions are displayed in a list box with the closest matches at the top. The number shown by each suggestion is the Damerau-Levenshtein Distance. This is the number of changes to the submitted word to make it match a possible alternative.
For example: wite has a D-LD of 1 compared to white because it takes 1 edit (adding an "h") to make them match. It has a D-LD of 2 compared to wait: 1 to add the "a" plus 1 to drop the "e".
Evaluation tests include qGram, nGram, and Damerau-Levenshtein Distance. Google for more information about each of these.
Words with the smallest Damerau-Levenshtein Distance are moved to the top of the list with the D-LD number at the start of each line.
The number in parentheses is the ranking of the Frequencyfrequency of usage of the word in everyday text/speech.
If a misspelled word has been specifically added to the Cortex with a link to the correct spelling, it is shown at the top of the list.
Use of these routines in AI-C:
These routines are primarily intended for use when parsing input text which may have words not in the dictionary due to typos. When actually used in parsing, these routines will be greatly helped by knowing the parts of speech and words to which the selected word is linked.
Here is a sentence which shows what to expect as input from places on the Internet where anyone can post comments.
-
ITs dumb becaise Alpert was the most knowledgeable, adn he jkust ignored smokey.
Changing the algorithms:
The suggestions routines have been doing a good job of finding the intended words for misspellings, but improvements are always possible.
When changes are made to the Soundex calculation routines, the Words table must be updated for the changed codes for each word. This can be done by running the ChangeSoundex subroutine.
Rhymes
Rhymes are probably not a significant feature of an NLP program, but since AI-C has the pronunciations table, it is easy enough to check it for rhymes.
Searching for rhymes at the end of words requires a brute-force approach of simply going through the whole pronunciation table an entry at a time. If rhymes were a significant feature, it would probably be worth creating a rhyming table of word endings.
It might also be worth adding near-rhymes, such as words with similar sounding vowels and consonants (nob, nod, not, naught, etc.).
Miscellaneous Information
- A person's cousin is the child of the person's aunt/uncle.
- A person's aunt is the sister of a person's parent.
- An aunt's child is a person's cousin.
- Joe's father, Bob, has a sister, Mary, who has a son named Sam.
- What is Sam's relationship to Joe?
- Joe is a person [125766: =person=]
- #125772: Bob is Joe's father [125750: parent]
- #125784: Mary is the [parent's] sister [125792: sibling]
- #125785: Sam is a son, which is a male child.
- #125786:
- #125785: The [child: Sam] of a [sibling: Mary] of a [parent: Bob] of a [person: Joe] is
- #125775: The [cousin] of the [person: Joe].
- Search the Words table for the word and get it's ID, which will be the WordID in the Cortex table.
- Search the Cortex table for the WordID and the Part Of Speech (POS). Example: child - noun.
All other searches from here down will be in the Cortex table. - Search for the entry linking the WordID-POS's Cortex ID# to a Link Type of element of.
If no entry is found, use the WordID-POS's entry ID#.
If there is more than one element-of entry for the Word-POS ID#, do the following for each one: - Search for entries with a cID# which match the Entry2# ("nID") of the entry above to track down its meaning.
- For each entry found, search for its ID# as the Entry2 of another entry.
- The word child has a WordID# of 15131.
- #21864 has WordID# 15131, child, and a POS link type of noun.
- #125783 links #21864 (child-noun) as an Element Of relatives.
- #125785 links #125783 (child-noun:{relatives}) of (belonging to) #125784.
We now have child of #125784, so we look for cID# 125784 to get its meaning. - #125784 links #125752 as being of (belonging to) #125772, so look those up:
- #125752 links #101182 as being an Element Of #125773 (relatives).
- #101182 is a Word-POS entry for sibling - noun, which ends the branch for #125784.
- Now that we have sibling, we go back to #125784 and get its Entry2 (125772):
- #125772 links #125745 as being of #125766, so look those up:
- #125745 tracks back to parent and #125766, to person,
So now we look for an entry with #125785 (the ID# from #4, above) as the Entry2: - #125786 says #125775 is #125785
- #125775 links #125774 as being of #125766
- #125774 links to #27857, which is the WordID-POS entry for cousin.
- #125766 is the WordID-POS entry for person We now have: cousin of person is + child of sibling of parent of person for a complete definition.
- Let's go to play golf.
- She left to go to look for her keys.
- He went to go to greet his friend.
- Of course. (The answer is obvious.)
- Certainly. (A more formal tone than of course.)
- Is the Pope catholic? (So obvious that the question is not taken seriously.)
- Okay. (Often less in agreement than a simple yes, such as in response to a question like Do you want to go shopping for dresses with me?, where a husband might say okay, which is actually not an appropriate answer to Do you want to... and means Not really, but I will. while a female friend might say Yes, meaning I would love to go.)
- Okay by me. (An even less formal tone than okay, often meaning that it doesn't really matter.)
- If that's what you really want. (An even stronger implication of Not really, but I will.)
- Time moves quickly, just like an arrow does;
- You should measure the speed of flies like you would measure that of an arrow
('time' being an imperative verb and 'flies' being the insects) - You should measure the speed of flies the way an arrow would measure the speed of flies.
- Time only the flies which are like an arrow.
- The magazine, Time, travels through the air in an arrow-like manner. English is particularly challenging in this regard because it has little inflectional morphology
- the generation of questions or comments regarding an existing aspect of a conversation subject ("deepening"),
- the generation of questions or comments regarding new subjects or new aspects of the current subject ("broadening"), and
- the ability to abandon a certain subject matter in favor of another subject matter currently under discussion ("narrowing") or
- new subject matter or aspects thereof ("shifting").
- go to sleep = sleep (but see Filler Words, above)
- Search for repulsed and it takes you to the entry for repulse
- The definition of repulse is to cause feelings of repulsion in with a hyperlink to repulsion.
- repulsion's definition: the act of repulsing or the state of being repulsed.
- Both of those hyperlinks taking you back to repulse.
- atonality: an atonal principle
- atonal: marked by atonality
- the ability to contain: This hotel has a large capacity.
- the maximum number that can be contained: The inn is filled to capacity.
- the power of receiving knowledge; mental ability: The capacity to learn calculus.
- ability to perform: He has a capacity for hard work.
- indicates deprivation - robbed of one's money
- indicates source - a piece of cake
- indicates cause, reason - to die of hunger
- indicates item(s) within a category - thoughts of love
- indicates inclusion in a group - one of us
- robbed of what? -- one's money
- a piece of what? -- cake
- die of what? -- hunger
- thoughts of what? -- love
- one of what? -- us
- one, a, an, or some; one or more without specification or identification: If you have any witnesses, produce them. Pick out any six you like.
- whatever or whichever it may be: cheap at any price.
- in whatever quantity or number, great or small; some: Do you have any butter?
- every; all: Any schoolboy would know that.
- The ball doesn't have to come directly downward. It may come at a bit of an angle.
- The hoop and the rim are the same thing. Using different names can be confusing to some.
- ...grabbing onto the rim with power A dunk does not require a player to grab the rim, and what does grabbing it "with power" even mean? They probably meant to refer to the shot as being made with power, but that's not how it came out.
- I think that saying to attempt to... is wrong. It's not a "dunk shot" unless you make it. But this is a minor point.
- Why is "a ball" in parentheses? It is not parenthetical to the definition, it is a key element.
- ...jumps with the ball..." - Not if it's a dunk of an alley oop pass.
- ...hands held above the rim. - What does "held" denote? The shot is made from above the rim in a continuous, forceful motion. Saying that the hands are "held" anywere indicates that they are motionless in a particular location. Example: If hands are "held above a table", they are not slamming down onto the table.
- acause -- A search is done in parallel for the letters a-c-a-u-s-e being linked together in that order. A match is not found, so alternatives are explored. A match is found for c-a-u-s-e and those letters are often used in speech, and even in writing, for because. The phrase That's because followed by a noun and verb is commonly seen, so because is assumed to be the intended word.
- chimbley -- A parallel search for letters returns c-h-i-m-*-*-e-y. A further mental search turns up the word chimney. The further discussion of smoke and blaze makes chimney the most likely intended word. You might think that this could be a difficult one for the computer, but if chimbley is entered in the AI-C Lookup program, chimney is the only suggested correction returned, so this is an easy one, even without the smoke and fire associations.
- vereas is a real toughie. A human would likely only get this in context. The ending sounds er-az come after a semicolon followed by a concept contrasting to the text before the semicolon. A word with the same number of syllables and also ending with a pronunciation of er-az is whereas. In addition, most people are aware that a dialect with German influence often substitutes v for w, further reinforcing the choice of whereas. Analysis is similar for later uses of wery and vith.
- sinds is easy. Even AI-C returns sends as its top choice because of the e for i substitution plus the matching consonants. Likewise, obstinit is a rhyming eye dialect and easy to figure.
- wot rhymes with what and its syntax in the text suggests that what is correct. AI-C suggests what, but because it takes two edits to go from wot to what, it comes after a number of suggestions with only 1 edit.
- hextricate is a rhyming eye dialect. Since h is often silent, leaving off the h actually results in the correct word. AI-C makes extricate its only suggestion.
- gen'l'men -- The brain's parallel search of g-e-n-*-l-*-m-e-n should return only gentlemen, which is reinforced by the context in which it is used. AI-C offers gentlemen as the only word matching the wild cards.
- theirselves is a nonstandard form of themselves and is in AI-C as such, and as it probably is in the brain. Likewise, 'em is such a common contraction of them that it isn't a problem.
- using equipment to detect movement in speech-related muscles during quiet reading,
- involving the speech tract in some other activity while reading,
- determining if sound properties of text affect reading.
- Posted by Dawn Goldberg
- Posted by Mandy
- http://ask.metafilter.com/27778/How-do-people-with-littleno-language-skills-process-informationthink I seldom think in words. I seem to think in a kind of symbolic shorthand that sometimes, but not always, approximates words and sentences. I often find it hard to translate my thoughts into writing. posted by martinrebas
- Posted by Mandy
- Name a fruit beginning with the letter p.
- Name an animal beginning with the letter l.
- Name a fruit ending with the letter b.
- Name an animal ending with the letter w.
- i before e (or vice-versa)
- silent letters: acknowleged for acknowledged, aquire for acquire, adolecent for adolescent
- adding "d": adcquire, alledge for allege
- mixing up ice and ise, such as advise for advice.
- e for y in androgenous for androgynous
- double letters, such as brocoli versus brocolli
- mixed up vowels: abundunt vs abundent vs abundant
- Language modeling.
- Hidden Markov models, and tagging problems.
- Probabilistic context-free grammars, and the parsing problem.
- Statistical approaches to machine translation.
- Log-linear models, and their application to NLP problems.
- Unsupervised and semi-supervised learning in NLP.
Most of the problems addressed in the course go away, or at the very least are greatly modified, with access to a robust knowledge base.
- Search, Indexing and Memory
- Streams, Information and Language, Analyzing Sentiment and Intent
- Databases and their Evolution, Big data Technology and Trends
- Programming: Map-Reduce
- Classification, Clustering, and Mining, Information Extraction
- Reasoning: Logic and its Limits, Dealing with Uncertainty
- Bayesian Inference for Medical Diagnostics
- Forecasting, Neural Models, Deep Learning, and Research Topics
- Data Analysis: Regression and Feature Selection
- Basic Text Processing
- Edit Distance
- Language Modeling
- Spelling Correction
- Text Classification
- Sentiment Analysis
- Discriminative Classifiers: Maximum Entropy Classifiers
- Named Entity Recognition and Maximum Entropy Sequence Models
- Relation Extraction
- Advanced Maximum Entropy Models
- POS Tagging
- Parsing Introduction
- Probabilistic Parsing
- Lexicalized Parsing
- Dependency Parsing
- Information Retrieval
- Ranked Information Retrieval
- Semantics
- Question Answering
The textbook on which the course above is based is considered a standard. Like the book, this course has a heavy emphasis on math where my experience has indicated it's not needed. For example, the class on Spelling Correction uses word frequency data which I have found to be very unreliable. As explained elsewhere, I have given a simple frequency ranking to words and the AI-C spelling routines have proven to be very reliable without any need for esoteric mathematical computations. Other areas which also rely heavily on math are not needed when a properly designed knowledge base is available.
- brunch = breakfast) + lunch
- Spanglish = Spanish + English
- urinalysis = urine + analysis
The rest of this is info I've thought of or come across which is relevant to NLP but which I haven't integrated yet into AI-C.
Linking Words To Get Facts
Some, if not most, AI language processing projects seem to emphasize feeding a lot of "facts" into their system in the form of sentences from which their AI can make deductions. One that I was reading about not too long ago gave this as an example:
- Facts:
From these facts, the AI program can deduce that Sam and Joe are cousins.
AI-C's approach is to start by linking dictionary definitions in the Cortex. An example follows. Numbers shown in square brackets link to another entry's ID, where the words from that entry would be plugged into the current entry. Numbers not shown in square brackets refer to an entry where the Word-POS entry for the word shown is linked as an element of the set {relatives}.
| ID# | Entry1 | Link | Entry2 |
| 125775 | 125774 (cousin) | of | 125766 (=person=) |
| 125786 | [125775] | is | [125785] |
| 125785 | 125783 (child) | of | [125784] |
| 125784 | 125752 (sibling) | of | [125772] |
| 125772 | 125745 (parent) | of | 125766 (=person=) |
| 125750 | 34462 (father) | is | parent [125772] |
| 125792 | 125748 (sister) | is | sibling [125784] |
| 125764 | 125753 (aunt) | is | [125792] of [125750] |
The text =person= is a way I am presently showing a specific person rather than just using the general word person. I may change this after seeing how necessary it is or isn't.
Going back to the statement to be analyzed:
-
Joe's father, Bob, has a sister, Mary, who has a son named Sam.
Let's say you are analyzing written text to determine its meaning, and that you have already parsed the current sentence. To display all data linked to a word:
Example (matching the numbered list above):
Filler/Pause Words
Rarely is there a sentence spoken or written in conversation which does not have words in it which are not necessary for the understanding of the sentence. Example: Why, I'm sure I don't know. in response to a question instead of a simple I don't know.
I used to call words like this filler words because on the surface, they appear unnecessary. One of the most frequently used filler phrases is: go ahead and.... If you listen to unscripted instructional TV shows or videos, you will surely hear this phrase, sometimes at the start of almost every sentence: Go ahead and measure. Then go ahead and mark the measurement on the board. Now go ahead and cut it. Now go ahead and nail it to the other boards... instead of just Measure it. Mark the measurement... Cut it. Nail it...".
However, I've recently started speculating that these might more accurately be called clue filler words because they give your brain clues about the subject matter or the tone of what is being said, making it easier for the Cortex to predict what is coming next or to analyze what is actually meant.
As previously discussed, the brain is an analysis and prediction machine. When you say a word, it starts trying to predict what you are going to say and what other words may be coming. It also must predict whether your words are meant to be taken literally or as a joke or sarcasm, etc. So when you start a sentence with Go ahead and..., you are giving the listener's brain a clue as to what is coming next.
A similar filler is the use of go to between two verb phrases where leaving it out would not change the meaning of the sentence:
However, leaving out go to can change the specific meaning of some sentences, such as I want to go to eat (not at the current location) versus I want to eat (here or elsewhere).
Another type of filler words are the pause for thought fillers. Often, the pause filler is not a word, but just a sound like uh which is normally uttered unconsciously. Pause fillers can morph into nervous tics rather than true pauses, such as Because, uh, when I, uh, eat peanuts, uh, I have an, uh, allergic reaction. The go ahead and... phrase might also be a pause filler at times.
Unlike clue fillers, which can be seen in print as well as in speech, pause fillers are not seen in printed conversation unless the person using them puts them in for effect.
Choosing Responses
A computer is normally programmed to be efficient, but in AI, the most concise and precise response is not always the most efficient in terms of relaying information. Here are different ways to respond in the affirmative to a question where a simple "yes" would seem to be the most concise answer, but each of these responses carries different ancillary information with it (shown in parentheses):
Size Matters: Brain vs Computer
The human cortex is estimated to have about 30 billion neurons with a total of about 300 trillion synapses. (Source: Computational Neuroscience course, University of Washington [online], instructor: Rajesh P.N. Rao.
The cat's brain simulator on IBM's Dawn Blue Gene/P supercomputer simulates the activity of 1.617 billion neurons connected in a network of 8.87 trillion synapses. It requires over 147 thousand CPUs and 144 TB of main memory, just to achieve this, according to an IBM press release.
The human Cortex has 18.6x as many neurons and 33.8x as many synapses, so roughly speaking, it may take 20x as much computing power and memory to simulate the human Cortex. That is about 3 million CPUs and 3000 TB of main memory.
Natural Language Processing Problems
The following is from Wikipedia: Some examples of the problems faced by natural-language-understanding systems:
(October 2010 update: In the Wikipedia discussion page, I objected to the following examples as being non-issues with regard to NLP for the reasons given below. The examples were removed from the main article.)
1. The sentences "We gave the monkeys the bananas because they were hungry" and "We gave the monkeys the bananas because they were over-ripe" have the same surface grammatical structure. However, the pronoun "they" refers to monkeys in one sentence and bananas in the other, and it is impossible to tell which without a knowledge of the properties of monkeys and bananas.
The purpose of AI-C is to provide such knowledge of the properties of entities. AI-C would link the capability of feeling hunger to monkeys and not to bananas, and would link the conditions of being unripe, ripe and over-ripe as conditions of bananas. With this knowledge, AI-C could easily understand that in the first sentence, it is the monkeys which are hungry and in the second sentence, that the bananas were over-ripe.
2. Susumu Kuno of Harvard asked his computerized parser what the sentence "Time flies like an arrow" means. In what has become a famous response, the computer replied that it was not quite sure. It might mean:
Two other examples treat "Time flies" as a type of insect, just as a "Fruit fly" is, but that seems pretty weak.
This example should not give AI-C any trouble because it starts with an expression which is so widely used and known that it dates back to a Latin version, tempus fugit, a form of which was used by the Roman poet Virgil.
3. English and several other languages don't specify which word an adjective applies to.
For example, in the string "pretty little girls' school".
Does the school look little?
Do the girls look little?
Do the girls look pretty?
Does the school look pretty?
Does the school look pretty little?
("pretty" here meaning "quite" as in the phrase "pretty ugly")
Do the girls look pretty little? (same comparison applies)
The letter "A" can have many different meanings: the first letter of the English alphabet, a musical note, a grade, etc., just as the phrase "pretty little girls' school" can have any of the meanings shown above. In either case, the meaning is determined by the surrounding context and it is ridiculous to say that understanding the phrase is a problem any more than understanding which meaning of "A" is intended when no context is given for either.
4. We will often imply additional information in spoken language by the way we place emphasis on words.
The sentence "I never said she stole my money" demonstrates the importance emphasis can play in a sentence,
and thus the inherent difficulty a natural language processor can have in parsing it.
Depending on which word the speaker places the stress, this sentence could have several distinct meanings:
"I never said she stole my money" - Someone else said it, but I didn't.
"I never said she stole my money" - I simply didn't ever say it.
"I never said she stole my money" - I might have implied it, but never explicitly said it.
"I never said she stole my money" - I said someone took it; I didn't say it was she.
"I never said she stole my money" - I just said she probably borrowed it.
"I never said she stole my money" - I said she stole someone else's money.
"I never said she stole my money" - I said she stole something of mine, but not my money.
With audio input, the NLP software would need to be able to detect and make note of such variations in emphasis. With written input, it is the responsibility of the writer to indicate the intended meaning either through context or by using italics, underlining, bold text, etc.
5.Computer's side of a conversation requires:
6. Real world "grammar":
I still have not figured out why so much time and effort is put into the theory of grammar when people write/talk like this:
- Resistive screens are bad. Very bad. I�m serious about this. I don�t care how cheap they are � you should avoid them at all costs. Do. Not. Buy. ... Android phones were single-touch. Point, tap, drag, and that was about it.
Very bad is not a sentence, but at least it ties to the previous word. I wonder how a parser/tagger handles Do. Not. Buy. The last "sentence" is similar to the very bad "sentence".
The Most Frequently Misspelled Simple Word?
Perhaps the most common misspelled word in printed text conversations (which means mostly on the Internet) is using loose (an adjective meaning not secured) in place of lose (a verb meaning to no longer have possession of). Here is an example taken from a posting on the Internet:
If a month later I decide to buy a Nook or Sony Reader and sell the Kindle, then I will loose all the books I spent a lot of money on. What would happen if people had to loose their entire DVD collection every time they switched DVD player brands?
A problem with this misspelling is that loose is a legitimate word. It is only a misspelling insofar as the intended word is lose, so for a spelling checker to catch this, it would have to be able to parse and understand the meaning of the sentence it is in.
The Use of a Versus an
-
In speech and writing, a is used before a consonant sound: *a door*, *a human*.
an is used before a vowel sound: *an icicle* *an honor*.
Mainly in speech, a is used before a vowel, occasionally, and more often in some dialects than in others: *a apple*, *a hour*, *a obligation*.
Before a consonant sound represented by a vowel letter, a is usual: *a one* ["wun"], *a union* ["YEWn'yUHn"], but an also occurs, though less frequently now than formerly: *an unique*, *such an one*.
Before unstressed or weakly stressed syllables which start with h, both a and an are used in writing: *a historic*, *an historic*.
Shades of Meaning of go to:
travel to a particular location. E.g.: Did you go to the store?
travel to and stay a while. E.g.: Did you go to Paris?
attend. E.g.: Did you go to college?
idioms:
"The Curse of Dimensionality"
While a large amount of information makes it easy to study everything, it also makes it easy to find meaningless patterns. That's where the random-matrix approach comes in, to separate what is meaningful from what is nonsense.
In the late 1960s, Ukrainian mathematicians Vladimir Marcenko and Leonid Pastur derived a fundamental mathematical result describing the key properties of very large, random matrices. Their result allows you to calculate how much correlation between data sets you should expect to find simply by chance. This makes it possible to distinguish truly special cases from chance accidents. The strengths of these correlations are the equivalent of the nuclear energy levels in Wigner's original work.
What is of interest in this article is the idea that with a massive amount of data to analyze for patterns, which is the goal for AI-C, patterns found may be meaningless. This idea will need to be addressed at some point.
Computer consciousness
None of these approaches solve what many consider to be the "hard problem" of consciousness: subjective awareness. No one yet knows how to design the software for that. But as machines grow in sophistication, the hard problem may simply evaporate - either because awareness emerges spontaneously or because we will simply assume it has emerged without knowing for sure. After all, when it comes to other humans, we can only assume they have subjective awareness too. We have no way of proving we are not the only self-aware individual in a world of unaware "zombies".
Disclaimer
Before I start pointing out errors in dictionaries, let me repeat my earlier disclaimer that anything done by man is going to have errors. Undoubtedly there are errors in this document and in AI/C and the LookUp program. Pointing out these errors is meant to be constructive - a guide to things to watch out for and to avoid in our own work.
Ambiguities
Here is Random House's definition of abacus (as seen on Dictionary.com):
- a device for making arithmetic calculations, consisting of a frame set with rods on which balls or beads are moved.
Is it a frame set [pause] with rods? - OR -
Is it a frame [pause] set with rods?
In addition, a frame can be almost any shape, such as a hexagon or even a completely irregular shape, so a more precise definition would refer to a rectangular frame. Also, it would have been easy to indicate the size of an abacus by saying that it is a handheld device, but they left that significant word out while putting in the following redundancy:
The phrase ...rods on which balls or beads are moved is problematic as well. The same dictionary defines bead as a small, usually round object... with a hole through it. For modern (the last couple of thousand years or so) abacuses, on which balls are moved on rods, bead is a sufficient description while ball is redundant and less precise.
The phrase ...rods on which balls or beads are moved is imprecise. It could be interpreted as moving balls which are sitting on rods rather than being strung onto the rods. Finally, saying beads are moved is considered poor/weak grammar; better form is [subject] moves the beads.
A better definition would be: a handheld device on which the user performs arithmetic calculations by moving beads which are strung onto straight rods which are set into the opposite, longer sides of a rectangular frame.
I do not claim to always be that precise in my own writing; I'm just pointing out the very typical weaknesses in dictionaries which, after all, are offered up as being reference sources of correct spelling, grammar, etc.
Here is a simpler example: the idiom arm in arm has a Dictionary.com entry of "arms linked together or intertwined".
Ambiguities: Does arms refer to the arms of a chair or of a person? Does it mean the arms of one person, two people, or more?
The entry in AI-C is: "arm [element of superficial human anatomy] intertwined with arm of different person". This resolves both of the ambiguities present in the dictionary definition.
Vagueness
www.TheAnimalFiles.com says this in their description of aardvarks:
- They will change the layout of their main burrow regularly and every so often they will dig a new one.
How often are regularly and every so often? Once a week, a month? Several times a month? Probably one of those, but the terms are so vague as to be almost useless.
Another example is a dictionary entry for teammate: one who is on the same team. This may be good enough for human consumption because we understand the implication of ...on the same team as someone else. But we obviously cannot simply imply data in an NLP database; we must explicitly enter it.
Circular references
When entering data from a landscaping textbook, this text came up:
- Sexual reproductive parts of a plant are those directly involved in the production of seed.
These parts include ... seeds.
So according to this, seeds are directly involved in the production of seeds. (While it is true that a seed can ultimately grow into a plant which has seeds, that is not direct involvement.)
Here's an example from Dictionary.com:
Another:
Duplicate definitions
The definitions of ability at Dictionary.com:
The ability to contain (#1) is the maximum number it can contain (#2).
Learning calculus (#3) is a type of performance (#4).
You could even change the example for #4 to: He has a capacity for learning calculus.
Missing meanings
The entry for shaft at Dictionary.com does not include a definition which would encompass the meaning of shaft as in mine shaft even though some of its examples from web usage include the words mine shaft.
Combining different meanings into one definition
This is the opposite of duplicate definitions (above). Here is Dictionary.com's definition of abhor:
- to regard with extreme repugnance or aversion; detest utterly; loathe; abominate.
Every dictionary I've seen has similar definitions which combine the idea of being repulsed by something and of hating something. Since you can be repulsed by something without hating it and you can hate something without being repulsed by it, my opinion is that these should be in alternative definitions, not combined into the same one.
Attributing meaning to the wrong words
The following are different definitions for the word of, each followed by an example (from dictionary.com):
It's not of in these definitions which indicates anything, but the other words. A definition which fits all of these is --
of links words to what they apply.
Example of faulty definitions:
Following are the Dictionary.com definitions of any:
Definition 1 is internally redundant, starting with one and repeating one or....
The words specification and identification are also redundant.
Definition 2 means the same thing as #1. Using whatever in #1's examples shows that:
Produce whatever witnesses you have. Pick out whichever six you like.
Definition 3's whatever quantity means the same as one or more.
Definition 4's example uses schoolboys as a set and any refers to an element of the set.
In Def.1, witnesses is a set and, again, any refers to an element of the set.
In Def.1's second example, things you like is a set from which any six elements are selected.
So any by each of these definitions is one or more elements of a set. AIC uses the definition:
any [relates to elements of a set] is {one or more} and nonspecific.
Need any more examples? Oh, wait. any more is defined in every dictionary I've seen as any longer; in other words, it's related to time. But at the start of this paragraph, it's related to quantity, which is never mentioned in any dictionary.
Good Definitions Are Not a Slam Dunk
While trying to enter a definition of the term dunk (the basketball play), I was not happy with my definition: dunk - slam ball into basket from above the rim. In particular, I did not like the use of the word slam.
I first looked in Wiktionary: To put the ball directly downward through the hoop while grabbing onto the rim with power.
Next I checked Dictionary.com: to attempt to thrust (a ball) through the basket using a dunk shot.
And
dunk shot - a shot in which a player near the basket jumps with the ball and thrusts it through the basket with one hand or both hands held above the rim.
Differences in different sources and common usage:
I frequently verify definitions by looking at multiple sources. The problem is that many times the definitions do not concur. In addition, languages are constantly changing and definitions which are currently widely accepted are sometimes not the same as what is in dictionaries.
Arbor is an example.
- Dictionary.com has as one definition a tree.
Wiktionary.org says: a grove of trees.
So which of these (or both) should AI-C have as a definition?
Dictionary.com has as another definition: a leafy, shady recess formed by tree branches, shrubs, etc. Saying leafy is confusing (it's the tree branches which are leafy), A more correct statement is a shady recess formed by leafy tree branches...
Another problem for us is their use of etc. which is not something that can be used in a knowledge base. We must spell out what the "etc." stands for, such as other vegetation or whatever is meant here, as done next:
Wiktionary.org says: A shady sitting place, usually in a park or garden, and usually surrounded by climbing shrubs or vines and other vegetation.
As a Master Gardner for many years, I never heard the term "climbing shrubs". Possible they meant "shrubs or climbing vines".
Neither source describes an arbor as being something hand built rather than naturally growing.
Wikipedia.org routes a search for arbor to pergola and says A pergola, arbor, or arbour is a garden feature forming a shaded walkway, passageway, or sitting area of vertical posts or pillars that usually support cross-beams and a sturdy open lattice, often upon which woody vines are trained.
A search of Google Images shows pictures of hand-built structures and not a single naturally occurring garden area. Googling for arbor versus pergola brings up pages which say that both arbors and pergolas are free-standing garden structures which usually support vines and that the difference between them is one of size and complexity.
An arbor is smaller and is usually used at the entrance to an area while a pergola is larger and more substantial and is often used to provide shade over a patio or pathway.
So Wikipedia appears to be closer to common usage today although it uses the terms interchangeably which is not common usage. AI-C is going with the common usage.
Lack of agreed-upon meanings:
Similar to the previous section, some words/phrases actually have no precise, agreed-upon definition.
A 6/2/2014 newspaper article says that the currently popular craze clean eating "has no agreed-upon definition."
This provides another challenge to entering the meanings of words into AI-C.
Context-Sensitive Spell Checking
Context-sensitive spell checking has a lot in common with the kind of analysis needed for NLP.
Here is a very helpful document.
Why AI-C is free
Berners-Lee, inventor of the World Wide Web, made a very conscious decision to make the Web an open-source project. He said:
Had the WWW been proprietary, and in my total control, it would probably not have taken off. The decision to make the Web an open system was necessary for it to be universal. You can't propose that something be a universal space and at the same time keep control of it.
I only recently came across the above quote, so it was not my motivation for making AI-C free, but the rationale is the same.
Context-sensitive text
When trying to understand submitted text, we analyze all the words to see what they have in common in order to pick the meaning for each word which fits in best with the others. This can also be used for such things as context-sensitive grammar/spelling checkers.
For example, loose is the correct spelling of an actual word, such as in: A screw was loose. However, it is frequently misused in place of lose in writings on the Internet, such as in: I didn't loose any sleep over it. (Microsoft Word does not catch this as a grammatical error even though didn't must be followed by a verb and loose is an adjective.)
Wikipedia shows this poem to illustrate the problem:
-
Eye have a spelling chequer,
It came with my Pea Sea.
It plane lee marks four my revue
Miss Steaks I can knot sea.
Eye strike the quays and type a whirred
And weight four it two say
Weather eye am write oar wrong
It tells me straight a weigh.
Eye ran this poem threw it,
Your shore real glad two no.
Its vary polished in its weigh.
My chequer tolled me sew.
A chequer is a bless thing,
It freeze yew lodes of thyme.
It helps me right all stiles of righting,
And aides me when eye rime.
Each frays come posed up on my screen
Eye trussed too bee a joule.
The chequer pours o'er every word
Two cheque sum spelling rule.
AI-C has the potential to resolve such problems because AI-C stores the pronunciation for each word. Since chequer and checker (chek�EHr), revue and review (ri-vYEW�), threw and through (thrEW), etc., all have identical pronunciations, we can swap out such words until we find a set of words which fit together.
The first line actually makes it easy since there is a spelling checker but not a spelling chequer. Eye have is an easy change to I have since a person may have a spelling checker but eyes do not. A spelling checker is a function of computer software and is related to writing, so this guides our analysis of the rest of the text.
Question Words
Pronouns: who, what, where, when, how.
Verbs: is/are, shall, do/does/did/will, can, could, should, would, may, might, have/had
A sentence starting with one of the above is usually a question.
Pronoun question words are followed by a verb ("Who is...")
A verb question word is normally followed by a noun or pronoun.
If a question starts with a word other than those above, it is normally because one of the question verbs is assumed, such as [Have you] Read any good books lately?
Eye Dialect
Eye dialect is spelling a word the way it is pronounced. It is usually done in fiction to indicate that the speaker is uneducated (would not know how to spell the word) or is just stupid. Here is an example from Oliver Twist:
| "That�s acause they damped the straw afore they lit it in the chimbley to make �em come down again," said Gamfield; "that�s all smoke, and no blaze; vereas smoke ain�t o� no use at all in making a boy come down, for it only sinds him to sleep, and that's wot he likes. Boys is wery obstinit, and wery lazy, Gen'l'men, and there�s nothink like a good hot blaze to make 'em come down vith a run. It's humane too, gen'l'men, acause, even if they�ve stuck in the chimbley, roasting their feet makes �em struggle to hextricate theirselves." |
Humans don't have a lot of trouble reading the above, so for NLP purposes, this makes a good challenge - to see if NLP programs can read it as well.
Here is my ideas about how the human brain processes the above text:
Brain Cortex components
At one time it was thought that neurons did all the communication in the cortex. Then it was determined that astrocytes (see Wikipedia) plays a role. More recently (11/2010), microglia has been recognized as working with neurons. (See this article.) Perhaps most interesting is that microglia are seen to perform in one way when the lights were off and another way when they were on.
How the brain stores words
I've read books and scoured the Internet looking for authoritative information about how the brain processes and stores words, but the results can best be summarized by this quote from www.ling.upenn.edu:
- Very little of what we know about mental processing of speech and language can be translated with confidence into talk about the brain. At the same time, very little of what we know about the neurology of language can now be expressed coherently in terms of what we know about mental processing of language.
The most respected experts in the field, from Chomsky to Steven Pinker, debate theories on the subject based on inferences from how language has evolved, how children acquire language, how what happens to the speaking of people who have suffered brain injuries, but only incidentally based on brain neurology.
Steven Pinker has what may be the best summary of how the brain does it in his book Words and Rules in which he discusses whether word forms (e.g.: plural and past tense) are stored as individual words or are created on the fly by "rules" in the brain that say when to add "s" or "ed".
- The Sylvian fissure [of the brain] anchors the major language areas. Above the fissure toward the front lies Broca's area, thought to be involved in the planning of speech, in verbal short-term memory, and in the comprehension of complex sentences. Below the fissure toward the rear lies Wernicke's area, thought to be involved in connecting the sounds of words with their meanings, with the meanings of words of different categories (colors, animals, tools, and so on) concentrated in different parts. The division of language into a front part for grammar and speech planning and a back part for words and speech understanding is surely too simple. There are hints, for example, that some verb meanings have links to the front lobes, and that understanding sentences with subtle syntax may involve the anterior superior part of the temporal brain.
The purpose of Pinker's book is to convince readers that inflected forms (-s, -ed, -ing) of regular nouns and verbs are not stored in the brain, but are computed by "rules" when needed, while irregular forms are stored in the brain like their stems are.
The closest I've seen anywhere to the actual neurological functioning in this process is Pinker's account of an experiment which showed that in generating the past tense form of a verb, the left temporal-parietal region of the brain is active where the word stem is recognized and memory is searched for any irregular forms. Then for regular verbs and only regular verbs, the activity shifts to the left frontal lobe, where the suffixing operation is carried out.
But this only scratches the neurological surface. I was taught in my youth (a long time ago) that words are stored in one part of the brain, and only brought out when needed for communication.
That is, once you hear or read a word, the brain locates it in the appropriate memory area and from there links it into general memory which contain an amalgamation of links to other memories and ultimately back to sounds, visual memories (including printed words), and other senses.
I still believed this when I started AI-C and decided that words should be relegated to a separate table and that AI-C's "cortex" should contain only links, as I thought was true of the human cortex. I didn't give much thought to the fact that we receive words in different forms: sound, images, and even touch (braille, obviously, but also tracing the outline of embossed or carved letters with your finger).
How and where are these different word formats stored? How (or do) they link to each other, to word meanings, to the letters used to spell them?
The following are the bits and pieces I have been able to find along with recapping of facts which I believe are generally accepted. (Most of this applies to people who can hear.)
1. Sounded out words: Obviously, we learn to recognize and eventually understand spoken words long before we are able to read. These are the sounds found in the Pronunciation table of AI-C (or variations of them). So the first word storage system in the brain has to be for word sounds. Most (if not all) words we first learn to recognize and remember are names of things that we see, so we know that the word sounds are linked in our brains to images in the visual cortex. Soon, we learn non-visual words, such as verbs and adjectives such as "No! Don't touch the stove! Hot!" in which only the word "stove" has a visual representation.
We link word sounds to images, smells, touch, emotions, and to other word sounds and create quite a network of interconnections in our young brains prior to linking them to images of the printed words or the sounds of letters which spell the words.
Next we learn the alphabet by looking at an image of a letter and saying the name of the letter out loud. The name of the letter must be stored as a word sound since to the brain, there is no difference between the name of a letter and the name of anything else. The word sound of a letter must be linked to the image of the letter, just as the word sound bAHl is linked to the image of a ball.
Finally, we learn to read by combining and sounding out the letters in a word. Eventually, we quit reading aloud, but we do what is called subvocalizing. This may involve actually moving the lips as if reading aloud, but normally, no visibly detectable movement of the lips is used.
There is a lot of debate about subvocalizing. Most people say that they hear the words being spoken in their minds as they read, but some people say that they do not read by sounding out words but by recognizing the images of words.
Some deaf people say that they hear a voice in their minds when they read text, despite never having heard a voice.
The book The Psychology of Reading ("TPoR"), by Keith Rayner and Alexander Pollatsek, says that there are three main techniques used to study inner speech:
TPoR says that inner sounding of words
-
...can't be exactly the same as overt speech because we can read silently much faster than we can read aloud. If reading necessitated obtaining the identical acoustic representations as in real speech, then we would read more slowly than we do.
This doesn't make any sense to me. We can read faster silently even while sounding out the words because we do not have the physical mechanics of speech slowing us down. Later on, TPoR says it is possible that the difference between oral and silent reading rates is because a motor response for actually pronouncing each word need not occur in silent reading. It's odd they didn't mention this earlier. Two authors - maybe they disagreed.
Here's an experiment from TPoR to try:
Read one of the following paragraphs, but make sure to hear them being said in your head. Now, at the same time, say "blah-blah-bla" out loud over and over as fast as you can. The result is that you can easily hear the voice in your head while your mouth [and the rest of your speech tract] is fully engaged with something else [proving] that there can be a voice in your head that says at least most of the words you read and furthermore it does not require any involvement of the speech musculature to produce it.
TPoR argues that inner speech aids comprehension while reading by bolstering short-term memory, which TPoR claims is importantly acoustic in nature, making the words available longer while other processes are done, such as working out the syntactic structure of the sentence or holding an easily accessible representation of nouns to search for the referent of a pronoun. I will refer back to this assertion later.
TPoR reports that EMG tests (in which electrodes are inserted into muscles or placed on the surface of speech organs) show increased activity in the speech tract during reading. In contrast, deaf readers [who use signing] show a considerable amount of forearm activity during reading. From this, the authors conclude:
Subvocalization is a normal part of natural silent reading. To our knowledge, there is little controversy about that assertion [addressed later].
Researchers have been able to use feedback training to reduce subvocalization, but the effect was short-lived and began again very soon after the training session. Other tests have found that comprehension of difficult passages suffered when subvocalization was decreased by feedback training.
From http://www.associatedcontent.com/article/72146/my_answer_to_the_question_how_do_deaf.html
I will do my best to describe what it is that I "hear". I believe it is a mixture of several methods of thinking. The strongest one would be how I feel myself talking inside my head. For example, I feel my mouth moving and forming words in my head. Second biggest one would be imagery. I see and feel myself signing inside my head. Last one would be, yes . . . a little voice in my head. I know some people would wonder how can she hear a voice in her head when she doesn't even know what it is like to hear a voice? I honestly can't even explain it, since I don't completely understand it myself either. My closest comparison is that since I grew up taking speech therapy for about five years, I do understand the basic concept of how to speak. It just happens that I am not all that good at it. I also wore hearing aids until I reached the end of seventh grade, and did hear a number of sounds but I never was able to understand what exactly I was hearing. I think that with the help of speech therapy and my experience
s with hearing certain sounds has somehow formed a concept of a voice and how words would sound?
People who think that they recode printed text in images:
http://www.physicsforums.com/showthread.php?p=2921760: It's apparently normal for people to develop their thinking along the lines of language, but some people, myself included, think in pictures, I dunno if other people think in images+feelings though.
http://www.meryl.net/2007/03/30/hearing-words-in-your-head/:
http://www.straightdope.com/columns/read/2486/in-what-language-do-deaf-people-think -- The profoundly, prelingually deaf can and do acquire language; it's just gestural rather than verbal. The sign language most commonly used in the U.S. is American Sign Language, sometimes called Ameslan or just Sign. Those not conversant in Sign may suppose that it's an invented form of communication like Esperanto or Morse code. It's not. It's an independent natural language, evolved by ordinary people and transmitted culturally from one generation to the next. It bears no relationship to English and in some ways is more similar to Chinese--a single highly inflected gesture can convey an entire word or phrase.
the gulf between spoken and visual language is far greater than that between, say, English and Russian. Research suggests that the brain of a native deaf signer is organized differently from that of a hearing person.
http://www.languagehat.com/archives/001054.php
I was born deaf and (swedish) sign language is my primary language, so here's my observations...
Misspellings in sign language during the childhood years exist and are mostly, as joe tomei guessed, due to inadequate muscular control. And then it's usually forming the hand shape that presents the largest difficulty.
As for thinking... that's a complex and interesting question. I do dream in sign language and my parents have mentioned that I sometimes signed vaguely during dreams when I was young. And subvocalizing/subgesturing... I guess I do indeed think in sign then... especially if I'm preparing for a speech, interview or something like that. However, if I'm thinking about how to write something I think in that language(in written form, of course) But as for thinking in general...
As sign language is a bit limited language - there are many words that doesn't have a sign - I think I think in a mixture of gestures and the word I associate with a concept. Sometimes the word is in english, sometimes swedish.
Also I think I actually think the gesture and word at the same time... One thing I'm pretty sure of is that I don't think in fingerspelling when thinking of a word that doesn't have a sign - that'd be too awkward. So I guess I just think of how the word looks like or something like that.. *shrugs*
An interesting phenomenon is how deaf people write. They don't make many misspellings but grammar mistakes are much more prevalent. Especially wrong tenses and sentence structure... Which seem to indicate thinking in sign language. I know that when thinking stuff like "Ouch, this stuff is very difficult" I don't think the word "very" - I use the sign language method of intensifying "difficult"..(hard to explain how that's done without making a mess of it, I'm afraid... but generally we sign the sign faster or slower depending on the concept and also more exaggerated... usually there's a lot of changes on the face expression... more intense)
http://news.ycombinator.net/item?id=1505584:
As a Chinese, now I can think in languages (dual thinking in Mandarin and English), but in the school days I have developed a totally different, alternative way of thinking process.
All Indo-European languages have alphabet to represent syllables, but Chinese is not a language (Mandarin, Cantonese are languages), it's a distinctively unique writing system. Why unique? Its logograms/logographs are not directly linked with phonemes but linked with the meaning itself.
When I do thinking and reasoning, I recall a concept by the word's exact character shape and structure, then match with the picture of book pages I memorized, identify the corresponding semantics and then organize my result. This is way faster than thinking in languages like a background voice speaking in my head.
Elementary education in China has a technique called ??, which means read without speaking, after we learned this, later we were taught to get rid of "read" altogether. We only scan the picture of one book page, and cache it as a static picture, then a question is raised about a particular word appeared in that page. We are demanded to recite the context out. This is called memorize-before-comprehend. After decades of training and harsh tests like this, we were totally used to treat thinking as pattern extracting from lines of sentences.
This is why Chinese find English grammar funny, a noun is a noun, it should be a static notation of things, easily recognizable universally, why the hell do people invent stuff like plural form to make obstacles for recognizing?
Human voices spectrum are way smaller than visual spectrum. And our brain is faster and more optimized at processing mass volume visual stuff(especially pattern recognition), does anyone else think in pictures?
Heh, you sound like my girlfriend. She has a similar problem in which all letters appear as they do to you with numbers. I've had her sit down and explain what she sees, along with drawing what she sees. She's also the only one she knows that has her type. And she also thinks she's stupid. Btw, she has 4 bachelors, 2 masters, and a phd. Her intellect is through the roof. But because counsellors in her high school had no experience in her learning style, they simply said it was "not applying" or "stupidity" or some such tripe. She also has a photographic and phonophonic memory, so those voices appear in her head telling her how stupid she is. So yes, even as a SO, I understand. And judging from your writing style and comprehension, you're not stupid... Just different. There's a few other things you'd be good at, but those would be best to take private.
G. Mulhern (1993) :
In attempting to account for inferior mathematical attainment among deaf
children of all ages, some researchers have proposed that observed deficits may
be partly the result of an absence of vocalization and subvocalization in the
acquisition and execution of arithmetic by the deaf. When performing mental
arithmetic, hearing children, it is claimed, rely on covert counting mechanisms
based on internalized speech, while their deaf counterparts, due to a lack of
articulatory prowess, are unable to utilize such mechanisms and instead are
forced to adopt other less effective methods based on associative retrieval of
arithmetical facts from long-term memory. The present study sought to throw
light on these assertions. Ten prelingually profoundly deaf 12-13-year-olds, and
10 hearing controls were required to solve the 100 simple addition combinations.
Analysis of response times revealed strong similarities between the two groups,
with all children appearing to employ mechanisms based on covert counting.
I don't believe that the brain tries to work out the spelling of a word every time it hears what it thinks is a new word because it is too busy interpreting what is being said. It just stores the word as sound(s) and only figures out and stores the word's letters if it ever needs to write the word or if it sounds out a word seen in print for the first time and the sounds match stored sounds for a word.
This, along with the fact that when you try to commit a printed word to memory, you sound it out in your mind first, makes me believe that word sounds are the primary link point. Another point is that sounds-meanings links in the brain have been around for eons while writing has only been around for about 5,000 years, so again, it stands to reason that word sounds memory takes priority over written words memory.
People born without hearing cannot sound out words in their minds. It seems likely that sign language memory takes the place of sounds memory in anchoring words in such people. If they cannot sign either, but can read and write, then word memory generally has nothing else to link to (with the exception of images for some words).
http://www.todayifoundout.com/index.php/2010/07/how-deaf-people-think/
http://www.wrongplanet.net/postt92139.html
this quote from Helen Keller is interesting: �Before my teacher came to me, I did not know that I am. I lived in a world that was a no-world. I cannot hope to describe adequately that unconscious, yet conscious time of nothingness. (�) Since I had no power of thought, I did not compare one mental state with another.� Hellen Keller, 1908: quoted by Daniel Dennett, 1991, Consciousness Explained. London, The Penguin Press. pg 227
Another poster:
No way. I read too fast for that, and anyway, my concept of a word is its written form primarily, not necessarily its spoken form. (Mispronunciation is easy that way; misspelling only happens if I've seen the word spelled the wrong way too many times! Hyperlexia ftw )
I tend to think of the way words sound when writing, but I don't actually make any movements. That makes sense; writing is outward bound communication, just like speech, so it makes sense that writing a word would trigger thinking of the sounds associated with it.
I also think of sounds while reading poetry; the sound of poetry is part of the way it's supposed to come across, so to get the sound of it you have to think of how it would be read out loud.
and another poster:
I know exactly how lots of words are spelled, but I only know how to pronounce a few of those I know.
The younger I was, the worse my speech was in that aspect. I couldn't pronounce pronounce correctly and didn't know how to say necessity or reluctantly... though I knew how to spell each of them.
There are still so many words I use in writing without giving it another thought, but I'd never voluntarily use these when talking because I don't know how to pronounce them.
Another:
Hmm... I think I may be the other way on this entirely. I suspect that I have some form of hyperlexia, as my ability to understand and to use the written word outstrips my ability with spoken words by far. I tend to trip over myself and botch up everything I'm trying to say when I speak; saying things unclearly or saying the wrong things altogether. The best I can describe it is actually misrepresenting the written sentence playing in my head. It's as if something literally gets lost in translation, a problem that I do not seem to have in the least when writing. In order to clearly get my points across, I usually need something like 5-10 seconds to visually construct my sentences in my head first and sort through the cobwebs of trying to translate it into oral format, and by then the conversation has already moved on and it's too late to provide input.
When I read, usually I don't hear the words at all, even in my head (unless it's spoken dialogue). Rather, a visual representation of the scene appears in my mind and it gets to the point where I barely recognize the words at all. It's as if I'm feeding the words on the page through a projecting reel that simply plays out a movie of the book in my head. I believe it has something to do with the visual nature of the experience. Processing sounds, both inwardly and outwardly, use up far more of my brainpower than visual tasks, writing vs. speaking in particular, thus leaving me with a lot more ability to think about what I'm going to say.
When imagining single words or phrases in my head, the image of the written word/phrase itself flashes in my mind rather than hearing it aloud. I don't know if anybody else is like this, but trying to read aloud or consciously force myself to experience auditory imagery instead of visual not only cuts the speed at which I can read by about half, it does about the same for my comprehension.
Sounding out words gives you two ways to recognize it -- visual and auditory. You may have heard a word (or its root/stem) before but not seen it in print.
Word image readers should not be able to "get" puns, poetry, etc. They should not be able to understand words spelled in (ironically) "eye dialect".
http://www.techlearning.com/article/5094
[Background:] This is a report of a three-month study of AceReader Pro AceReader helps students become more proficient by:
(1) Reducing Subvocalization, which means pronouncing or saying the words mentally as one reads. This slows down reading rate because one can subvocalize only about as fast as one can talk. The program pushes users to read at higher speeds through pacing techniques. At these higher speeds, it is physically impossible to subvocalize.
(2) Eliminating Regression, which means allowing one�s eyes to wander back to re-read text. -- The program will display or highlight words in a manner that encourages forward-only eye movement. In non-highlight modes, it presents words without the surrounding text being shown at all. This promotes forward-only eye movement since there is no previous text visible.
(3) Reducing Eye Fixation Time -- Reducing the time spent when one�s eyes are focused on a single point.
(4) Expanding Eye Fixation Zone -- Improving one�s ability to read a wider text width than when one�s eyes are focused on a single point.
(5) Increasing Re-Fixation Speed -- Improving one�s ability to reposition the eyes at a rapid rate.
[Almost all of the above statements are contrary to research findings.Her results were not great; probably about what they would have been given any kind of intensive reading tutoring - possibly less.]
photographic memory in the popular sense is probably a myth. But something close to it can be found in some children. Eidetic memory, to use the clinical term, is the ability to recollect an image so vividly that it appears to be real. Typically the child is told to examine but not stare fixedly at an illustration on an easel for 30 seconds. Then the illustration is removed and the kid is asked to look at the empty easel and describe what he sees. Most offer vague recollections of the image, but perhaps one in twelve can describe it in accurate detail for five minutes or more. It's not just a retinal afterimage, either. The image has normal coloration, not an afterimage's complementary colors (blue becomes orange, etc.). The descriptions are in present tense--"I see . . ."--and given without hesitation. Most striking of all, the subject's eyes move around the nonexistent scene as he describes it, as though it were actually there.
Sure, the tests rely on self-report, leading some observers to think the testees were faking it, or at least not exhibiting anything out of the ordinary. Then someone hit on the ingenious notion of decomposing an illustration into two images, each consisting of an apparently meaningless set of lines or dots. One image would be presented for inspection, then taken away and after a few seconds replaced by the other. Those who truly had the gift could combine the two images into the original illustration--objective evidence, it would seem, that eidetic memory really exists.
Eidetic ability fades with age--one investigator guessed that fewer than one in a thousand adults had it. Most eidetikers can't summon the eidetic image once it fades from mind, either. But there are exceptions. In 1970 Psychology Today reported on Elizabeth, a Harvard instructor. Using her right eye, she looked for several minutes at a 100 x 100 grid of apparently random dots--10,000 dots in all. The next day, using her left eye, she looked at a second grid of 100 x 100 dots. She then mentally merged this grid with the remembered one into a 3-D image that most people needed a stereoscopic viewer and both grids to see. Reportedly she could recall eidetic images of a million dots for as much as four hours.
Even eidetikers aren't seeing a truly photographic image, psychologists believe--they just have the ability to organize information with unusual efficiency. Children have the edge, no doubt, because they lack an adult's competing mental clutter. A means of organizing data seems to be the key to all superior memory, eidetic or otherwise. For example, expert chess players can re-create a board position involving two dozen pieces with great precision due to their knowledge of the game. But if the pieces are placed randomly on the board, the expert players' recall is no better than a novice's.
To some extent the ability to remember can be learned, although the result isn't photographic memory but simply improved recall. Even mnemonists, known for impressive feats of memory, enhance their native talent with tricks.
When I am in a test and i try to remember the things i have studied, i trace back to the sheet of paper i was holding when i was studying it and simply remember the image and then the answer pops up because i can see it (in my head). I don't know if it makes sense, but i can't really explain it. I find it odd and an unreliable way to remember things because they don't stay in my mind for long.
I have the same kind of memory. When I try to recall information for a test, i think about the book or notes i studied from and visualize them in my head and think of where the answer was. I'm also good at spelling because I remember what the written word looks like. When I'm studying a different language or trying to say someone's name, I need to see the words written down in order to say them right. I'm also really good with directions. If I drive somewhere once, I can usually remember how to get there again, not by street signs but by visual memory. They need to do more research on this.
I think i have i am in the same shoe as Sali, i mean exactly the same, i recall pictures of what i studied an d the answer just pops into my head, i on't know what the hell that is photographic memory or not, all i know is it helps me and i am happy about it...
It is amazing to me..I can remember 100 phone numbers in my head and I when I study for test I can look at the paper and then It just pops in my head when im taking the test..
I am diffinately in the same baot you guys all i have to do to memorize stuff for example produce codes I memorized 50 in about 12 minutes I looked at the picture of the produce and then the four digit number next to it when I felt I was done I closed my eyes and went down each page as I saw them in my mind This is also how I have learned Foreign lanuages I just see the word and remember the meaning I memorize the vocab or even complete sentences. Are any of you all musically inclined? I am but I suck at Math is that why story problems are so hard because I can't see all the picture clearly? I also memorize through music or certain rythems that I make up in my head any feed back would be great thanks
I have the same kind of memory. When I try to recall information for a test, i think about the book or notes i studied from and visualize them in my head and think of where the answer was. I'm also good at spelling because I remember what the written word looks like. When I'm studying a different language or trying to say someone's name, I need to see the words written down in order to say them right. I'm also really good with directions. If I drive somewhere once, I can usually remember how to get there again, not by street signs but by visual memory.
[From Nelson: I am also good at spelling, but it is not because of being able to picture the word. My wife often asks how words are spelled. When I answer, I do not picture the words spelled out - I just starting spitting out the letters. I suspect that subconsciously, the brain uses its links between the audible and visual memories of the words to get the spellings, traces the visual representations of the letters back to the sounds of each letter and sends the sounds to the vocal output.]
Charles Willington: Photographic memory exists, except in rare cases is imperfect and is difficult to describe to someone without it. Often if you try and memorize something intentionally under pressure the pressure of the attempt to memorize it interferes with doing so, making studying something like this very difficult. I can recall long passages of books I read once years ago, have complete recognition of radio shows I hear again when they are rerun. Often the best success at recalling something is when I don't intentionally try and mememorize something. As opposed to reading and rereading the same page over and over again in effort to force myself to memorize it (as one might do for school), I'm likely to have better recollection if I read it once for pleasure and am asked about it in the future (even if it is many months from now). What is described here as "eidetic memory" is totally different, you don't just picture something in your mind's eye for a few minutes it is burned into it, is always ther
e and under the right circumstances you can recall it exactly as it is. Unless you're the person who can tell the difference, you're only the scientist trying to describe what goes on in an individual's mind. Remembering things in the manners believed as being photogrpahic is something done subconciously. If I'm in the right mindset when I read something I can repicture the page of the book in my mind then read it again (I can do this as far back as stuff I remember reading as a kid). I can tell you what it isn't, it is not perfect, is often subconcious and works worst when you try and pressure yourself to memorize things and seems to work best (at least for me) when not under any pressure to do so. It is not a memory trick done by trying to remember things through little rhymes. It does not get worse with age (at least not yet, I'm 29), just more and more details become piled in, the stuff that was there is not forgotten doesn't become fuzzy but there is more and more stuff you remember. Usually if something
jogs your memory of something you can call up something you didn't know you even remembered (I find this often when hearing parts of rebroadcast radio shows, and often I'll even remember where I was when I first heard the braodast).
No such thing as... http://www.slate.com/id/2140685/
http://en.wikipedia.org/wiki/Eidetic_memory
Further evidence on this skepticism towards the existence of eidetic memories is given by a non-scientific event: The World Memory Championships. This annual competition in different memory disciplines is nearly totally based on visual tasks (9 out of 10 events are displayed visually, the tenth event is presented by audio). Since the champions can win lucrative prizes (the total prize money for the World Memory Championships 2010 is 90,000 US$), it should attract people, who can beat those tests easily by reproducing visual images of the presented material during the recall. But indeed not a single memory champion has ever (the event has taken place since 1990) reported to have an eidetic memory. Instead without a single exception all winners name themselves mnemonists (see below) and rely on using mnemonic strategies, mostly the method of loci.
[Secondly, there is nothing to support the idea that the brain has the ability to store whole, large images as a single unit. Research has shown that images are stored broken down into parts. Even an image of a single letter is stored broken down into parts. This is what allows us to recognize letters in distorted format or in significantly different styles of fonts.]
In pure word deafness, comprehension and repetition of speech are impaired, but reading, writing, and spontaneous speech are preserved. Pure word deafness is distinguished from generalized auditory agnosia by the preserved ability to recognize environmental sounds. We examined a patient with pure word deafness associated with bilateral infarctions of the primary auditory cortex, who could use auditory affective intonation to enhance comprehension. The primary auditory cortex seems to be essential for comprehending speech, but comprehension of nonverbal sounds and affective prosody may be mediated by other cerebral structures such as the auditory association cortex.
Pure word deafness is a rare syndrome in which a patient is unable to comprehend spoken words with otherwise intact speech production and reading abilities. AKA: auditory aphasia, acoustic aphasia. http://medical-dictionary.thefreedictionary.com/Pure+word+deafness
Studies in various mammals (including primates) have repeatedly shown that hearing is not chronically abolished after bilateral ablation of the (primary) auditory cortex
We observed spontaneous deaf behaviour in patient SB, a 22-year-old right-handed man who had suffered from two consecutive strokes, destroying Heschl's gyri and the insulae bilaterally, with lesions extending widely into both superior temporal gyri. SB showed no orienting or startle response to unexpected, sudden sounds, in contrast to the majority of patients with milder impairment cited above. Consequently a diagnosis of cortical deafness was made. Normal function of the auditory periphery to the inferior colliculus was demonstrated with audiological and neurophysiological measurements. SB has no other clinically apparent neurological or neuropsychological deficit, except for severe speech apraxia.
When SB was explicitly instructed to focus his attention solely to audition and to try to detect the onset and offset of sounds, he achieved conscious awareness of these sounds. Galvanic skin responses to sounds were elicited only when SB focused his attention to audition. The purpose of our functional neuroimaging experiment was to identify the neural correlates of volitional selective auditory attention in this patient, and to identify modulatory effects enabling conscious awareness of sound.
At the time of testing, he was fully able to communicate by writing and reading
During the state of listening consciously when the patient was focusing his attention on audition rather than unattended auditory stimulation, we found strong bilateral cortical activations. This network comprised the (pre)frontal cortices [Brodmann areas (BA) 6, 8, 9, 10, 11 and 46] and the middle temporal cortices (BA 22 and 21) bilaterally, as well as the left head of the caudate nucleus, right putamen and thalamus, and the cerebellum bilaterally. In contrast, only two minor foci of significant activation in the right posterior parietal and medial superior frontal regions were found during unattended auditory stimulation compared with the resting condition
The striking clinical phenomenon in our patient was that he was consciously aware of the presence of sounds only when he paid selective and undivided attention to audition. He showed no hearing when not attending, and only under focused attention was his residual hearing preserved. This syndrome has not been described before and may be labelled as `deaf-hearing'. This situation cannot be induced in normal hearing subjects, as auditory perception is automatic and mandatory, and cannot be consciously suppressed.
In healthy human subjects, sustaining attention in the visual domain is associated with right more than left lateral prefrontal and parietal cortex activation and seems to depend on the bilateral prefrontal lobes for the auditory domain. In another recent PET study, the effect of paying attention to audition versus vision was investigated during bimodal stimulation in which top-down auditory attention was found to be associated with activation in the right thalamus. Bilateral prefrontal and temporal cortex activations may therefore be expected during the attentional processing of auditory material.
"As a city carrier, I had a dog that would meet me every day at its house (9:30am) and walk with me til noon, it always went home at noon!"
"city carrier" = "mailman"
"I had a dog..." implies that he owned the dog. He meant: "there was a dog".
Man has always had a system used to measure the rate of change/movement of something. I'll call that system "meti".
At least two changing things are needed to have a system of meti -- something which changes at what we say is a fixed rate which we call a "constant" and another thing whose rate of change can be compared to (measured against) that constant. The constant can be something like the rotation of the earth on its axis or around the sun, the rate of decay of radioactive material, the rate of travel of a particle of light in a vacuum, etc.
Here is a thought experiment: start with a universe which is empty but for 2 particles, A and B.
With no known fixed points in the universe, there is no way to tell if either/both of these particles is/are moving and so there is no way to know if the distance between them changes.
If we were in this universe observing, then we could probably detect movement in relation to ourselves, but in this thought experiment, we are not in the universe. You have to just imagine what things would be like as described.
Since meti is a system of measuring the rate of change of something and no change can be detected, the concept of meti in this new universe is meaningless and thus there is no meti..
Now say that a particle C materializes in the universe and appears to be moving back and forth between A and B. (It could be that C is fixed in space and A and B are moving, in sync, back and forth with C between them, but we have no way of knowing for certain which is the case and it is simpler to assume that it is C which is moving between A and B.) We now have change (the movement of C), but no constant to measure its rate of change against. For all we know, C's travel time is different each trip.
Assume that C always pulses (expands and contracts) 10 times per trip. Say that the start of one pulse to the start of the next is a "cycle". So a cycle is 1/10th of a trip or a trip is 10 cycles, but if a trip starts taking more than 10 cycles, we don't know if C is moving slower or the cycles have speeded up or even if the A and B have moved further apart. To resolve this issue requires enough other changing things in our new universe that we can determine which things change/move at a constant rate and thus can be used to measure the rate of change of other things.
Let's say that for the purpose of establishing meti, we agree that the pulse cycles of C happen at a constant rate. We observe that the trip between A and B always takes 10 cycles. Some billions or trillions of C-trips later, assume that people have evolved and still use meti as a system of measuring change. such as saying that the "meti" it takes to walk a mile is 10 C-trips and 5 C-cycles, or 10.5 C-trips. We can calculate that it would take 21 C-trips to walk two miles.
We can also calculate how many C-trips it takes light to travel from the sun to the earth, and how long (in C-trips) it takes for the moon to circle the earth, for the earth to rotate on its axis and for it to circle the sun.
At this point, it should be easy to see that "meti" is not a "thing". It is system of measurement based on ideas and assumptions. As such, we would not talk about "meti" speeding up or slowing down. Let's say that at some point we realized that the pulsing of C, upon which meti was based, has speeded up since the beginning of this thought-experiment universe. If we knew that to be the case, we would not state that meti had changed but that the rate of change upon which meti had been based had changed. Meti is not a thing.
Nor could we travel backward or forward in "meti" because, again, meti is not something which exists to travel through; "meti" is just the name we have given to the system we use to measure the rate of change of things which actually exist.
There are a lot of things in the universe which change/move at a relatively constant rate. But let's say that we continue to use just the pulsation cycles of "C" as the standard by which the rate of change of all other things is measured. If everything in the universe speeded up, including the C-cycles and C-trips, it would be undetectable to anyone inside the universe since the unit of measure had also changed.
To clarify - say that we used the speed of light in a vacuum as a constant in our meti system of measure and the rate of change of everything in the universe increased, including the speed of light in a vacuum, everything would appear to still be changing at the same rate as always.
But say that for whatever reason, the rate of change of everything on Earth, and only on Earth, speeded up. We would not say that the unit of measure of meti had changed, nor that meti itself had changed. We might say that meti had changed on Earth because that is easier to say than that "the rate of change or movement of everything on Earth had changed", But saying that meti had changed is obviously inaccurate. Yet in this discussion all I have done is mix up the letters of "time" to call it "meti", and when people say that "time" has speeded up or slowed down, nobody considers that an inaccurate statement.
Time Travel
To return to a specific point in the measure of time would mean that, by definition, each particle in the universe must be at its original location in the universe and moving at its original speed, momentum, and direction.
The problem is that there only three ways this could happen, and none of the are possible given the known physics of the universe.
1. The most popular method in movies and novels is in a machine that transports people back to a selected time and date and later returns them to their original time and location.
Since time/meti is a system of measuring the rate of change of things and not a physical thing itself, you cannot travel through it. When people talk about time travel, what they really mean, whether they realize it or not, is returning to the previous location and state of being and momentum of every single particle in the universe.
Using our previous example of a pulsing particle moving between two points: say that with each pulse, C ejects a subparticle which travels away at a right angle to C's direction of travel, and say that C had made 10.5 trips. In the meti system, we would say that 150 C-cycles would have passed and C would be at mid-trip, or point B, and would have sent out 150 subparticles. At 125 C-cycles, C was half way between A and B and moving towards B and had sent out 125 subparticles.
If a C-cycle is the rate at which C pulses and we measure time in C-cycles, there is nothing in the physics of the universe to suggest that C can unpulse, yet to go back in time, C would have to unpulse, and everything else in the universe would have to reverse whatever it had done, including the universe itself having to reverse its expansion. Also, anything that went into a black hole, from which there is theoretically no escape, would have to come back out; super novas would have to unexplode, etc.
Even if that did not defy the laws of the physics of the universe, which it does, and everything in the universe went backwards, there would be no way to detect it because the person hoping to travel back in time would be part of the "everything" that has reversed itself and at some point, he would return to the womb, or short of that, once the reversal stopped, his brain would be as it originally was and any memory of what comes next would have been lost in the reversal.
If the time traveler somehow remained unchanged as the universe reversed everything else around him (and throughout the entire universe), it would have to have some effect on the reversal of change that everything else was going through, yet that is not possible since he would take up space originally used by other particles
2. Multiverses:
Well, if you cannot reverse the changes of every single particle in the universe (including particles which dissipated into nothingness) to travel back in time and then reverse the backward changes to start going forward again, and if you cannot just travel back to our universe as it existed at a specific point in its ever-changing past (which is a fatuous idea in itself since if it is ever-changing, it is a flow, not a series of points, one of which can be travelled to), then that leaves multiverses.
Here is one type of multiverse:
In brief, one aspect of quantum mechanics is that certain observations cannot be predicted absolutely. Instead, there is a range of possible observations each with a different probability. According to the MWI, each of these possible observations corresponds to a different universe. Suppose a die is thrown that contains 6 sides and that the result corresponds to a quantum mechanics observable. All 6 possible ways the die can fall correspond to 6 different universes.
This is typical of the restricted thinking that is usually applied to the concept of multiverses. The problem is not that a different universe exists for each possible outcome of the toss of a die, but that any rule that applies to die faces must apply to every other change taking place at the same time. Even if we limit that to observable changes/motions (which is ego-centric, since why should only OUR observations matter?), there would have to be a separate universe formed for every possible combination of every observable motion that takes place while the die is being thrown - the path the hand takes, the position of the fingers, the precise position of the die, the speed of the toss, how the die strikes the table, and so on.
At every point in that process, a new universe would be instantaneously created - no Big Bang or evolution, just SNAP, there it is.
Meanwhile, there is a virtually infinite combination of other changes taking place in the observable universe, not just where the die is being thrown. Even assuming that an infinite number of universes could, contrary to all laws of physics, be created out of nothing and exactly match the location, motion, and rate of change of every particle in our universe, change and motion are continuous, not discrete points, so the number of parallel universe would also have to flow constantly from ours, even if you want to restrict the creation of each new universe to a "significant" change.
As farfetched as all of this is, if it were somehow true, it then raises the problem of how do you navigate an infinite number of universes to get to the one you want? Also, the question remains of how travelling to an alternative universe gets you to the past. All you could travel to is a point at the same time in an alternative universe because "time" (or more correctly: the changes which time measures) in all the universes keeps moving on.
The bottom line is that if you look at the theories of how to do time travel, it is obvious that the people who generate these theories are so wrapped up in the theories that they have lost track of the fact that time is not a thing, but a system of measuring change.
The idea that time is a "thing" in its own right has become so engrained in our thinking that even physicists have made it the equivalent of space by coining the term spacetime, which (from Wikipedia:) combines space and time into a single continuum. According to certain Euclidean space perceptions, the universe has three dimensions of space and one dimension of time... [and] the observed rate at which time passes for an object depends on the object's velocity relative to the observer and also on the strength of intense gravitational fields, which can slow the passage of time.
The Wikipedia page on Time has a section on "time measurement devices". If time does not exist as a thing, but as a system of measure, then it makes no sense to talk about "measuring a system of measure".
Newton said that time is an absolute and that it flows at the same rate for everyone. Einstein said that time is relative, depending on the location and motion of the observer: "observers in motion relative to one another will measure different elapsed times for the same event."
If time is defined as simply being a system of measure, then it cannot have physical traits of its own. It cannot be absolute, it cannot move, it cannot go faster or slower. All it can do is serve as a system of measuring these traits in other things which DO exist.
The Nature Of Time:
Contrary to conventional wisdom, time is not a dimension. In fact, time
does not, in itself, exist. 'Time' is simply the name we give to one
aspect of the ever-changing relationship between moving objects in the
universe. If nothing moved, there would be no time. Hence 'time travel'
is a meaningless concept. That is pretty much word-for-word ideas I expressed for many years prior to the appearance of this card on TV. (I have "gone back in time" by adding the above to this section on time.)
We can change our measurement of the rate of change of things which forms the basis of "time". Here is an example:
A leap second is an extra second added to compensate for the fact that the orbit of the earth around the sun is actually a tiny fraction of a second longer than 24 hours. "The AWS Management Console and backend systems will NOT implement the leap second. Instead, we will spread the one extra second over a 24-hour period surrounding the leap second by making each second slightly longer," Barr said.
Instead of adding a second on June 30, for 12 hours on each side of the leap second, the company will stretch out each second in AWS clocks to "1+1/86400 seconds of 'real' time", Barr added. The point is that "time" is not really a fixed thing. It's whatever we define it to be for the purpose of measuring the rate of change in things which are real.
"Sounding out" written words can be done by reading the words aloud,
Possibly the first step in trying to figure it out is to look for words in memory which are similar to the new word in whole or in part.
Example: "idiomaticity" is a word I just saw recently for the first time. The word "idiom" is not that rare, and many words end with "atic" and even more with "ity". If a brain is already familiar with these word parts, it will have them linked to their sounds and meanings, so the brain can safely assume that "idiomaticity" is a similarly configured form of "idiom" and can store its spelling like this:
For "theme", the brain can save time/space by linking to a neuron which already links to the letters in "them", even though the words have nothing else in common. Then all it has to do is add a link to "e".The word "thematic", which is an offshoot of "theme", cannot link back to "theme" because of that extra "e", so it too has to link back to "them", then add "atic". But the question is how it knows that a particular neuron has the links to the letters in "them".
It seems more likely that the brain originally links each word's sound back to the letters like this:
It is well established that the brain is a pattern matching machine, so at some point it would notice that the letters t-h-e-m are being linked to multiple words' sounds. It seems likely that the brain consolidates multiple instances of the same pattern. (It would be grossly inefficient not to.) The result would be the diagram above this last one.
Notice that while the spelling can be created from the component words, the sounds often do not carry forward so neatly. Even though "them", "theme", and "thematic" all start with "them", none of them start with the same sound.
Example 2: "frangipani". If you are like me, you won't see any words embedded in "frangipani" which look like they could be the basis of this word. (It is the name of a tree, as well as the name of a perfume made from its flowers.) In fact, the closest word to it is frangipane, which is a cream made from ground almonds, as well as a pastry made from that cream. Another close spelling is frangible, which means "easily broken".
So with nothing to go on (in the brains of most of us) for help in storing this word, the brain must first try to sound out the word by syllables, which might be frang-i-pane (frAEng-i-pAEn) or fran-gi-pane (fran-jEH-pAEn) or fran-gi-pan-e (fran-jEH-pAHn-EE). Let's assume that it settles on "fran-gi-pane" as the most likely. It then stores it as the sound of the word and links that sound to the spelling. If the brain later discovers that a different pronunciation is correct, it will change it at that point.
Steven Pinker says in his book Words and Rules that by using rules to generate the different forms of verbs, nouns, and adjectives, the brain saves "significant" space: The rules for -ed, -s, and -ing cut our mental storage needs to a quarter of what they would be if each form had to be stored separately. He offers no proof or illustration of that claim. Here is how the brain might link to the rules for making the past tense form of a word rather than saving the actual word:
First we'll assume that we have just heard for the first time the word that sounds like dAEs [dace, a made-up word] when someone says: "I dAEs every day." You now have the sound dAEs in memory and you have it linked as being something this person does (hence, dAEs is a verb); however, you do not yet have a spelling for it.
You ask what "dAEs" means and he says "It means to [blah-blah-blah]." You can now link that in memory to the sound "dAEs". It turns out that you took the same action yesterday, so you respond: "Oh yeah. I dAEst yesterday, I just didn't know what it was called."
Where did "dAEst" come from to represent a past occurrence of "dAEs" since you only just learned "dAEs"? Well, your brain undoubtedly compared dAEs to verbs ending with the same AEs sound, such as deface, pace, replace, etc., and discovered that to apply these sounds to past action, they all added a "t" sound, such as "pAEst".
If the word sound had been "plou" (for the word plow), then an examination of similar sounds (coud=cowed, voud=vowed, woud=wowed) would suggest adding a "d" sound to the end, as in "ploud", rather than a "t" as above.
Another "rule" applies to verbs whose sounds end in "t" or "d", in which case the sound "id" is added to the end of the word. Example: in-vIEt (invite) becomes in-vIEt-id.
Though we talk about "rules" in the brain, there is not a block of code or an actual list of rules in the brain saying when to add a "t" sound, a "d" sound, or an "id" sound; instead, it seems most likely that the brain simply does what it does best -- pattern matching -- to figure out what to add.
On page 44, Pinker says: "Speakers of English seem to analyze become as be plus come, even though the meaning of become is not computable from the meaning of be and meaning of come." And since our brains already have came as the past tense of come, our brains also make became the past tense of become.
Well, the problem is that become was not derived from be + come, but from the Old English word becuman. Pinker covers this base by saying it's how "speakers of English seem to analyze". So would they not also analyze welcome as well plus come? Yet we say welcomed, not welcame.
Pinker applies his same analogy to stand - stood and understand - understood. Yet people say that a showoff grandstanded, not grandstood, and the meanings of grand and stand are much more closely related to grandstand than the previous examples were to their components.
He says: "Clearly the perception of an embedded word comes from its spelling: become contains come while succumb doesn't." Yet even an illiterate who doesn't know how to spell will say became, not becomed.
The brain has about 100 billion neurons. Each neuron has on average about 7000 synaptic connections to other neurons. An adult has a total of 100-500 trillion synapses. It is thought that neurons can encode both digital and analog data. Of the approximate 100 billion neurons in the brain, 15-20 billion are in the cortex along with over 60 billion glial cells.
A part of the cerebral cortex called Wernicke's area is thought to be involved in the understanding of written and spoken language. Damage to this area greatly impacts language comprehension while the syntax and delivery of words sounds normal.
Decoding printed/written words most heavily involves the visual cortex, which actually modifies its neural structure to record the bits and pieces of light and darkness which make letters recognizable. Audio and visual input travel from their areas of the cortex to the hippocampus and the medial temporal lobe where their patterns are temporarily stored. When these temporary neural patterns are accessed, the process is reversed, returning the signals back to the audio/visual long-term memory areas of the cortex where they are reinforced.
The audio/visual short-term memory areas are not to be confused with iconic memory which retains sensory input for about one second and is easily disrupted.
Another part of the cerebral cortex called Broca's area is linked to speech production and, it is now believed, to language compreshension. Damage to this area impacts the ability to speak, although functions attributable to both Broca's area and Wernicke's area have been found to continue in some cases by shifting the work into nearby areas of the brain.
People with Broca's aphasia are able to understand what they hear (presumably including internal speech), but are unable to speak or write fluently. This is the opposite of Wernicke's aphasia. Part of Broca's aphasia is difficulty finding the right words.
Studies have found that part of Broca's area known as pars triangularis deals with words whose spelling is not directly related to its sound. For example, have is pronounced with a short "a" while the similar words cave, Dave, pave, rave, save, and wave are all pronounced with a long "a" (AE, in AI-C), according to the Journal Of Cognitive Neuroscience.
Theory has it that word recall works by retrieval of multiple possible matches from which the pars triangularis excludes less appropriate selections based on the meanings of words.
Because words have two very different storage systems in the brain, word retrieval relies on the development of both systems.
Meaning (or Semantic) Storage System: The meanings of words are stored in the brain as a large number of connections and systems of connections among nerve cells. These connections correspond to what we call word associations. For example, when a person is asked �What�s a sparrow?� she might reply, �A sparrow is a bird (category). Like all birds, they fly and sing and ...(actions); they�re not used for food or much of anything except to look at and listen to (use/function); they have a beak and wings and skinny little legs and feet (parts); they are small and grayish and round, with a shrill call (attributes); they make their nests in trees and are found in the following locations in summer ... (location); and when I think about sparrows, I think about my uncle the bird man...(idiosyncratic associations)� The specific details are not so important here; however, the important concept is that word meaning is a set of more or less organized associations that correspond to large numbers of neural connections in the brain. These neural connections can encompass large and distant areas of the brain. Each meaning connection represents one �route� to that word in the brain.
Sound (or Phonologic) Storage System: In order to say a word, we also need to know what sounds go together to make the word. These sounds and their organization are stored in the phonologic storage system of the brain � again, a set of nerve cell connections, but this time not so wide spread in the brain.
www.Suite101.com says:
In the brains of unskilled readers, most of the function for reading takes place in the parieto-temporal lobe, which is the word analysis area. Broca�s area, a part of the brain that controls speech production, assists the parieto-temporal lobe in recognizing written words. These parts of the brain are most active when a child begins to recognize the relationships between spoken language and alphabet letters. The brain undergoes a slow, painstaking process of recognizing letters and identifying the sounds created by the letters, then blending the sounds into a word and finally matching the word to a mentally stored object.
Skilled readers' brains rely mainly upon the occipito-temporal area, which is the long-term storage area for words. The brain creates a visual word form and stores it in this part of the brain. The brain retrieves the image as well as its spelling, pronunciation and meaning from storage when the child sees the word again
Research indicates that reading takes place in the left half of the brain. The left front of the brain controls phonemes, while another area matches the letters to the sounds. Finally the information is sent into long-term storage, where the word is automatically recognized.
Poor readers, the researchers learned, have difficulty accessing this automatic recognition center. They rely almost exclusively on the phoneme center and the mapping center. Each time poor readers see a word, they must puzzle over it, as if they were seeing it for the first time.
Technobabble
The attachment of the nominalizing suffix -ity to adjectival bases ending in -ous, which is attested with forms such as curious-curiosity, capacious-capacity, monstrous-monstrosity. However, -ity cannot be attached to all bases of this type, as evidenced by the IMPOSSIBILITY [emphasis mine] of glorious-gloriosity or furious-furiosity. What is responsible for this limitation on the productivity of -ity?
Here is the above in simple English:
A noun form of some of the adjectives which end in -ous can be created by adding -ity. Examples: curious-curiosity. However, this does not work with all adjectives ending in -ous, such as glorious (gloriosity). This raises the question of why not?
The original text is technobabble, which is very common to books on NLP or linguistics, for some reason. I suspect it is because most, if not all, such books are either textbooks or books otherwise aimed at the education or research market. Using rarely seen jargon, even when simple, common words are perfectly adequate, makes the books sound more scholarly. The problem is that if the brain is wrestling with rarely seen words, it takes away from its analyzing and learning of new information:
Laura-Ann Petitto of Dartmouth College in Hanover, New Hampshire, US, and colleagues asked 12 young adults to imagine spelling a word they heard via headphones. They were then asked to judge whether the same word presented on a screen was correctly spelt.
Each participant was tested on a total of 90 words while lying in a brain-scanning machine. A third of these words had regular, phonetic spelling - such as "blink" - in which their letters corresponded directly to the sounds of the word. Another 30 words had irregular spelling, including the word "yacht", while the remaining 30 were nonsense words, like "shelm". "We wanted to know how words are stored in our mental dictionary," explains Petitto.
The scans revealed that more regions of subjects' brains became active when they heard words with irregular spellings, rather than regular ones. In particular, they showed greater activity in regions such as the inferior frontal gyrus (IFG) - an area believed to store information about word meaning. Another area that showed more activity was one called the supramarginal gyrus (SMG), which helps process printed text.
Back to Word-Formation:
For example, it is often assumed that person nouns ending in -ee (such as employee, nominee) can only be formed with verbs that take an object (employ someone, nominate someone). Such -ee derivatives denote the object of the base verb, i.e. an employee is "someone who is employed," a nominee is "someone who is nominated". However, sometimes even intransitive verbs take -ee (e.g.: escape-escapee, stand-standee). Ideally, one would find an explanation for these strange conditions on the productivity of these affixes.
A further problem that we would like to solve is why some affixes occur with a large number of words, whereas other [affixes] are only attested with a small number of derivatives. What conditions these differences in proliferance?
http://www.akri.org/cognition/hummod.htm
How is all of this knowledge stored and how is it accessed?
There must be some strategy or storage method. Consider the following task.
and now try,
Why is it easier to access information using the initial letter as a key rather than the last letter?
The spelling of words is not stored as reliably as the sounds of words. That's because we hear words a lot more often than we have to spell them, so the sounds get reinforced much more often. Even if we see a word in print, we don't read it one letter at a time. We sound it out to ourselves.
So if someone asks you to name an animal beginning with the letter l or ending with the letter w, you use the same process for either task. You start thinking of the names of different animals. It's easier to look for the first letter because when you think of the names, you have to convert the name sounds to letters, and the first letter comes first (duh). When you think of an animal, such as "antelope", you instantly know it starts with an "a", but to figure out that it ends with "e", you have to work out the spelling all the way to the end of the word.
If I say to think of an animal whose name ends in "w", it's not hard to come up with "cow" because it is a short name for a very common animal. But what fruit has a name ending with "b"?
Iff yue sowned owt thiss sentans tew yoreselph, yoo wil komprehenned it. I don't get his point. The fact that it is laborious to read would, if anything, indicate that we DO use images when we read and that in this case, it is laborious because we do not recognize this text as a stored image and must rely on sounding out each word/syllable. On the other hand, it shows that we do not need word images to recognize words because we CAN sound them out.
When I hear the sound yEW, I think that I can picture the image of the printed word "you", but if I were to see the phonetic spelling of this green vegetable -- brAH-kuh-lEE -- I would not be able to picture the image of the printed word because I'm not sure how it is spelled. (Does it have two c', two l's, both? What are the vowels in it?)
I believe that when I picture an image of a word, what I'm really picturing is what my mind puts together from the letters which I think spells it. To test this, think of a made-up word such as "plith" or "grush" (but make up your own word and don't write it down). Now picture how you think your word is spelled. I don't know about you, but I can picture an image of a made-up word printed out when obviously, I've never really seen the word in print.
I further believe that when we read printed text, we sound out the words in our minds in order to convert the printed spelling to sound chunks which are then sent to our vocal processing system, and when we want to write a word, we convert the sounds we hear in our minds when thinking of what we want to write, then convert those sounds to letters which are sent to our motor cortex to write.
nOO-vAEt (where OO is the sound in book, wolf, pull, etc.)
Is nOO spelled
abbreviate is often misspelled abreviate
Many misspellings result from getting vowels wrong.
Other common errors are related to:
Probably the most consistently misspelled word seen in individuals' posts on the internet is loose (past tense) when lose (present tense) is intended. Example: If I loose my password, how can I log in?
I think it may be because most words ending in -ose, as in hose, pose, rose, and lose, have the sound -OHz, while words ending in -oose, such as caboose, goose, noose, and loose all end in a -EWs sound.
So when we are thinking of the sound lEWz, the words with a sound most closely matching that sound are those ending in When we learn our ABC's, we associate "a" with the sound "AE", but when we learn to read, we sound out the word "cat" as "kat", not "kAEt".
pay, paid, pAEd
At one time several reviews of NLP-related books were shown here, but the reviews were all negative. Instead of all the negativity, here is a link to a fairly positive book review:
The problem with AI/NLP Textbooks
AI/NLP textbooks are attempting to teach how to do something which has never been done. How can any textbook say with certainty "this is the best way to do such-and-such" when there is no possible proof of the claim? The book Natural Language Understanding often discusses some approach to NLP at length and concludes by saying something like: given the current state of research in this area, we can't say if this will work - a very rare honesty.
Another problem with NLP textbooks is that they are usually not based on original research; that is, the author is not someone who has an active NLP project which is well under way. Textbooks are expected to have a lot of references to other people's research, which results in textbooks which espouse the same theories that everyone else is putting forward. (In contrast, the book The Psychology of Reading is full of references to research done by the authors.)
For example, as pointed out above, most NLP projects seem to use the same basic concepts in their knowledge base design (storing definitions in sentences), so NLP textbooks use that standard design as the basis for analyzing and discussing NLP approaches. But if the standard design is flawed, then that means all the NLP analysis and discussion which is based on that design is equally flawed, and I believe that to be the case. Following is an example:
An often stated assertion in English AI/NLP texts is that it is inefficient to store the whole forms for different part of speech ("POS") forms such as (verbs:) walk, walks, walked, walking, (nouns:) car, cars, (adjectives:) hot, hotter, hottest, etc. Instead, they insist that it is more efficient to store the root of a word and add the suffixes as needed.
The flaw in this argument is that it values disk space (needed to store the various forms) more highly than it values the time it takes to analyze words to see if they may be suffixed forms of some other words. In reality, disk space is cheap and processing time is very "expensive" when analyzing deep into branches of possible meanings. Time not spent figuring out if a word is a suffixed form of some other word is time that can be better spent trying to best determine the meanings of the words.
Another problem with not storing whole forms of suffixed words is that if the suffixed words are not in the AI's database, then neither can be the pronunciation, syllabification, and other forms of the words For example, AI-C also stores for each word the Soundex code, the letters in alphabetical order, and the letters in reverse order, which is used for finding specified word endings (including suffixes) without having to go through the entire Words table to look for matching endings.
It's also hard to understand how you would use, say, plural words in sentences (used by other NLP designs) in the database when the plural words aren't in there, such as trying to express "pack of dogs". The proponents of not storing whole forms may have a way around these problems, but it is highly unlikely that the way is anywhere near as efficient as having the whole forms to work with.
The bottom line is that the cost in disk space of storing all word forms is nothing compared to the loss of efficiency from NOT having all word forms stored.
And even more importantly, I have never seen a book or taken a course on NLP which analyzes how knowledge bases should best be designed, yet knowledge bases are the very foundation of NLP! It is pointless to talk about how something in NLP should be done when you have not established the design of the most important tool to be used in doing it.
Overview of online NLP Courses
I have taken online NLP-related courses which had the same flaws as NLP textbooks. The main flaw is that the design and implementation of an NLP database (or knowledge base) is never addressed. Instead, NLP textbooks and courses focus largely on mathematical analysis of text for the purpose of determining which words are most often used together.
Here is the syllabus for one of the courses:
Web Intelligence and Big Data. It seemed promising, based on its syllabus, but was not helpful for me:
Natural Language Processing by Dan Jurafsky and Christopher Manning, authors of a textbook by the same name. (https://class.coursera.org/nlp/lecture)
Logic: Language and Information 1 & 2 (Two separate courses.)
Computational Neuroscience
Introduction to Logic
http://www.kurzweilai.net/neurons-lose-information-at-one-bit-per-second?utm_source=KurzweilAI+Daily+Newsletter&utm_campaign=7b702d886d-UA-946742-1&utm_medium=email
A blended word (also known as portmanteaus) is a single word formed by combining the start of one word with the last part of another.
Many blended words are in the dictionary, but their nature is that people make them up frequently. For example, smog (smoke+fog) is well established but smaze (smoke+haze) is rarely (if ever) seen, and if used, would probably not be understood, so using smaze instead of just saying smoke and haze is just an affectation.
An episode of How I Met Your Mother made a play on turducken with turturkeykey, a turkey stuffed inside a turkey, but this is not a blended word. It is a complete word inside another complete (despite being split) word, like abso-friggin'-lutely. (See temsis in Wikipedia.)
To search for blends of two words, we start with the first two letters of the blended word in word1 and the rest in word2. We look in the Words table Text field for words starting with word1 letters and in the Backwards field for words ending with the word2 letters. Then we keep repeating the process, advancing one letter at a time (e.g.: first 3 letters in word1, then first 4 letters, etc.).
A blended word could have many possible matches. brunch could be break+lunch, brow+hunch, etc. Over 1000 words in AI-C start with br and about 20 end with unch. That's a lot of possible word combinations. Even a blend like affluenza, which is af with only one possible match, influenza, has to deal with a lot of words starting with af. On the flip side, it could be a word starting with affluen, which leaves a lot of words ending with za, or any combination inbetween, such as aff + luenza, affl + uenza, etc.
So the biggest problem with blended words is that there could be thousands of possible combinations and which combo is correct is wholly dependent upon the person who invented the blend. This means that until and unless a word becomes widely used, it must be accompanied by an explanation whenever used, which seems to defeat the point of combining two words into one, unless the point is solely an attempt to be clever, cool, etc.
Whatever the reason, it just seems a waste of time to try to analyze a word to see if it is a blend. Established blended words, such as carjack and motel, which are in dictionaries and commonly used, don't need analysis, and the words which are not commonly accepted and are not accompanied by an explanation are too ambiguous, as we have already seen.
Photographic (eidetic) memory:
[Input from indiviuals:] http://www.exforsys.com/career-center/memory-skills/photographic-memory.html
[Nelson: The idea that a person can recall exactly the images of any page they've ever seen seems unlikely. The brain's memory, while vast, is limited, and a complete image of a single page would take up a lot of space in memory.
http://www.neurology.org/content/34/3/347.abstract: Pure Word Deafness:
http://brain.oxfordjournals.org/content/105/2/271.extract
http://brain.oxfordjournals.org/content/123/3/532.full
[Any chess player rated as Expert or higher is most likely able to play "blindfold" chess, in which a game is played without viewing a physical board.]
The visuospatial sketchpad is assumed to hold information about what we see. It is used in the temporary storage and manipulation of spatial and visual information, such as remembering shapes and colours, or the location or speed of objects in space. It is also involved in tasks which involve planning of spatial movements, like planning one's way through a complex building. The visuospatial sketchpad can be divided into separate visual, spatial and possibly kinaesthetic (movement) components. It is principally represented within the right hemisphere of the brain
http://brain.oxfordjournals.org/content/123/3/532.full
The way people write is a problem for NLU:
Time
I was amazed when at the end of an episode of Two and a Half Men on TV, the producer, Chuck Lorre, displayed this on his "vanity card" (a screen at the end of a show where he typically writes something humorous). This card was actually written by Lee Aronshon, co-creator of the show:
1. Written input: Most people learn to read by sounding out words and reading
people to sound it out and mainly remember the sounds while still retaining the visual image to a lesser extent, or remembers the visual image without sounding out the word.
(letters of the alphabet) (letters of the alphabet)
| | | | | | | | | | | | | | | | | | | | |
i d i o m | | | | | | | t h e m e | | | |
| | | | | | | | | | | | | | | | | | | | |
(1)--------- a t i c | | | (1)------- | a t i c
| ------- i t y | | | -------
| | | | | | | | |
(2)-------- ----- | ---|-----
| | (2)------ |
----------- |
| (3)
(3)
(1) idiom (1) them (THem)
(2) idiomatic (2) theme (thEEm)
(3) idiomaticity (3) thematic (thi-mat-ik)
t h e m e a t i c
----- ----- ----- ----- ----- ----- ----- ----- -----
| | | | | | | | | | | | | | | | |
(1)| |(1)| |(1)| |(1)| | | | | | |
(2)| (2)| (2)| (2)| (2) | | | |
(3) (3) (3) (3) (3) (3) (3) (3)
Sounds:
(1) them
(2) theme
(3) thematic
3. Image input: Some words can be linked in the brain to images which represent the words. Other words, such as "idiomatic" or "theme" would be difficult to represent as images and would not have an image link to words.
Rules vs Words
How letters and words are stored in the brain:
From http://www.projectlearnet.org/tutorials/word_retrieval_problems.html:
The occipital lobe's main function is vision. Retinal sensors send signals to the visual cortex (via the optic tract to the lateral geniculate nucleus) where it is organized and sent to the ventral stream for recognition and representation, and then on to other areas of the brain for processing. The primary visual cortex has about 140 million neurons in each hemisphere of the brain.
Starring Word-Formation In English by Ingo Plag
Another typical problem with many postulated word-formation rules is that they are often formulated in such a way that they prohibit formations that are nevertheless attested. [Not only is this more technobabble, but the use of formation, formulated, and formation one after the other is not good composition. This is rarely, if ever excusable, and even less so in a book on linguistics.]
One way to show that we do not normally use the image of sounds when we read is to see how laborious it is to read the following:
Sound to print:noo as in nook
neu as in neuron or
pneu as is pneumonia
Misspellings:
The pronunciation is EH-brEE-vEE-AEt
Notice that the sound has a single "b", which may be why some people drop a b when spelling it. OTOH, they often double a consonant when it should be single, which may be a case of overcompensating.
random observations:
say, said, sed
make, made, mAEd
When we read and sound out the words in our minds, my feeling is that we sound out each word individually, but when we speak the same words out loud, we run word sounds together.
The great majority of non-typo spelling errors are related to:
Reviews of NLP-Related Books
Blended Words
Examples:
Example of a 3-word blend:
turducken = turkey + duck + chicken
(chicken stuffed into duck stuffed into turkey.)
brunch is actually a 3-word blend because breakfast is a blend of break and fast.
AI/NLP Related Web Links and Books
- You must be on the web to use the links.
- bestfest_america is a film festival
- hair_tree_porcupine is a mammal
- the companies news and drudge report compete with eachother [sic]
- tim_sullivan is a journalist that writes for the publication san_diego_union_tribune
- english is a language used in the university newcastle_university
- elton_john collaborates with john
- Probably none of these items will be of general use.
- Item 6 is completely useless.
- Item 3 is also of questionable value. (Is there really a company named news?)
- Items 2 and 5 illustrate one of the drawbacks of not having a proper foundation.
Oddly, searches on Google and in Wikipedia do not turn up a "hair tree porcupine", but here is how the entries for the bahia porcupine would be structured in AI-C:- porcupine is a type of mammal
- New World porcupine is a type of porcupine
- bahia is a type of New World porcupine
The advantage of this approach is that the bahia, streaked dwarf, hairy dwarf, Roosmalen's Dwarf, etc., can each be linked to New World porcupine, and they automatically inherit the characteristics of the links above it as well as being automatically differentiated from the Old World porcupines.
Likewise, Newcastle University would be linked up the tree to universities in England, one trait of which is that English is spoken at them. It would be unnecessary to link each common trait to each individual university in England as it appears NELL would do.
- contact_community is a convention
- the_god_committee_tickets is a geopolitical_entity that is an organization
- ga_aquarium is a zoo
- viagr_viagra_buy si a muscle
- _tennis_magazine is an organization dissolved at the date april
and so on. - Getting input from random passers-by does not provide full coverage of technical detail. The best way to illustrate this is to enter "aardvark" in OMCS and in AI-C and compare the results. AI-C has dozens of facts while OMCS has four (as of 12/20/2001). Two of those four facts are that an aardvark is a mammal and an aardvark is an animal. Since a mammal is an animal, those two facts are really just one, so they just have 3 facts.
Enter "anatomy" in OMCS and you get directed to "body" and about 20 "facts", including:
- Everybody has a body
- A human has one body [duplication]
- You are likely to find a main artery in a body [just "likely"?]
- You are likely to find an artery in a body [duplication]
- You are likely to find skin in a body [found "in" a body?]
- body has flesh [some senses of flesh = "skin", so... duplication]
- and so on.
None of these facts are connected to each other, meaning that at some point, someone will have to manually interlink all these entries to make whatever sense they can from them. My experience is that if you are going to manually interlink words/concepts, you may as well make the original entries for them rather than deal with all the junk you get from random contributors.
- Apparently, no foundation was laid on which to build up these facts. If definitions and encyclopedia data were first entered for all words, then contributors would have some structure into which they could add to subjects some facts and concepts which are otherwise not easily attainable. (Wikipedia and Wiktionary could supply a foundation.)
If you look up "anatomy" in AI-C, among a lot of different facts, you get this set of interlinked entries:
head <is above/atop> neck <is above/atop> torso <is above/atop> thigh <is above/atop> knee <is above/atop> leg <is above/atop> ankle <is above/atop> foot <is bottom of> superficial_human_anatomy
In AI-C, you get the above set no matter which element of the set you enter. That is, if you enter "head", you will see how it fits in with all the rest. This is in addition to whatever other data is in AI-C linked to "head". In addition, this is only what is called the superficial human anatomy, which is that part of the anatomy visible to the naked eye. In OMCS, what little data there is for anatomy is not organized in any way.
- OMCS only has about 20 fixed categories into which all input must be forced. That number is simply inadequate for the job. AI-C has 20+ categories just under structure alone, and it is not limited to those since more can easily be added.
To illustrate the problems with this, enter "abacus" in OMCS. These four entries currently appear:
- An abacus can count that transaction [? no clue what that means]
- An abacus can still be useful
- An abacus can add a series of numbers [the only really useful "fact"]
- calculating things quickly is for an abacus [??]
Even if a person wanted to put in useful information, such as how an abacus is put together, there is no obvious way to do so. In AI-C, we find
- abascus <structure is> rods <through> balls <across> frame.
These are lists of links to web sites which I have stored in my browser while researching various aspects of AI/NLP.
Only recently (September 2010) did it occur to me to list the links here, so this list only only goes back a few years.
Corpus Collections
- American National Corpus
Big.txt - about 1 million words of old literature
ClueWeb09 Dataset - 1 billion web pages in 10 languages. Data is sent on 1+TB hard drives for a reasonable fee.
Corpus of Contemporary American English
Oxford University spelling corrector test corpus
NLTK Corpus List
NLP Projects
- ConceptNet
CYC
FrameNet
The Freebase home page does not tell you what Freebase is, other than to say that it is An entity graph of people, places and things, built by a community that loves open data. It does have a link under the heading "What is Freebase?"
That page tells you: Freebase is a repository of structured data of more than 12 million entities. An entity is a single person, place, or thing. Freebase connects entities together as a graph. Below that is a link to a video entitled "Welcome To Metaweb", but neither the page nor the video explain what the connection is between Freebase and Metaweb.
Freebase data files can be freely downloaded. I did not download all of them because of their size, but I sampled some and could not easily figure them out, either by examining the files or by reading the related web pages. It appears that Freebase primarily collects facts about, as they say, people, places and things. For example, if you want to know the teams, scores, players, etc., for every NFL football game, Freebase can probably give it to you, but this is a long, long way from being a useful knowledge base for a generalized AI/NLP.
- has a lot in common with AI-C. Differences are that NELL is a product of a team of researchers (and probably students) at Carnegie Mellon University, they are supported by grants from the Defense Advanced Research Projects Agency and Google, and they use a research supercomputing cluster provided by Yahoo. All of this adds up to a huge difference in the amount of money and man-hours going into NELL.
Design-wise:
- The inputs to NELL include (1) an initial ontology defining hundreds of categories (e.g., person, sportsTeam, fruit, emotion) and relations (e.g., playsOnTeam(athlete,sportsTeam), playsInstrument(musician,instrument)) that NELL is expected to read about, and (2) 10 to 15 seed examples of each category and relation. and ...500 million web pages and access to the remainder of the web through search engine APIs.
The goal was to have NELL teach itself without human supervision, though some human supervision has been needed to put it back on the right course when its logic has jumped the track. NELL has been running 24/7 since January 2010.
While this is the general direction I would like to take AI-C, I think that starting by having it read pages from the Web is a mistake. As discussed in this document, it makes more sense to me to start by incorporating dictionary definitions, then expanding into encyclopedia articles. This gives the AI/NLP program a more solid foundation of information.
I think that this sample given on NELL's web site of NELL's recently-learned facts is a good example of the shortcomings of the NELL approach:
Here is what I consider problems indicated by the above:
The above was written in 2010. In March 2015, I revisited the web site again and found this list of "recently-learned facts:"
It doesn't seem like Nell has gained any real intelligence in 5 years, all the money, man-hours, and supercomputers notwithstanding.
OMCS collects input which becomes part of ConceptNet. It collects input from random people on the Internet who sign up to enter "facts". This method of getting input has been used for many AI/NLP projects and so far, has not shown any great results. It suffers from the same problems that are usually found in such projects:
openNLP - collection of open-source NLP projects
It would be wonderful if I could import synonyms, commonsense statements, and "glosses" (brief definitions) of words from existing databases into AI-C. There are many such databases available, but none which have been simple and straightforward enough for my use. I have yet to find any database which is available in a simple text listing.
As far as I have been able to tell, none of them use the simple linking method AI-C does. The following is from WordNet's site:
-
WordNet is a large lexical database of English, developed under the direction of George A. Miller. Nouns, verbs, adjectives and adverbs are grouped into sets of cognitive synonyms (synsets), each expressing a distinct concept. Synsets are interlinked by means of conceptual-semantic and lexical relations. The resulting network of meaningfully related words and concepts can be navigated with the browser. WordNet is also freely and publicly available for download . WordNet's structure makes it a useful tool for computational linguistics and natural language processing.
Here is a start of the data in WordNet:
00001740 29 v 04 breathe 0 take_a_breath 0 respire 0 suspire 3 020 * 00004923 v 0000 * 00004127 v 0000 + 00780628 n 0303 + 03926953 n 0301 + 04088055 n 0105 + 00780628 n 0101 ^ 00004127 v 0103 ^ 00004923 v 0103 $ 00002307 v 0000 $ 00002536 v 0000 ~ 00002536 v 0000 ~ 00002669 v 0000 ~ 00002887 v 0000 ~ 00003726 v 0000 ~ 00003932 v 0000 ~ 00004127 v 0000 ~ 00004923 v 0000 ~ 00006596 v 0000 ~ 00007227 v 0000 ~ 00016718 v 0000 02 + 02 00 + 08 00 | draw air into, and expel out of, the lungs; "I can breathe better when the air is clean"; "The patient is respiring" 00002307 29 v 01 respire 1 004 $ 00001740 v 0000 @ 02047097 v 0000 + 00780628 n 0103 + 00780248 n 0101 01 + 02 00 | undergo the biomedical and metabolic processes of respiration by taking up oxygen and producing carbonmonoxide 00002536 29 v 01 respire 2 002 $ 00001740 v 0000 @ 00001740 v 0000 01 + 02 00 | breathe easily again, as after exertion or anxiety 00002669 29 v 01 choke 0 002 @ 00001740 v 0000 + 13256399 n 0101 01 + 02 00 | breathe with great difficulty, as when experiencing a strong emotion; "She choked with emotion when she spoke about her deceased husband"
The WordNet documentation's description of the above starts with this:
synset_offset lex_filenum ss_type w_cnt word lex_id [word lex_id...] p_cnt [ptr...] [frames...] | gloss
From this it is obvious that the database is not something which can be quickly and easily imported.
See the complete documentation.
As of May 2015, the last Windows version of WordNet was released in 2005. The last online version was released in 2006. It doesn't appear that it is being worked on anymore.
Online Dictionaries, Thesauruses, etc.
- Dictionary.com
MSN Encarta
Thesaurus.com
Urban Dictionary
YourDictionary
Wiktionary
Page of links to dictionaries, etc.
Parsing/Tagging Software
-
Link Grammar Parser
SharpNLP - open source natural language processing tools
Stanford Parser: A statistical parser
Statistical Parsing Of English Sentences
TreeTagger - a language independent part-of-speech tagger
Programming Tools/Info
- The Code Project
- American National Corpus
- 300,000 "words" with lemma, POS, and frequency.
- Lots of common, non-uppercase words with Proper Noun tag.
- Lots of junk "words", maybe 40k-50k good word forms out of 300k entries.
- Usage frequency for different words is not believable;
i.e.: rarely heard words often outrank common words,
but the list can be used to decide which POS of a known word is most likely.
Example -- line:- noun=5088,
- proper noun(?)=273,
- verb (present tense other than 3rd-singular)=80,
- verb (general)=70,
- unknown=22,
- adjective=6.
- lemma for -ing nouns is just the -ing form. Not wrong, but should be noted.
Example: listening < listen for verb, but listening < listening for noun. - The list is in a table in AI-C as AmerNatlCorpus.
- IBM Top 100,000 word list by frequency
Really - how does junk like this make it into any kind of "frequently used" list:- 0872
- user32
- corliss
- 7726
- helpfull
- 7845
- fonction
- meriwether
- agere
- 7542
- newb
- 9605
- bonnier
- enp
- 8483
- gault
- 516129
- 7285
- jayde
- smartmedia
- myocytes
- WordFrequency.Info: 5000-word list free, larger ones for sale.
About Words
-
Determiners
A Linguistic Introduction to English Words - a 300-page book online.
SAMPA - computer readable phonetic alphabet
Word Lists
-
Heterony/(Homophone) Page
Homophones
Kevin's Word List (and dictionary list) Page
Outpost9's list of words, names, etc. (last updated 2006)
Word usage frequency lists
Disappearing NLP efforts
- ThoughtTreasure was a knowledge base. The creator of ThoughtTreasure tried to make it commercial, failed, and gave it up in 2000.
- Center for Cognitive Neuroscience had seminars going strong from 1998 until a cancelled seminar in April 2004, then no more and no explanation.
- How are words stored in memory? (Robert Port, 2007) - 27 pages, $40. This was a great disappointment because this subject is what I was originally looking for. Because this was a recent article, I tried looking for a university web site for Port and found it, along with a list of his articles available for free downloading, including this one.
- The Teachable Language Comprehender (M. Ross Quillian, 1969) -
- An organization of knowledge for problem solving and language comprehension (Chuck Rieger; 1976) - 2k PDF, $36.
- A natural language understander based on a freely associated learned memory net (Sara R. Jordan) - 982k, $34.
Some NLP focus groups and projects just stop. This list documents them in case a question about them arises.
Books
I've done more research online than by reading books, but here are some books I've read or used for reference, mostly since 2000:
Heath's College Handbook of Composition (Elsbree & Bracher)
The Language Instinct (Steven Pinker)
The Merriam-Webster Dictionary of English Usage
On Intelligence (Jeff Hawkins)
Pattern Recognition and Machine Learning (Christopher M. Bishop)
Speech and Language Processing (Daniel Jurafsky & James H. Martin)
Words and Rules (Steven Pinker)
Pronunciation Pairs (Ann Baker)
Master The Basics of English (Jean Yates)
Natural Language Understanding (James Allen)
Understanding Reading (Frank Smith)
The Psychology of Reading (Keith Rayner and Alexander Pollatsek)
Books waiting for me to read:
Mapping The Mind (Rita Carter)
Neuroscience (Dale Purves)
The Human Brain Book (Rita Carter)
Neuroscience: Exploring the Brain (Mark F. Bear)
Computational and Math. Modeling of Neural Systems (Peter Dayan)
Principles of Neural Science (E. Kandel)
Word-Formation in English (Ingo Plag)
Conversations with Neil's Brain: The Neural Nature of Thought and Language (William H. Calvin)
Foundations of Statistical Natural Language Processing (Christopher D. Manning)
Articles I would like to have...
I recently (Nov.2010) started scouring the Internet looking for information about how and where letters and words are stored in the brain and accessed when listening or reading. In the course of this search, I came across several unrelated articles which might (or might not) have useful information related to the approaches I have taken in AI-C.
The problem is that AI professionals don't give away any information for free. The paltry few dollars they might get by charging for a PDF file means more to them than the advancement of AI/NLP. I say "paltry" because some of these articles are over 40 years old and show little or no signs of activities at the download sites I visited. My paying $35+ for each article (not a book -- a single article of less than 15 pages usually) is not going to impact the author's lifestyle, but it will mine if I have to keep popping that much for articles which may turn out not to be that helpful anyway.
Here are some examples:
Paul Allen: The Singularity Isn't Near
Paul Allen, co-founder of Microsoft, wrote the above titled article in Technology Review. Per the title, it asserts that a singularity-level AI is a long way off, though he does say that "we suppose this kind of singularity might one day occur."While I don't disagree with his assertion that it is a long way off, I do disagree with some of the arguments he makes in support of his view.
Allen starts with multiple statements of how AI software needs to be better than it is today, which is no surprise, but then he says:
Building the complex software that would allow the singularity to happen requires us to first have a detailed scientific understanding of how the human brain works that we can use as an architectural guide... we absolutely require a massive acceleration of our scientific progress in understanding every facet of the human brain
This is a remarkable statement similar to saying that to build a jet plane, we must have a detailed scientific understanding of how birds fly.
We must know how billions of parallel neuron interactions can result in human consciousness and original thought.
The problem is that these are nebulous and highly debated concepts, so how can we strive to achieve them? What we need is an understandable, achievable goal. What is it that we hope for singularity AI to do? How about find solutions to the world's problems?
While we have learned a great deal about how to build individual AI systems that do seemingly intelligent things, our systems have always remained brittle -- their performance boundaries are rigidly set by their internal assumptions and defining algorithms, they cannot generalize, and they frequently give nonsensical answers outside of their specific focus areas.
If that is the way AI programs work, it is because that is the way they were designed to work. This doesn't mean that it is impossible, or even that difficult, to design an AI which CAN generalize and whose boundaries are NOT rigidly set.
A computer program that plays excellent chess can't leverage its skill to play other games.
This is a poor example. What other games directly lend themselves to benefitting from a knowledge of chess? I was a tournament chess player in my younger days and I can't think of any.
A better game example would be card games. In the late 1980's, I wrote CardShark Hearts, a Hearts-playing game for windows. After completing it, I decided to write CardShark Spades. I started by copying over many of the subroutines, not just for how to shuffle and deal cards, but how to analyze the trick taking and avoidance potential of suits.
While it's true that I, and not an AI software, copied the code over to "leverage" it into playing Spades, getting AI software to a point where it could do such copying on its own is easily achievable -- so much so that I have always just assumed that such an AI would be able to modify its own code. In fact, that is probably an essential feature.
When I wrote CardShark Hearts, I originally intended to put the game's algorithms into a database so that they could be easily modified by the game to improve them. However, in first writing the game with the algorithms hard-coded into the software, it played such a strong game that it was difficult to beat, thus it seemed pointless to work on an even stronger version.
But I started work on a bridge-playing program. Putting the bidding algorithms into a database seemed essential as bidding is very, very complicated and good players all have their own agreements on what various bids indicate. I eventually finished the basics of the bidding program and it worked, but before I started on the playing part of the software, I got more interested in NLP and thought that it was a better use of my time, so I quit working on the bridge program. The VB code and data files for are still available if anyone is interested in pursuing such a project. See a screen shot of the bidding system set-up/editing program.
The best medical diagnosis programs contain immensely detailed knowledge of the human body but can't deduce that a tightrope walker would have a great sense of balance.
I've stated elsewhere in the AI-C documentation that one advantage a computer has is that it (or we) can write a program specifically to accomplish a task such as playing chess or cards or diagnosing medical problems in a way which is MUCH easier, more reliable, and more efficient than the way our brain has to cobble neurons together to accomplish the same thing.
A fact such as the one about tightrope walkers would certainly be a part of any generalized AI NLP software.
Unfortunately, most of his article builds on the above statements, so there is nothing else to address.
Scherer Typology of Affective States
Emotion: brief organically synchronized ... evaluation of a major event
- angry, sad, joyful, fearful, ashamed, proud, elated
Mood: diffuse non-caused low-intensity long-duration change in subjective feeling
- cheerful, gloomy, irritable, listless, depressed, buoyant
Interpersonal stances: affective stance toward another person in a specific interaction
- friendly, flirtatious, distant, cold, warm, supportive, contemptuous
Attitudes: enduring, affectively colored beliefs, dispositions towards objects or persons
- liking, loving, hating, valuing, desiring
Personality traits: stable personality dispositions and typical behavior tendencies
- nervous, anxious, reckless, morose, hostile, jealous
Sentiment Tokenization
Christopher Potts Sentiment Tokenization: Emoticons:- hat, eyebrows: < >
- eyes: : ; = 8
- nose: -o * '
- mouth: ) ] ( d D p P / : } { |
- eyes: : ; = 8
Look up: Brendan O'Connor twitter tokenizer
Hard-to-classify reviews:
- Perfume review: please wear it at home exclusively and tape the windows shut.
- Dorothy Parker about Katherine Hepburn: She runs the gamut of emotions from A to B.
- Review of straw hats: They are so cheap that you can run them through your horses and put them on your roses.
The point is whether or not an AI could make the distinction that these "reviews" are meant to be humorous, not taken seriously.
Thwarted Expectations and Ordering Effects
Positive words used but ending in a negative conclusion.Sentiment Lexicon
Hatzivassiloglou and McKeown intuition for identifying word polarity
Adjectives with "and" have same polarity ("funny and entertaining")
Those with "but" do not ("honest but unreliable")
Turney Algorithm
Classifying text:
In classifying a word in text which can be one of several different classes, assign a positive value to words related to the target class and a negative value to words related to other classes which the word might be part of.
Example: "fall - noun" can be in the class "accident" or "season (of a year)".
1. "he took a nasty fall when he tripped over a rake"
"tripped" has a strong positive relation to the class "accident" and "nasty" has at least a mild positive relation to "accident".
"rake" has a weak positive relation to the class "season (of a year)" in that you rake leaves in the fall.
In sum, tripped and nasty outweigh rake and the sentence is deemed to be about accidents.
2. "this fall I'm planting daffodils".
"planting" has a positive relation to the class "season (of a year)".
"planting" can also have a relation to "accident" such as "avoid a fall by planting your foot firmly before changing directions", but the former is a stronger relation (by usage frequency) and would indicate that the sentence is about the season.
Hearst's Patterns for extracting IS-A relations:
Y, such as X
such Y as X
X or other Y
X and other Y
Y including X
Y, especially X
Dictionary.Com API
Like so many other NLP-AI resources on the Web, Dictionary.com will give the researcher a taste of their data (via an API) but their terms of agreement for the API prohibit downloading their entire dictionary, so it is of limited value for projects like this one.
polysemous -- a word with related meanings; example: bank is a type of financial institution or a building housing a type of financial institution. Systematic relationship: building & organization (school, hospital) as well as Shakespeare ("Shakespeare wrote..." and "I love Shakespeare" (his works) and plum (tree and fruit).
Antonyms are opposites with respect to one feature of meaning: dark/light, short/long, fast/slow, hot/cold, in/out.
A binary opposition: opposite ends of a scale: long/short, fast/slow.
Reversives (different directions): rise/fall, up/down.
Hyponym: car is a hyponym of vehicle, pear is a hyponym of fruit.
Hypernym: vehicle is a hypernym of car, etc.
synset (synonym set) = near-synonyms
gloss = a definition. Example:
chump = a person who is gullible and easy to take advantage of
These words share the same gloss: chump, fool, gull, mark, patsy, fall guy, sucker, etc.
WordNet Noun Relations:
hypernym = superordinate : breakfast = meal
hyponym = subordinate : meal = breakfast
member meronum = Has-Member : faculty = professor
has-instance = __ = : composer = Bach
instance = __ : Bach = composer
Member Holonym = Member-Of : copilot = crew
part meronym = has-part : table = leg
part holonym = part-of : leg = table
antonym = __ : leader = follower
AI-C uses Links:
breakfast [type of] meal
professor [type of] faculty member
Bach [type of] composer
copilot [type of] crew member or [element of] crew
leg [element of] table or [part of]
leader [antonym of] follower
AI-C doesn't need to record the reverse of each of these because a search for "breakfast" will turn up the link to "meal" and vice versa.
Dekang Lin similarity theorem
sim(A, B) = IC(common(A,B)) / IC(description(A,B))
IC = information content
www.geonames.org = geographical data (population, location, etc.)
Simplifying parsed sentences:
Remove:
- attribution clauses(?): "international observers said Tuesday".
- PPs without named entities: "...increased *to a sustainable number*" (just "increased").
- initial adverbials: "for example, OTOH, as a matter of fact, at this point..."
Mangled spelling:
Here is a lawn mower review taken from the Internet:- I was skeptable that the mower would do what they said in their adds but Since [case is wrong] they said I could try it out and send it back if I was not satified with the way it performed I purchased it.
When it arived I decided to put it to the test as I had an area that was overgrowen with heavey brush and weeds. I was compleatly satiafied with the mower as it went through the heavy brush. I also use it to mow pathes
AIC suggested the correct spelling in either first or second place for every word except "skeptable" (skeptical), which I have since fixed.
Processing Text:
Processing text may be done for two different purposes:
- To analyze statements in order to compare them against statements already in AI-C with an eye towards modifying AI-C (in a learning mode) or furthering a conversation (in a "Turing Test" mode).
- To analyze questions in order to provide answers.
In a learning mode, if input is new and does not match data in AI-C, ask for information needed to integrate the input into the Cortex. If text is being input without an operator present, log the questions to ask an operator later. If analysis cannot be continued without clarification, suspend processing of the current text.
In a conversational mode, only ask for clarification if required to further the conversation.
When adding new words, phrases, meanings, and usage (e.g.: proper tense) to the Cortex table, the confidence in the source can be entered in the Source table and linked to the Cortex entry.
Parsing text:
- Spell check the text and save both the original and corrected text which will be used below:
- Create an array: Word(x, y, z) where x is the number of the word in the text, y is the POS LinkID number, and z is the CortexID for each word's category entry.
Example:
- Word(3, 0, 0) is the 4th word in the article, its 1st POS, and the ID# for its 1st category entry.
- Word(3, 1, 0) is its 2nd POS and that POS's 1st category entry.
- Word(3, 1, 1) is the 2nd category entry for the 2nd POS for the 4th word.
- etc.
- Add each category in the Word array to an array Cat(i, j) where x is the category's CortexID and j is a running total of the number of times the category has appeared.
We want to know which category appears the most in order to determine the main category of the text. For example, if aircraft is the main category, then the text is probably about aircraft. In addition to putting them in an array, keep a counter for each category.
- Word(3, 0, 0) is the cID# for the 1st category for the 3rd word's 1st POS.
and Cat(0, 0) is the 1st category's cID# and the # of times the category has appeared in the text. - Word(3, 0, 1) is the cID# for the 2nd category (index=1) for the 1st POS
and Cat(1,0) is the cID# for the 2nd category, which may or may not be for the same word as Word(3,0,0) - ...
- Word(3, 2, 3) is the cID# for the 4th category (index=3) for the 3rd POS (index=2)
Refinements:
- Look up words to which the current word is a synonym or alternative spelling and repeat the previous steps to get their categories.
- Look up the categories for the current word's categories and add them to the Cat array. For example, if apple is a TypeOf fruit, then add fruit to Cat(), then look up fruit's categories (e.g.: food) and add that to Cat(). It may be desirable to go up several generations of categories in this manner.
- Word(3, 0, 0) is the cID# for the 1st category for the 3rd word's 1st POS.
- Search the Cortex for groups of words in each sentence or sentence segment by putting them into Enter word(s) box and executing LookItUp_Click, then get the entries found from the Links list box.
In particular, look for links for words which indicate which other words should or might come before or after them and the POS's for those words.
If any groups of words are indicated as being idioms, substitute the literal words for the idiomatic phrase in the spell-checked sentence along with their POS's and categories.
Use the entries found to look up the POS ID #'s for each word. Put that POS into an array of Found POS's for each word.
- Try to determine the relationship among words which did not show up in the previous search as being linked. For example, red apple would already be linked in the Cortex, but probably not blue apple. Try to find out (in the text) what caused the apple to be blue. For example, the text might say that something looks like a big blue apple in which case the apple isn't really blue; the object being compared is blue and the apple is similar in size or appearance and might look the same as the other object if the apple were also blue.
Manual extraction of data from a Wikipedia article:
After all common and less common words in the Words table have been defined, the next step is to process articles from Wikipedia. The goal will be to convert the text to Cortex entries using the steps outlined above. In this section, I am manually converting an article to see what steps the program would have to go through.
The aardvark is a medium-sized, burrowing, nocturnal mammal native to Africa.[3]
The numbers in brackets are footnotes and would be ignored. Articles ("the", "a") are ignored.
Word Part of speech Category aardvark noun (type of) mammal is verb: third sing. pres. of "be" medium-sized adjective (relates to) size burrowing adjective digging nocturnal adjective animal mammal noun animal native noun (synonym of) aboriginal adjective to preposition adverb Africa proper noun continent It is the only living species of the order Tubulidentata,[4] although other prehistoric species and genera of Tubulidentata are known.
Word Part of speech Category It pronoun is verb: third sing. pres. of "be" only adjective adverb conjunction living species of order Tubulidentata although other prehistoric species and genera of Tubulidentata are known The aardvark is vaguely pig-like in appearance. Its body is stout with an arched back and is sparsely covered with coarse hairs. The limbs are of moderate length. The front feet have lost the pollex (or 'thumb'), resulting in four toes, while the rear feet have all five toes. Each toe bears a large, robust nail which is somewhat flattened and shovel-like, and appears to be intermediate between a claw and a hoof. The ears, which are very effective,[1] are disproportionately long, and the tail is very thick at the base and gradually tapers. The greatly elongated head is set on a short, thick neck, and the end of the snout bears a disc, which houses the nostrils. The snout resembles an elongated pig snout. The mouth is small and tubular, typical of species that feed on ants and termites. The aardvark has a long, thin, snakelike, protruding tongue (as much as 30 centimetres (12 in) long}[1] and elaborate structures supporting a keen sense of smell.[citation needed] It has short powerful legs and compact claws.[1]
An aardvark's weight is typically between 40 and 65 kilograms (88 and 140 lb). An aardvark's length is usually between 1 and 1.3 metres (3.3 and 4.3 ft), and can reach lengths of 2.2 metres (7 ft 3 in) when its tail (which can be up to 70 centimetres (28 in))[3] is taken into account. It is the largest member of the proposed clade Afroinsectiphilia. The aardvark is pale yellowish-gray in color and often stained reddish-brown by soil. The aardvark's coat is thin, and the animal's primary protection is its tough skin. The aardvark has been known to sleep in a recently excavated ant nest, which also serves as protection from its predators
http://www.apperceptual.com/machine-learning
The following is a response I made in a ZDNet blog about a game-playing AI.
I'm saving it here because the subject comes up fairly often.@matthewlinux:
Computers will *never* be truly intelligent. It is philosophically not possible... Today's computers are just glorified calculators. They just do lots of brute force calculations per second.In addition to my work on AI, I've written several card games (CardShark Spades, Hearts, Bridge). Non-programmers tend to think that a computer card game such as these has a response programmed in for every possible play or bid made by a human opponent.
This idea is ridiculous, of course, for all but the extremely simple types of games.
Virtually all computer games of a strategic nature base their play on general algorithms and analysis. The only difference between this and how humans play is that humans can supplement what they've been taught (or "programmed" to do) with what they learn from experience while most games are not programmed that way, though they certainly could be.
Believing that computers are incapable of also learning from experience is another ridiculous idea, and one which no doubt prompted your statement that computers are completely dependent on the human that programmed them.
All that has to be done is to put the game-playing algorithms into a database instead of hard-coding them into the software, then the program can modify the algorithms based on experience.
I have not done this with Spades and Hearts because the computer can beat people easily enough without that extra trouble, but twenty years ago I did it with Bridge.
And although CardShark Spades for Android does not store algorithms in a database, it has computed the bids it uses for various card holdings by playing millions of games against itself. All I did was take its findings and code them into the game. It bids much better than when I wrote bidding algorithms for CardShark Spades for Windows 25 years ago. In fact, the program has taught me how to bid better.
-------------------
On a related subject, people such as the one to whom I was replying don't understand that there is no real distinction between humans being taught/programmed what to think and do by their parents, schools, friends, etc., and computers being taught/programmed what to think and do.
-------------------
Here's a response to someone claiming that computers cannot deal with ("tolerate") ambiguity:Computers (the hardware) don't tolerate anything. The software written for them is certainly capable of it. Anytime a situation cannot be resolved into a clear choice the AI can be "taught" how to deal with it. Here is an ambiguous situation I had to deal with when writing CardShark Spades regarding whether 2nd to play should finesse (play Queen from Ace-Queen when the King is still out) when a low card in the suit is led:
Say that the player sitting East leads a low Club and South plays the Queen. Should West, holding the King, play it and risk having it overtaken if North has the Ace? South might have played Queen from Queen-Jack to force a higher card, or he may have played Q from AQ hoping that East had led from the King, which creates an ambiguity as to the meaning of South's play.
West can reason that South would not have played Q from AQ because the odds are 2:1 that one of the next two players has the King (as opposed to the leader having it). Since South must not have the Ace and East (playing cutthroat Spades) would have led the Ace if he had it (to avoid possibly getting it trumped later), the only conclusion is that North must have the Ace and thus West should not play the King.
But since South can reason that West would never play the K when South plays the Q (using the reasoning above), thus the odds go back to being in favor of taking the finesse (when South does have AQ) because there is only a 33% chance that North has the King.
But once West figures out that South will play the Q from AQ, then he knows to play the K. But if South knows that West will play the king, then the odds go back to 2:1 against South's Q winning and South should NOT play the Queen... etc., etc.
South breaks this cycle by randomly playing the Q from AQ some of the time and the A the rest of the time, and then the next player (West) is stuck as to whether or not to play the K. To keep from being predictable, West must also randomly play the K some of the time and play low the rest of the time.
Another example of resolving ambiguity is software for categorizing images/pictures, which would seem to be a task with a lot of ambiguity. Does it do it perfectly all the time? No, but the fact software does it at all is an example of AI resolving ambiguities. Humans don't resolve ambiguities perfectly all the time either.
-------------------
An online course titled Logic: Language and Information 2 has a lesson on Free Logic which includes the following quiz:

This quiz followed a discussion of how to deal with fictional things such as Pegasus, a mythological flying horse, versus real horses. The discussion involved the charts shown and the exotic looking formulas.
This is an example of how such things are needed only because nobody has created a sufficiently robust knowledge base for NLP.
With AI-C, we could say:
- Pegasus <type of> horse
where all normal characteristics of horses have been linked to horse, such as
mane <characteristic of> horseThen we could make these additional entries for Pegasus:
- fictional <characteristic of> Pegasus
- wings <characteristic of> Pegasus
- flying <ability of> Pegasus
Then if AI-C is analyzing text and comes across the phrase "Pegasus flew quickly to...", AI-C could look up Pegasus and see that it is a type of horse and thus has a mane, four legs, is a mammal, etc., but that it also is fictional, has wings, and can fly.
AI-C can also look up Phar Lap (a real horse) and see that it is a member of the class horse and has all the characteristics of that class, but in comparing Phar Lap to Pegasus, the program would see that Pegasus is fictional but that Phar Lap is not, that Pegasus can fly and Phar Lap cannot, etc.
No arcane symbols nor complex analysis is needed to retrieve this information.
The following paragraphs are from Flower Gardens in Wikipedia. It's here to use for experimenting with NLU coding.
A flower garden is any garden where flowers are grown for decorative purposes. Because flowers bloom at varying times of the year, and some plants are annual, dying each winter, the design of flower gardens can take into consideration maintaining a sequence of bloom and even of consistent color combinations, through varying seasons.
- A -
- flower - noun or verb or adj.
- garden - noun or verb or adj.
- is - verb (third sing. pres.)
When a verb is reached, stop and analyze the words before it.
garden cannot be a verb or adj before before a verb, so it is a noun.
flower must be a noun when preceded by a, so it is a noun-adjective.
Now search for links of the words flower and garden. - any - pronoun/adj./adv.
- garden - noun/verb/adj.
- where -
- flowers -
- are -
- grown -
- for -
- decorative -
- purposes -
Flower gardens combine plants of different heights, colors, textures, and fragances to create interest and delight the senses. Flower color is an important feature of both the herbaceous border and the mixed border that includes shrubs as well as herbaceous plants, and of bedding-out schemes limited to colorful annuals. Flower gardens are sometimes tied in function to other kinds of gardens, like knot gardens or herb gardens, many herbs also having decorative function, and some decorative flowers being edible.
9/10/2016Punctuation Within Quotes
What we consider "real words", "correct spelling", "good grammar", etc., is based on usage. English is something of a democracy -- eventually, the version of things getting the most usage wins out in the long run over what at some point has been considered correct and proper.
Notice that in the list of quoted words in the previous paragraph, the commas come AFTER the closing quotation marks. This is consider to be incorrect usage, but to paraphrase Charles Dickens: If that is the law, then the law is an ass... an idiot.
If I say At the end of the street was a sign that said "Stop", I am required by "law" to put a period before the closing quote, but the sign did not have a period on it and I am quoting the sign, so this makes no sense whatsoever.
In fact, logic already prevails in the case of sentences which questions or exclamations when the quoted material is not, such as What do you think he meant by "It's late" ? (which, however, raises the question of whether it should be "It's late."?) and Slow down! That speed limit sigh said "55 MPH"!
So I am doing my bit to vote for logical grammar by using the "wrong" form in hopes that if enough people do it, the law will change.
9/12/2016Public Function CvtEyeDialect(runOnWord As String) As String ' I've never done anything with this because it would seem ' ' to be of limited use, but here are some notes: ' ' Convert Eye Dialect syllables/words to actual spelling. ' ' Example: "meen" - the "ee" is pronounced "EE" in Eye ' ' Dialect, so look for a word with the pronunciation of ' ' "mEEn". "papur" - the "a" would be "AE" and the "u" is ' ' usually "EH", so look for "pAEpEHr" in the NoSyls field.' ' ' Eye dialect words & phonetic spellings: ' enuf, speshul, skeer'd, sez, sed, cum, wer, conversashun, operashun, ' knoze, viggillence, tikkit, prise (price), skratch, likker, kin (can), perilus, ' sosieties, wuz, ez (is), bizness ' soots (suits), ' "I maek no boasts uv what my speshel clames air, but I hav dun the party som servis." ' "I hain't got time to notis the growth of Ameriky frum the time when the Mayflowers ' cum over in the Pilgrim and brawt Plymmuth Rock with him, but every skool boy nose ' our kareer has been tremenjis... prase the erly settlers of the Kolonies. Peple ' which hung old wimin..." ' maek - make in spell check ' ' uv - short u sound ("uh") plus v = "of"' ' speshel - special in spell check ' ' clames - in eye dialect, the only two possiblities would ' ' be "klam-es" which doesn't sound like any other ' ' words, or "klAEmz" which has the ending sound ' ' of blames, shames, frames, and *claims*. ' ' air - This is a real problem because if it is pronouned ' ' "AEr" as air normally is, then it doesn't sound ' ' the way "are" is pronunced ("AHr"), plus unlike ' ' most other eye dialect words, "air" is a real word ' ' and would not trigger spell check. The solution for' ' for such words would be to make entries for them ' ' such as: airare ' ' hav - A rule could be to check for silent "e" at the end.' ' dun - short u sound ("uh") plus n ' ' som - e at the end again. ' ' servis - complicating this is that "e" is not pronounced ' ' as a short e. The sound in AI-C is "sEUr'vis". ' ' It could have been written as "survis" but that ' ' would imply a short u and still not sEUr. Another ' ' problem is that "survive" and "service" have the ' ' same starting sound to my ear, online dictionaries ' ' show them with different starting sounds, even ' ' though they don't all agree what those sounds are. ' ' hain't - is unusual for eye dialect because it is not ' ' spelled the way it normally sounds but in the way ' ' it is said in some backwoods dialect (hard "h"). ' ' Same is true of "Ameriky" and "tremenjis". Also ' ' note that the author of the last quote is very ' ' inconsistent in the use of vowels - sometimes ' ' sounding them as long, short, or other. ' ' All of this means a lot of trouble for little payoff. ' ' Time could be better spent on a lot more worthwhile items. End Function Speech "understanding" without an AI-C type knowledge base:
"The BBC provides subtitles on its live broadcasts for the hard of hearing, using specially trained staff who "respeak" the soundtrack (with light on-the-fly editing but as little delay as possible) into ASR software, which then displays its output as an on-screen caption.
You can find plenty of outrageous gaffes online, including the "Chinese Year of the Horse" (2014) becoming "the year of the whores," (the former UK Labour Party leader) "Ed Miliband" becoming "the Ed Miller Band" and the UK government "making helpful decisions" becoming "making holes for surgeons."
The problem is that the software appears to be just be using whatever text is generated by the text-to-speech software without any context. As for "Year of the Horse" -- a decent knowledge base would have have an entry for "Year of the [animal]".
Enter just "Year of the" into Google and it knows what you are talking about. On the other hand, Google apparently adds captions to videos on its Youtube service using speech recognition and the results are often equally laughable.
How We Learned To Talk To Computers
Sept. 2016This article covers the basics of language, speech recognition, neural networks, natural language understanding, speech synthesis, and virtual assistants. However, it does not cover these from the point of view of having a true general AI which is capable of having an intelligent conversation, and the article points this out in its closing sentence:
The bottom line is that AI is developing fast, and we are well on the path to being able to converse with a HAL-like entity.
Being well on the way is debatable because the tools and approaches used to answer queries by looking up data is a long way from having data linked together in the way the brain does.
Even as a look-up tool, the language understanding of search functions on the Internet are consistently bad.
Let's say that I ask a person "Where does Nelson Ford live in Arkansas?" The only sensible answers are:
- I don't know.
- Nelson Ford lives in Hot Springs Village; here is his address (if known) ...
- There's more than one Nelson Ford in Arkansas; here are their addresses.
Here is what I got from Google (in the order listed):
- An article in Wikipedia about Nelson Ford which says he lives in Hot Springs Village - pretty good.
- "Nelson Ford, AR is a crossing located in Saline County at N34.54315� W92.72822� (NAD83)."
Clearly Google did not understand the concept of someone "living" in Arkansas. - A page showing the address of a Nelson Charles Ford in Conway, AR. - full credit for that.
- A Nelson Ford's activities on YouTube, which is not responsive to the question. (Not me, BTW.)
- An article about a baby hawk found in our yard after a wind storm. Again, not responsive.
- A Facebook page for a Ford dealer named Nelson. (Way off target.)
- A couple of pages at www.AR15.com where Google mistook "AR" in the name of the weapon for the abbreviation for Arkanasas.
- Several paid ads for companies wanting to sell me the information.
Since Google understood the question well enough to list the Wikipedia article first and to put several ads on the page for companies willing to answer the question for a fee, why the heck did they put links 2, 4, 5, 6, and 7 on the page?
The same kind of dichotomy exists between the pretty good voice recognition and response to questions done by Amazon's Echo device and the search function on Amazon's web site where you often get a listing in which 90% (or more) of the items are not relevant to your search.
https://github.com/tensorflow/models/tree/master/syntaxnet
How A.I. Should Deal With the Unknown:
Not everything is explained because not everything in life is explained. you get it from context or you do not, and move along.
For me this quote is particularly profound when applied to NLP/NLU even though it came from a simple movie review on Amazon.
We should not expect an A.I. to understand everything. NLP software should be able to deal with the unknown/unknowable by attempting to discuss and resolve the misunderstanding or moving on.
When is a "conversation" not a conversation?
I just discovered via my Amazon Echo/Alexa that Amazon gives tons of money each year as prizes to those who can come up with the A.I. which can best maintain a good conversation. There is a video on YouTube of the 2017 winners.
The problem is that the exchanges shown between the bots and humans are not conversations.
These are bots giving canned responses to directed questions and responses, not too different from what Watson did on Jeopardy nor from the "conversational" humanoid on TV in or about 2017.
The developers/contestants in this video were given topics to prepare for - sports, politics, entertainment, tech, and fashion. Humans ("interactors") were coached not to get into areas which the bots "were not prepared to handle."
The bots asked canned questions, picked out key words, and based on them, gave more canned responses or canned questions.
Here's an example starting at 17:00 in the video -
Bot suggests 3 topics - movies, tech, and fashion.
Human selects fashion.
Bot tells a canned joke about lipstick.
Human changes to politics.
Bot quotes an article related to politics.
21:55 -
Human ask "What do you think about Ronald Reagan?"
Bot quotes canned bio information about RR's early years.
Human: "Do you think Ronald Reagan was a great president?"
Bot quotes a news article regarding North Korea and RR without stating the relevance to the question, much less an answer.One common conversational flaw was that if a bot was not 100% sure that it heard a word correctly, it would say: "I understood that you want to know if...", asking for verification.
A more realistic approach (used by humans) is to assume you heard right (unless your confidence level in that is really low) and continue the conversation, relying on the human to provide clarification or correction if your assumption was wrong.
The following is a discussion of how one small part of the program evolved - the best way to uppercase words.
Entering uppercase forms of words:Every word used by AI-C is recorded in and only in the Words table and its pronunciation(s) and syllabification(s) are stored in those tables. A problem arises when we need to specify forms of these words which have one or more letters uppercased. What's the most efficient way to indicate when a word should be uppercased?
One method is to make an entry for each uppercased form of a word and link it into the Cortex with a LinkID of 30020: proper noun. Any other entries which need to use the uppercase form link to this entry instead of to the lowercased form.
The drawback to this approach is that it essentially doubles the size of the Words table because virtually every word can be used in an uppercased form, such as in the name of a business or the title of a book. And these not only require additional entries in the Words table, but in the Pronunciation and Syllabification tables as well.
ID# WordID1 Entry1 Link Entry2 WordID2 130086 136913: United 138340: united 30020: proper noun 130087 136914: States 138339: states 30020: proper noun 76322 63257: of 30097: preposition 130089 136636: America 30020: proper noun When entries such as the above are used to link words from the Words table into the Cortext, the Entry1 field is used to show the word's root, if any. For example, 138340:united is the root of United because they have the same meaning, but no root is shown for America because it is just the name of something.
Here is a set of entries which use the above entries:
ID# WordID1 Entry1 Link Entry2 132990 4-word phrase 30910: phrase 132991 136913: United 130086: United 30911: part of phrase 132990: United States of America 132992 136914: States 130087: States 30911: part of phrase 132990: United States of America 132993 63257: of 76322: of 30911: part of phrase 132990: United States of America 132994 136636: America 130089: America 30911: part of phrase 132990: United States of America In the above phrase, we could save an entry by first combining United and States as a compound (since United States is often used without of America) and then using that entry in the phrase. However, in it seems more efficient to use individual word entries as discussed here.
An alternative is that when an entry wants the uppercase form or a word, put "(Up)" in the WordID field, just as "(s)" is used to indicate that a word can be singular or plural. For this purpose, a Words table entry has been made for "(Up)" as ID# 136935.
ID# WordID1 Entry1 Link Entry2 WordID2 131111 136935: (Up) 55213: hot compound 138893: dogs 136935: (Up) 131112 Joe's compound 131111 In the entries above, each word is individually capitalized then the owner's name is linked to that entry.
When Word entries have different letter(s) uppercased within the word, like "sweetHeart", there is no choice but to add it as-is to the Words table.
Responding in Kind:
AI-C can classify the type of input it is getting as the following
- slang/informal (link ID# 31018) or more formal (#31050)
- common, uncommon, technical, vulgar, etc. (word frequency fields in Cortex)
- outdated (#31065)
- misspelled (#31015) and/or ungrammatical (#31040) or even eye dialect (#31016)
If it stores information about the source of the input, it can use links "language style" and "language tone" to store the type of input it has received.
It can then use this information to respond on the same level as the input received.
Movies versus A.I.
A.I. does get idioms: It is ridiculous to think that an A.I. which can understand and speak English fluently would not understand any kind of common grouping of words, including idioms.
Why would an A.I. understand "hot dog" to be a type of food and not an overly warm canine, but not understand "it's raining cats and dogs"?
Myths about Luck
Myth 1. Luck evens out in the long run.
Due to the nature of random distribution of cards, there will be long streaks where you get fewer than your share of good hands. There will also be streaks when you get more than your. After awhile, players tend to think that after a long bad streak, luck will even out and they will start getting good hands.
However, this is patently untrue. Take the case of a fair coin fairly flipped. Each flip has a 50-50 chance of coming up heads (or tails). However, it is perfectly possible to get, say, 10 heads in a row.
You would be hard pressed to find a majority of a group of random people who would not believe that "tails are due" or that over the course of the next 1000 flips, tails will routinely overtake that 10 heads lead.
Thanks to the magic of "standard deviation" it is possible for tails to overtake heads lead of 10 in 1000 flips, but the odds are against it.
A person plays the Mega Millions lottery and wins $300 million. It is impossible for the luck of winning the lottery to ever even out among the participants because only a relatively very small number will ever win a lottery, so the other millions and millions of people cannot possibly catch up.
The Physical World versus the Theoretical World
Absolutes:
In a movie whose name I don't remember, a character says "There are no absolutes." to which someone replies "But isn't THAT an absolute?"
The problem with the original statement is that it should be: "In the physical world, there are no absolutes." The reason is that in the physical world, so-called "facts" are based upon observations and logic, both of which are imperfect.
Observation is imperfect because it is limited to what we have already abserved and no matter how invariably something has happened in the past, we cannot be 100% certain that it will not not happen differently some time in the future.
Example:
- For theoretical purposes, the test could be performed infinitely but due to the physical limits of the real world, it is a virtual certainty that the conditions of the test could not be repeated for, say, a million years, much less for a trillion, trillion years.
- Even if the universe, our solar system, and the human race (and decks of cards) did stick around long enough, we can't say with absolute certainty that some heretofore unknown force of nature would cause it not to happen.
Take a used (thus already well mixed) deck of cards, shuffle it thoroughly, and turn each card face up. You would expect to see the cards appear in some random order. But one possible outcome is that the cards would turn up in the order of 2 through Ace and grouped by suits.
The odds of this happening with such a deck are around 1 in 10 to the power 68 (or 1 followed by 68 zeros). That's a huge number, roughly equal to the number of atoms in our galaxy. (The linked site explains how this can happen with a new deck, but here we have specified a well used deck.)
This seems such an unlikely outcome that if this happened, an observer would suspect that the deck was fixed somehow yet this outcome is no less likely than any other one outcome; however, this is unlikely to ever be observed in the situation described because the waiting time (the time required for an event to occur based on the probability of its occurrence) for such an event would be greater than the life expectancy of the human race.
So in theory, we believe that such an event could happen, but in the physical world --
Logic is imperfect because, at best, it is based on so-called "facts" which as we have just seen, cannot be proven in the physical ("real") world to be true. Logic also depends on the proper application and analysis of such "facts" which also creates opportunities for introducing errors.
Infinity:
In the theoretical word, a simple demonstration of "infinite" is that cardinal numbers can be infinitely large because you can always add 1 to whatever you believe to be the largest possible number.
In the physical world, there are limits to how long you can keep adding 1 to a number due to the limited life expectancy of humans and the universe itself.
So while logically, the concept of infinity may be for theoretical purposes, we cannot say that anything can be infinite in the physical world since we are pretty sure that the physical world itself as we know it (much less the human race) will not last infinitely and it is unlikely we will ever know what is beyond the limits of the universe.
So while you can prove that any number can be increase by adding 1 to it, you cannot prove that this can be done infinitely in the physical world, thus infinity cannot be proven to exist in the physical world.
Paradoxes:
Most, if not all, situations we consider paradoxes are not paradoxes in the physical world. One such flaw is to posit something which, like infinity, may seem perfectly logical in the theoretical world but which cannot be proven (and in fact seems unlikely to be possible) in the physical world.
Google "paradox" for more info. A good discussion can be found in Wikipedia.
How This Applies to AI-C:
It is important to identify anything which is theoretical as such. It is also important that AI-C "understands" that what we call facts are ultimately based on observations and thus are subject to being overturned in the future if observations change or even if our understanding of what we have observed changes.
- Pegasus <type of> horse